We document institutional privacy as a new risk posed by DNS data collected at authoritative servers, even after caching and aggregation by DNS recursives. We are the first to demonstrate this risk by looking at leaks of e-mail exchanges which show communications patterns, and leaks from accessing sensitive websites, both of which can harm an institution’s public image. We define a methodology to identify queries from institutions and identify leaks. We show the current practices of prefix-preserving anonymization of IP addresses and aggregation above the recursive are not sufficient to protect institutional privacy, suggesting the need for novel approaches.
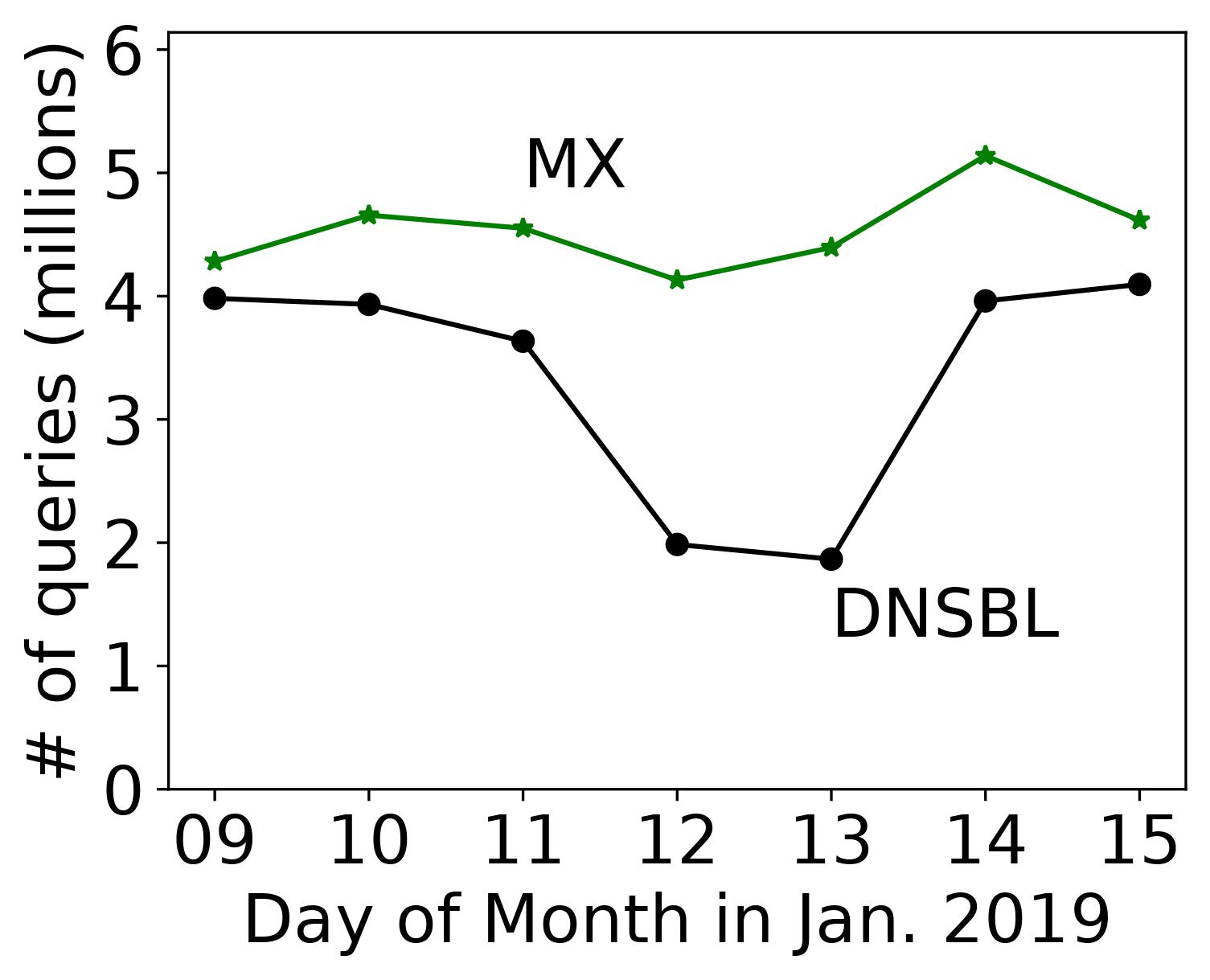
Number of MX and DNSBL queries in a week-long root DNS data that can potentially leak email-related activity
The data from this paper is available upon request, please see our project page.
