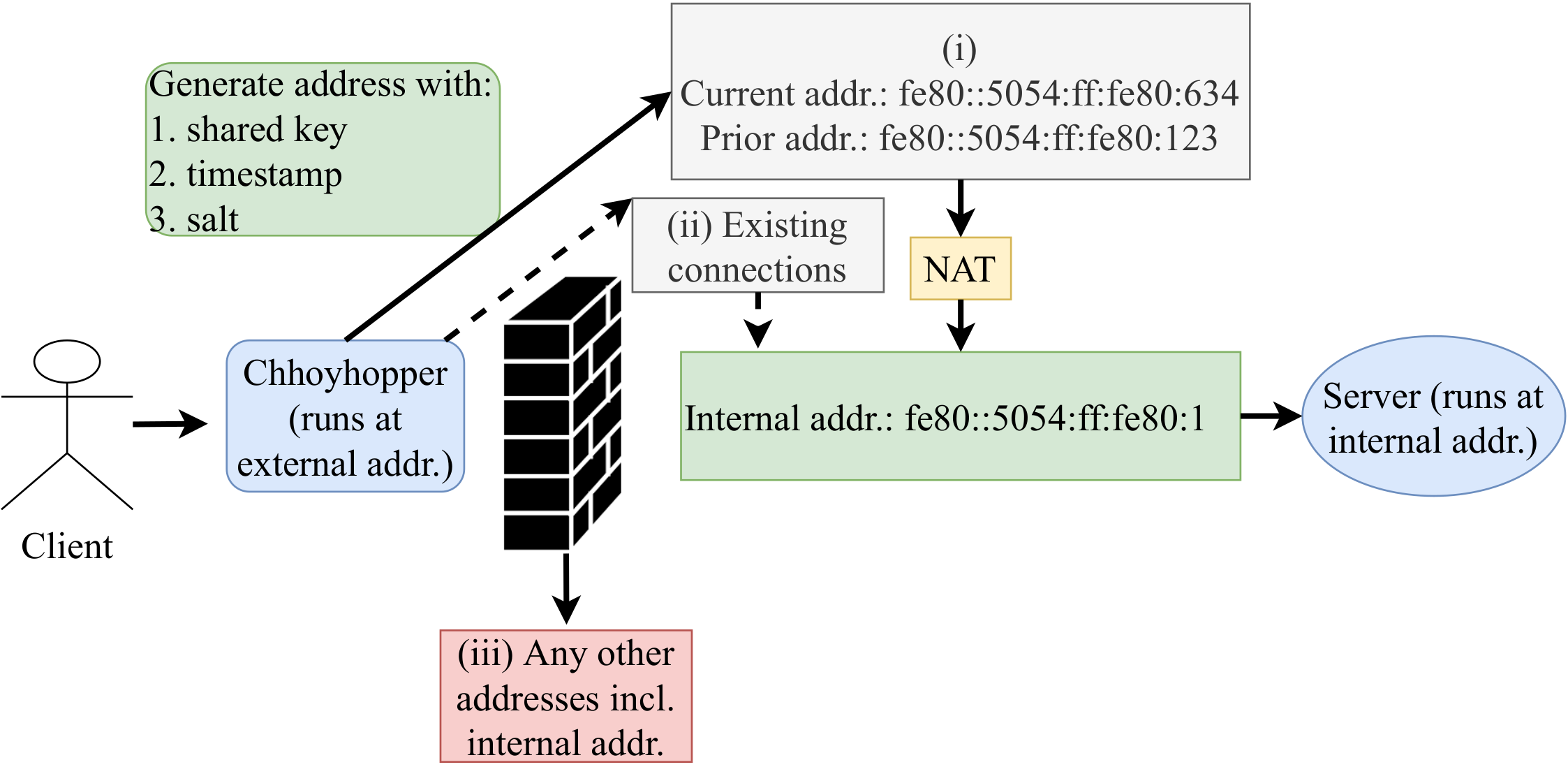
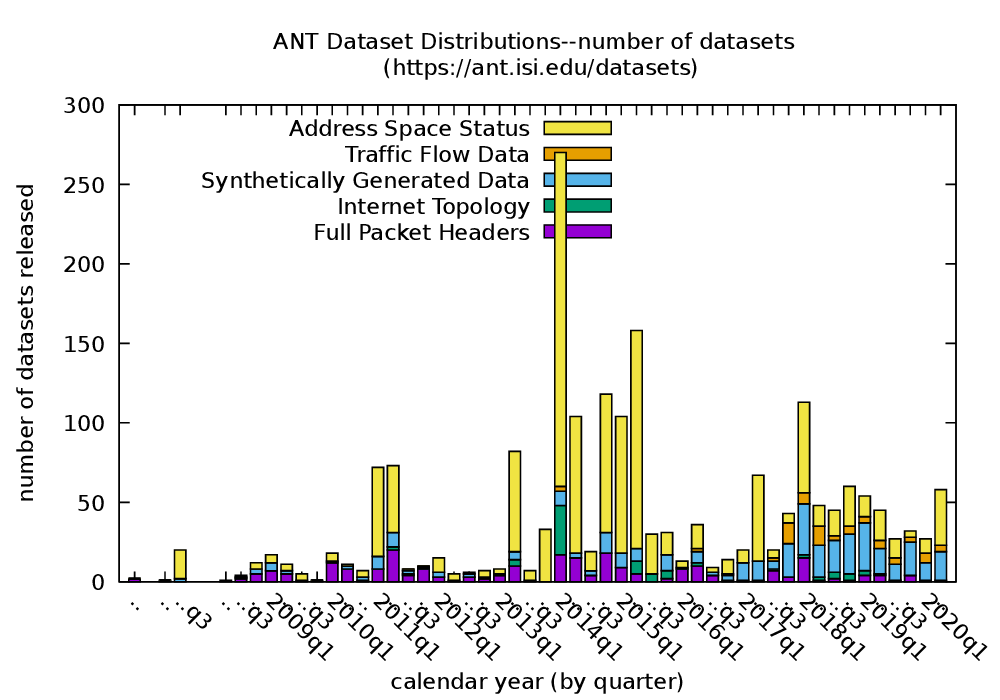
From the SIGCOMM mailing list and Facebook feed, Dina Papagiannaki posted on June 3, 2020:
I hope that everyone in the community is safe. A brief announcement that we have our winner for the networking systems award 2020. The committee comprised of Anja Feldmann (Max-Planck-Institut für Informatik), Srinivasan Keshav (University of Cambridge, chair), and Nick McKeown (Stanford University) have decided to present the award to the ns family of network simulators (ns-1, ns-2, and ns-3). Congratulations to all the contributors!
Description
“ns” is a well-known acronym in networking research, referring to a series of network simulators (ns-1, ns-2, and ns-3) developed over the past twenty five years. ns-1 was developed at Lawrence Berkeley National Laboratory (LBNL) between 1995-97 based on an earlier simulator (REAL, written by S. Keshav). ns-2 was an early open source project, developed in the 1997-2004 timeframe and led by collaborators from USC Information Sciences Institute, LBNL, UC Berkeley, and Xerox PARC. A companion network animator (nam) was also developed during this time [Est00]. Between 2005-08, collaborators from the University of Washington, Inria Sophia Antipolis, Georgia Tech, and INESC TEC significantly rewrote the simulator to create ns-3, which continues today as an active open source project.
All of the ns simulators can be characterized as packet-level, discrete-event network simulators, with which users can build models of computer networks with varying levels of fidelity, in order to conduct performance evaluation studies. The core of all three versions is written in C++, and simulation scripts are written directly in a native programming language: for ns-1, in the Tool Command Language (Tcl), for ns-2, in object-oriented Tcl (OTcl), and for ns-3, in either