Our new paper “Towards a Non-Binary View of IPv6 Adoption” will appear at the 2025 ACM Internet Measurement Conference (IMC ’25), being held from October 28-31, 2025 in Madison, WI, USA.
From the abstract:
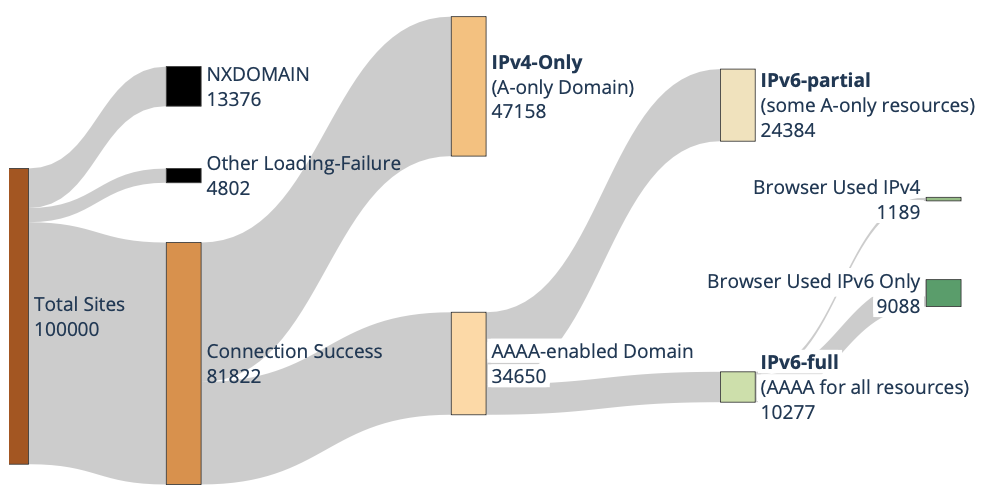
Twelve years have passed since World IPv6 Launch Day, but what is the current state of IPv6 deployment? Prior work has examined IPv6 status as a binary: can a user do any IPv6? As deployment increases, we must consider a more nuanced, non-binary perspective on IPv6: how much and often can a user or a service use IPv6? We consider this question as a client, server, and cloud provider. Considering the client’s perspective, we observe user traffic. We see that the fraction of IPv6 traffic a user sends varies greatly, both across users and day-by-day, with a standard deviation of over 15%. We show this variation occurs for two main reasons. First, IPv6 traffic is primarily human-generated, thus showing diurnal patterns. Second, some services lead with full IPv6 adoption, while others lag with partial or no support, so as users do different things their fraction of IPv6 varies. We look at server-side IPv6 adoption in two ways. First, we expand analysis of web services to examine how many are only partially IPv6 enabled due to their reliance on IPv4-only resources. Our findings reveal that only 12.6% of top 100k websites qualify as fully IPv6-ready. Finally, we examine cloud support for IPv6. Although all clouds and CDNs support IPv6, we find that tenant deployment rates vary significantly across providers. We find that ease of enabling IPv6 in the cloud is correlated with tenant IPv6 adoption rates, and recommend best practices for cloud providers to improve IPv6 adoption. Our results suggest IPv6 deployment is growing, but many services lag, presenting a potential for improvement.
This technical report is a joint work of Sulyab Thottungal Valapu from USC, and John Heidemann from USC/ISI. This work was partially supported by the NSF via the PIMAWAT, BRIPOD, and InternetMap projects.