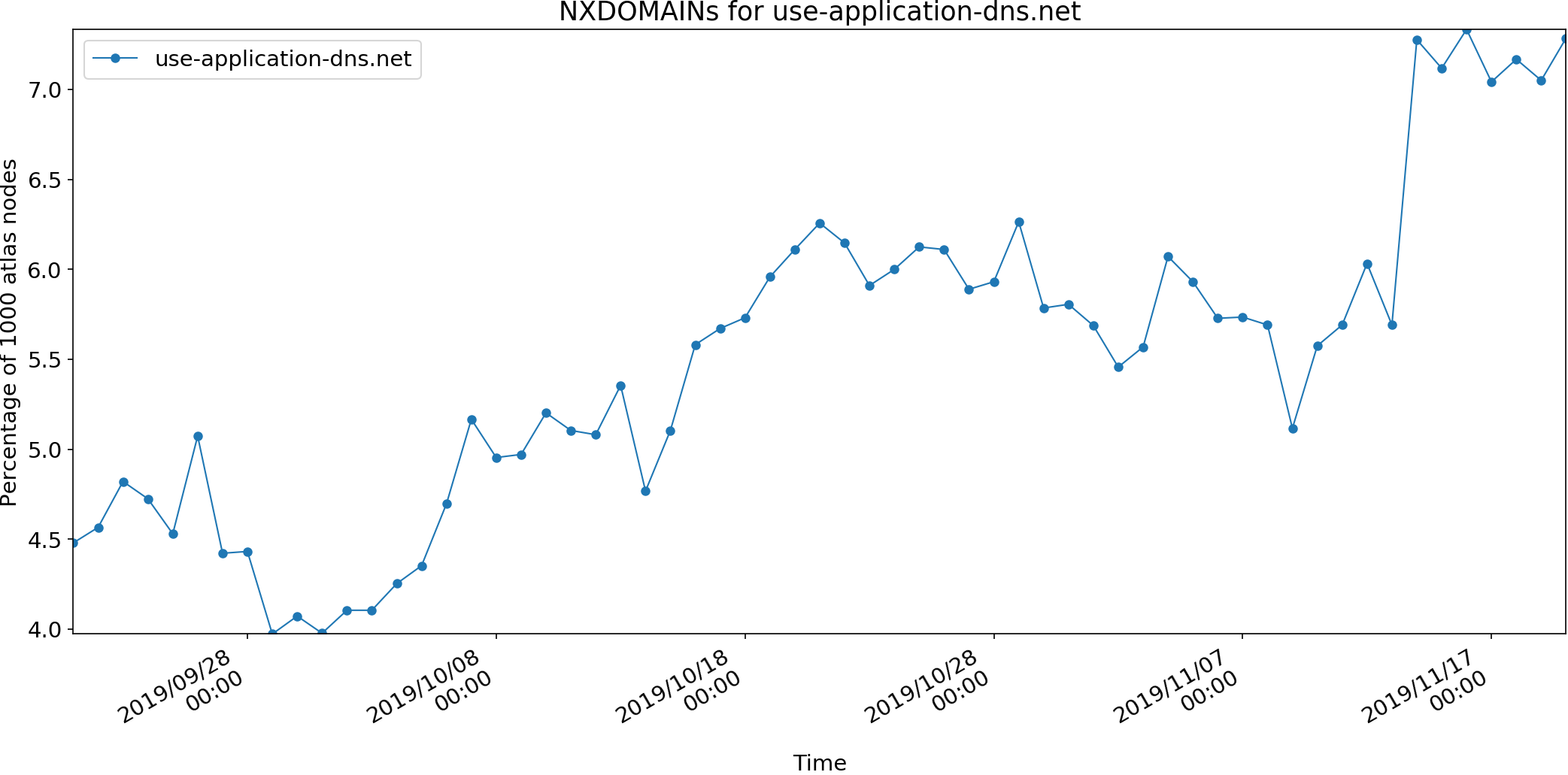
Mozilla announced the creation of a “use-application-dns.net”
“Canary Domain” that could be configured within ISPs to disable
Firefox’s default use of DNS over HTTPS. On 2019/09/21 Wes Hardaker created a
RIPE Atlas measurement to study resolvers within ISPs that had been
configured to return an NXDOMAIN response. This measurement is
configured to have 1000 Atlas probes query for the
use-application-dns.net name once a day.
The full description of methodology is on Wes’ ISI site, which should receive regular updates to the graph.
I would like to congratulate Dr. Liang Zhu for defending his PhD in August 2018 and completing his doctoral dissertation “Balancing Security and Performance of Network Request-Response Protocols” in September 2018.
Liang Zhu (left) and John Heidemann, after Liang’s PhD defense.