C++ or Python. ns is a full-stack simulator, with a high degree of abstraction at the physical and application layers, and varying levels of modeling detail between the MAC and transport layers. ns-1 was released with a BSD software license, ns-2 with a collection of licenses later consolidated into a GNU GPLv2-compatible framework, and ns-3 with the GNU GPLv2 license.
ns-3 [Hen08, Ril10] can be viewed as a synthesis of three predecessor tools: yans [Lac06], GTNetS [Ril03], and ns-2 [Bre00]. ns-3 contains extensions to allow distributed execution on parallel processors, real-time scheduling with emulation capabilities for packet exchange with real systems, and a framework to allow C and C++ implementation (application and kernel) code to be compiled for reuse within ns-3 [Taz13]. Although ns-3 can be used as a general-purpose discrete-event simulator, and as a simulator for non-Internet-based networks, by far the most active use centers around Internet-based simulation studies, particularly those using its detailed models of Wi-Fi and 4G LTE systems. The project is now focused on developing models to allow ns-3 to support research and standardization activities involving several aspects of 5G NR, next-generation Wi-Fi, and the IETF Transport Area.
The ns-3-users Google Groups forum has over 9000 members (with several hundred monthly posts), and the developer mailing list contains over 1500 subscribers. Publication counts (as counted annually) in the ACM and IEEE digital libraries, as well as search results in Google Scholar, describing research work using or extending ns-2 and ns-3, continue to increase each year, and usage also appears to be growing within the networking industry and government laboratories. The project’s home page is at https://www.nsnam.org, and software development discussion is conducted on the ns-developers@isi.edu mailing list.