From the abstract:
The Internet has become a popular tool to acquire information and knowledge. Usually information retrieval on the Internet depends on request-response protocols, where clients and servers exchange data. Despite of their wide use, request-response protocols bring challenges for security and privacy. For example, source-address spoofing enables denial-of-service (DoS) attacks, and eavesdropping of unencrypted data leaks sensitive information in request-response protocols. There is often a trade-off between security and performance in request-response protocols. More advanced protocols, such as Transport Layer Security (TLS), are proposed to solve these problems of source spoofing and eavesdropping. However, developers often avoid adopting those advanced protocols, due to performance costs such as client latency and server memory requirement. We need to understand the trade-off between security and performance for request-response protocols and find a reasonable balance, instead of blindly prioritizing one of them.
This thesis of this dissertation states that it is possible to improve security of network request-response protocols without compromising performance, by protocol and deployment optimizations, that are demonstrated through measurements of protocol developments and deployments. We support the thesis statement through three specific studies, each of which uses measurements and experiments to evaluate the development and optimization of a request-response protocol. We show that security benefits can be achieved with modest performance costs. In the first study, we measure the latency of OCSP in TLS connections. We show that OCSP has low latency due to its wide use of CDN and caching, while identifying certificate revocation to secure TLS. In the second study, we propose to use TCP and TLS for DNS to solve a range of fundamental problems in DNS security and privacy. We show that DNS over TCP and TLS can achieve favorable performance with selective optimization. In the third study, we build a configurable, general-purpose DNS trace replay system that emulates global DNS hierarchy in a testbed and enables DNS experiments at scale efficiently. We use this system to further prove the reasonable performance of DNS over TCP and TLS at scale in the real world.
In addition to supporting our thesis, our studies have their own research contributions. Specifically, In the first work, we conducted new measurements of OCSP by examining network traffic of OCSP and showed a significant improvement of OCSP latency: a median latency of only 20ms, much less than the 291ms observed in prior work. We showed that CDN serves 94% of the OCSP traffic and OCSP use is ubiquitous. In the second work, we selected necessary protocol and implementation optimizations for DNS over TCP/TLS, and suggested how to run a production TCP/TLS DNS server [RFC7858]. We suggested appropriate connection timeouts for DNS operations: 20s at authoritative servers and 60s elsewhere. We showed that the cost of DNS over TCP/TLS can be modest. Our trace analysis showed that connection reuse can be frequent (60%-95% for stub and recursive resolvers). We showed that server memory is manageable (additional 3.6GB for a recursive server), and latency of connection-oriented DNS is acceptable (9%-22% slower than UDP). In the third work, we showed how to build a DNS experimentation framework that can scale to emulate a large DNS hierarchy and replay large traces. We used this experimentation framework to explore how traffic volume changes (increasing by 31%) when all DNS queries employ DNSSEC. Our DNS experimentation framework can benefit other studies on DNS performance evaluations.
cryptopANT is a C library for IP address anonymization using crypto-PAn algorithm, originally defined by Georgia Tech. The library supports anonymization and de-anonymization (provided you possess a secret key) of IPv4, IPv6, and MAC addresses. The software release includes sample utilities that anonymize IP addresses in text, but we expect most use of the library will be as part of other programs. The Crypto-PAn anonymization scheme was developed by Xu, Fan, Ammar, and Moon at Georgia Tech and described in“Prefix-Preserving IP Address Anonymization”, Computer Networks, Volume 46, Issue 2, 7 October 2004, Pages 253-272, Elsevier. Our library is independent (and not binary compatible) of theirs.
Despite this being the first release as a library, the code has been in use for more than 10 years in other tools. It had been part of our other software packages, such as dag_scrubber for years. By popular request, we’re finally releasing it as a separate package.
The library is packaged with an example binary (scramble_ips) that can be used to anonymize text ips.
See also the crypto-PAn page at Georgia Tech here.