Nominees
The main authors of ns-1 were (in alphabetical order): Kevin Fall, Sally Floyd, Steve McCanne, and Kannan Varadhan.
ns-2 had a larger number of contributors. Space precludes listing all authors, but the following people were leading source code committers to ns-2 (in alphabetical order): Xuan Chen, Kevin Fall, Sally Floyd, Padma Haldar, John Heidemann, Tom Henderson, Polly Huang, K.C. Lan, Steve McCanne, Giao Ngyuen, Venkat Padmanabhan, Yuri Pryadkin, Kannan Varadhan, Ya Xu, and Haobo Yu. A more complete list of ns-2 contributors can be found at: https://www.isi.edu/nsnam/ns/CHANGES.html.
The ns-3 simulator has been developed by over 250 contributors over the past fifteen years. The original main development team consisted of (in alphabetical order): Raj Bhattacharjea, Gustavo Carneiro, Craig Dowell, Tom Henderson, Mathieu Lacage, and George Riley.
Recognition is also due to the long list of ns-3 software maintainers, many of which made significant contributions to ns-3, including (in alphabetical order): John Abraham, Zoraze Ali, Kirill Andreev, Abhijith Anilkumar, Stefano Avallone, Ghada Badawy Nicola Baldo, Peter D. Barnes, Jr., Biljana Bojovic, Pavel Boyko, Junling Bu, Elena Buchatskaya, Daniel Camara, Matthieu Coudron, Yufei Cheng, Ankit Deepak, Sebastien Deronne, Tom Goff, Federico Guerra, Budiarto Herman, Mohamed Amine Ismail, Sam Jansen, Konstantinos Katsaros, Joe Kopena, Alexander Krotov, Flavio Kubota, Daniel Lertpratchya, Faker Moatamri, Vedran Miletic, Marco Miozzo, Hemanth Narra, Natale Patriciello, Tommaso Pecorella, Josh Pelkey, Alina Quereilhac, Getachew Redieteab, Manuel Requena, Matias Richart, Lalith Suresh, Brian Swenson, Cristiano Tapparello, Adrian S.W. Tam, Hajime Tazaki, Frederic Urbani, Mitch Watrous, Florian Westphal, and Dizhi Zhou.
The full list of ns-3 authors is maintained in the AUTHORS file in the top-level source code directory, and full commit attributions can be found in the git commit logs.
References
[Bre00] Lee Breslau et al., Advances in network simulation, IEEE Computer, vol. 33, no. 5, pp. 59-67, May 2000.
[Est00] Deborah Estrin et al., Network Visualization with Nam, the VINT Network Animator, IEEE Computer, vol. 33, no.11, pp. 63-68, November 2000.
[Hen08] Thomas R. Henderson, Mathieu Lacage, and George F. Riley, Network simulations with the ns-3 simulator, In Proceedings of ACM Sigcomm Conference (demo), 2008.
[Lac06] Mathieu Lacage and Thomas R. Henderson. 2006. Yet another network simulator. In Proceeding from the 2006 workshop on ns-2: the IP network simulator (WNS2 ’06). Association for Computing Machinery, New York, NY, USA, 12–es.
[Ril03] George F. Riley, The Georgia Tech Network Simulator, In Proceedings of the ACM SIGCOMM Workshop on Models, Methods and Tools for Reproducible Network Research (MoMeTools) , Aug. 2003.
[Ril10] George F. Riley and Thomas Henderson, The ns-3 Network Simulator. In Modeling and Tools for Network Simulation, SpringerLink, 2010.
[Taz13] Hajime Tazaki et al. Direct code execution: revisiting library OS architecture for reproducible network experiments. In Proceedings of the ninth ACM conference on Emerging networking experiments and technologies (CoNEXT ’13). Association for Computing Machinery, New York, NY, USA, 217–228.
USC/ISI had multiple projects and was very active in ns-2 development for many years, first lead by Deborah Estrin (with the VINT project), then by John Heidemann (with the SAMAN and SCADDS projects), with Tom Henderson took over leadership and evolved it (with others) into ns-3. All of these efforts have been open source collaborations with key players at other institutions as well. Sally Floyd, Steve McCanne, and Kevin Fall were all leaders.
I would particularly like to thank the several USC students who did PhDs on ns-2 related topics: Polly Huang, Kun-Chan Lan, Debojyoti Dutta, and earlier Kannan Varadhan. Ns-2 also benefited from external code contributions from David B. Johnson’s Monarch group (then at CMU) and Elizabeth Belding and Charles Perkins. (My apologies for other contributors I’m sure I’m missing.)