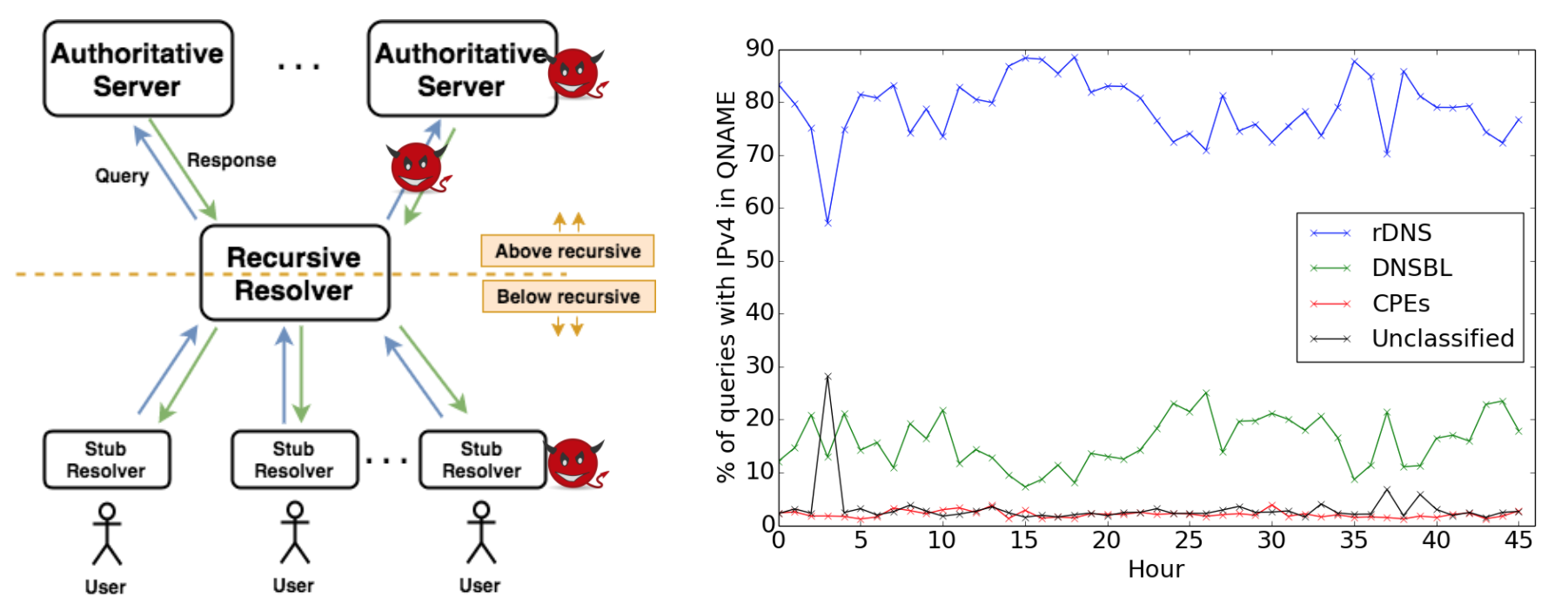
Threat model for enumerating leaks above the recursive (left). Percentage of four categories of queries containing IPv4 addresses in their QNAMEs. (right)
As with any information system consisting of data derived from people’s actions, DNS data is vulnerable to privacy risks. In DNS, users make queries through recursive resolvers to authoritative servers. Data collected below (or in) the recursive resolver directly exposes users, so most prior DNS data sharing focuses on queries above the recursive resolver. Data collected above a recursive resolver has largely been seen as posing a minimal privacy risk since recursive resolvers typically aggregate traffic for many users, thereby hiding their identity and mixing their traffic. Although this assumption is widely made, to our knowledge it has not been verified. In this paper we re-examine this assumption for DNS traffic above the recursive resolver. First, we show that two kinds of information appear in query names above the recursive resolver: IP addresses and sensitive domain names, such as those pertaining to health, politics, or personal or lifestyle information. Second, we examine how often these classes of potentially sensitive names appear in Root DNS traffic, using 48 hours of B-Root data from April 2017.
This is a joint work by Basileal Imana (USC), Aleksandra Korolova (USC) and John Heidemann (USC/ISI).
The DITL dataset (ITL_B_Root-20170411) used in this work is available from DHS IMPACT, the ANT project, and through DNS-OARC.
John Heidemann gave the talk “DNS Privacy, Service Management, and Research: Friends or Foes” at the NDSS DNS Privacy Workshop in San Diego, California, USA on Feburary 26, 2017. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann17a.pdf.
The talk does not have a formal abstract, but to summarize:
A slide from the [Heidemann17a] talk, looking at what different DNS stakeholders may want.
This invited talk is part of a panel on the tension between DNS privacy and service management. In the talk I expand on that topic and discuss
the tension between DNS privacy, service management, and research.
I give suggestions about how service management and research can adapt to proceed while still providing basic privacy.
This document describes the use of Transport Layer Security (TLS) to provide privacy for DNS. Encryption provided by TLS eliminates opportunities for eavesdropping and on-path tampering with DNS queries in the network, such as discussed in RFC 7626. In addition, this document specifies two usage profiles for DNS over TLS and provides advice on performance considerations to minimize overhead from using TCP and TLS with DNS.
This document focuses on securing stub-to-recursive traffic, as per
the charter of the DPRIVE Working Group. It does not prevent future applications of the protocol to recursive-to-authoritative traffic.
This RFC is joint work of Zhi Hu, Liang Zhu, John Heidemann, Allison Mankin, Duane Wessels, and Paul Hoffman, of USC/ISI, Verisign, ICANN, and independent (at different times). This RFC is one result of our prior paper “Connection-Oriented DNS to Improve Privacy and Security”, but also represents the input of the DPRIVE IETF working group (Warren Kumari and Tim Wicinski, chairs), where it is one of a set of RFCs designed to improve DNS privacy.
John Heidemann gave the talk “New Opportunities for Research and Experiments in Internet Naming And Identification” at the AIMS 2016 workshop at CAIDA, La Jolla, California on February 11, 2016. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann16a.pdf.
Needs for new naming and identity research prompt new research infrastructure, enabling new research directions.
From the abstract:
DNS is central to Internet use today, yet research on DNS today is challenging: many researchers find it challenging to create realistic experiments at scale and representative of the large installed base, and datasets are often short (two days or less) or otherwise limited. Yes DNS evolution presses on: improvements to privacy are needed, and extensions like DANE provide an opportunity for DNS to improve security and support identity management. We exploring how to grow the research community and enable meaningful work on Internet naming. In this talk we will propose new research infrastructure to support to realistic DNS experiments and longitudinal data studies. We are looking for feedback on our proposed approaches and input about your pressing research problems in Internet naming and identification.
Digit is our DNS client side tool that can perform DNS queries via different protocols such as UDP, TCP, TLS. This tool is primarily designed to evaluate the client side latency of using DNS over TCP/TLS.
IANA has allocated port 853 to use TLS/DTLS for DNS temporarily in the most recent version of Internet draft “DNS over TLS: Initiation and Performance Considerations” (draft-ietf-dprive-dns-over-tls-01).
To track the current specification, we have updated Digit to do direct TLS on port 853 by default, with TCP. STARTTLS and other protocols as options for comparison.
We have released an alpha version of our extension and source code here: http://www.isi.edu/ant/software/phish/.
We would greatly appreciate any help and feedback in testing our plugin!
From the abstract:
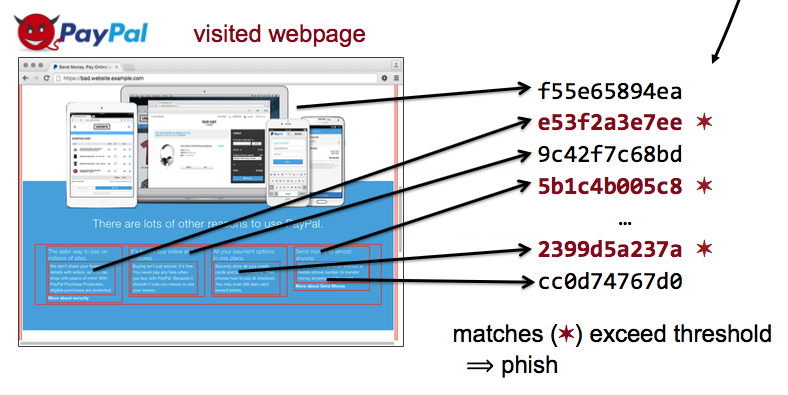
Our browser extension hashes the content of a visited page and compares the hashes with a set of known good hashes. If the number of matches exceeds a threshold, the website is suspected as phish and an alert is displayed to the user.
Increasing use of Internet banking and shopping by a broad spectrum of users results in greater potential profits from phishing attacks via websites that masquerade as legitimate sites to trick users into sharing passwords or financial information. Most browsers today detect potential phishing with URL blacklists; while effective at stopping previously known threats, blacklists must react to new threats as they are discovered, leaving users vulnerable for a period of time. Alternatively, whitelists can be used to identify “known-good” websites so that off-list sites (to include possible phish) can never be accessed, but are too limited for many users. Our goal is proactive detection of phishing websites with neither the delay of blacklist identification nor the strict constraints of whitelists. Our approach is to list known phishing targets, index the content at their correct sites, and then look for this content to appear at incorrect sites. Our insight is that cryptographic hashing of page contents allows for efficient bulk identification of content reuse at phishing sites. Our contribution is a system to detect phish by comparing hashes of visited websites to the hashes of the original, known good, legitimate website. We implement our approach as a browser extension in Google Chrome and show that our algorithms detect a majority of phish, even with minimal countermeasures to page obfuscation. A small number of alpha users have been using the extension without issues for several weeks, and we will be releasing our extension and source code upon publication.