The DIVOICE project’s goal is to detect and understand Network/Internet Disruptive Events (NIDEs)—outages in the Internet.
We will work toward this goal by examining outages at multiple levels of the network: at the data plane, with tools such as Trinocular (developed at USC/ISI) and Disco (developed at IIJ); at the control plane, with tools such as BGPMon (developed at Colorado State University); and at the application layer.
We expect to improve methods of outage detection, validate the work against each other and external sources of information, and work towards attribution of outage root causes.
Caching and retries protect half of clients even with 90% loss and an attack twice the cache duration. (Figure 7c from [Moura18b].)
The Internet’s Domain Name System (DNS) is a frequent target of Distributed Denial-of-Service (DDoS) attacks, but such attacks have had very different outcomes—some attacks have disabled major public websites, while the external effects of other attacks have been minimal. While on one hand the DNS protocol is relatively simple, the \emph{system} has many moving parts, with multiple levels of caching and retries and replicated servers. This paper uses controlled experiments to examine how these mechanisms affect DNS resilience and latency, exploring both the client side’s DNS \emph{user experience}, and server-side traffic. We find that, for about 30\% of clients, caching is not effective. However, when caches are full they allow about half of clients to ride out server outages that last less than cache lifetimes, Caching and retries together allow up to half of the clients to tolerate DDoS attacks longer than cache lifetimes, with 90\% query loss, and almost all clients to tolerate attacks resulting in 50\% packet loss. While clients may get service during an attack, tail-latency increases for clients. For servers, retries during DDoS attacks increase normal traffic up to $8\times$. Our findings about caching and retries help explain why users see service outages from some real-world DDoS events, but minimal visible effects from others.
Moura18a Figure 6a, Answers received during a DDoS attack causing 100% packet loss with pre-loaded caches.
From the abstract:
The Internet’s Domain Name System (DNS) is a frequent target of Distributed Denial-of-Service (DDoS) attacks, but such attacks have had very different outcomes—some attacks have disabled major public websites, while the external effects of other attacks have been minimal. While on one hand the DNS protocol is a relatively simple, the system has many moving parts, with multiple levels of caching and retries and replicated servers. This paper uses controlled experiments to examine how these mechanisms affect DNS resilience and latency, exploring both the client side’s DNS user experience, and server-side traffic. We find that, for about about 30% of clients, caching is not effective. However, when caches are full they allow about half of clients to ride out server outages, and caching and retries allow up to half of the clients to tolerate DDoS attacks that result in 90% query loss, and almost all clients to tolerate attacks resulting in 50% packet loss. The cost of such attacks to clients are greater median latency. For servers, retries during DDoS attacks increase normal traffic up to 8x. Our findings about caching and retries can explain why some real-world DDoS cause service outages for users while other large attacks have minimal visible effects.
John Heidemann gave the talk “Internet Outages: Reliablity and Security” at the University of Oregon Cybersecurity Day in Eugene, Oregon on April 23, 2018. Slides are available at https://www.isi.edu/~johnh/PAPERS/Heidemann18e.pdf.
Network outages as a security problem.
From the abstract:
The Internet is central to our lives, but we know astoundingly little about it. Even though many businesses and individuals depend on it, how reliable is the Internet? Do policies and practices make it better in some places than others?
Since 2006, we have been studying the public face of the Internet to answer these questions. We take regular censuses, probing the entire IPv4 Internet address space. For more than two years we have been observing Internet reliability through active probing with Trinocular outage detection, revealing the effects of the Internet due to natural disasters like Hurricanes from Sandy to Harvey and Maria, configuration errors that sometimes affect millions of customers, and political events where governments have intervened in Internet operation. This talk will describe how it is possible to observe Internet outages today and what they are beginning to say about the Internet and about the physical world.
This talk builds on research over the last decade in IPv4 censuses and outage detection and includes the work of many of my collaborators.
Data from this talk is all available; see links on the last slide.
This visualization was initially seeded by a Michael Keston research grant here at ISI, and the outage measurement techniques and ongoing data collection has been developed with the support of DHS (the LANDER-2007, LACREND, LACANIC, and Retro-future Bridge and Outages projects).
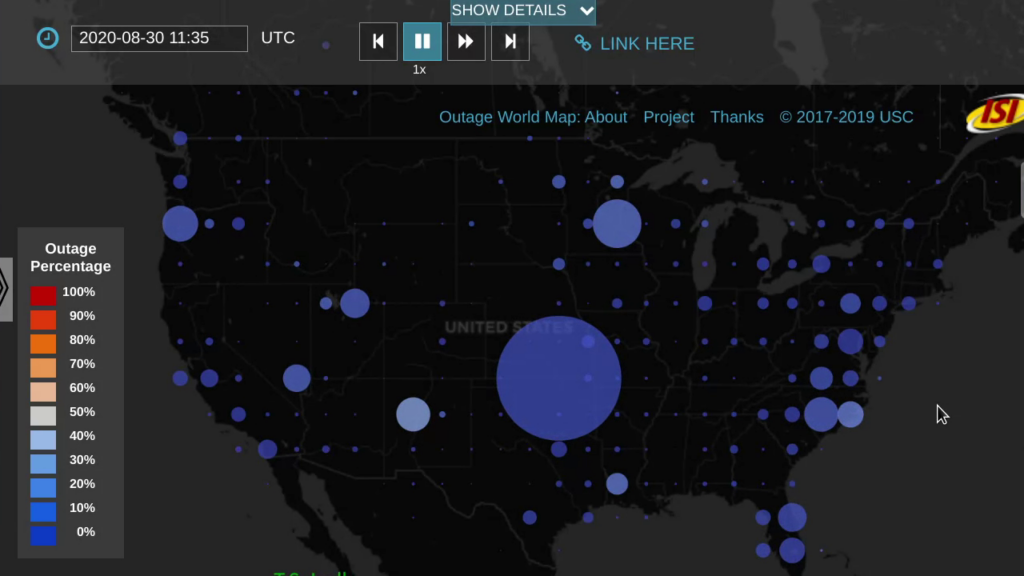
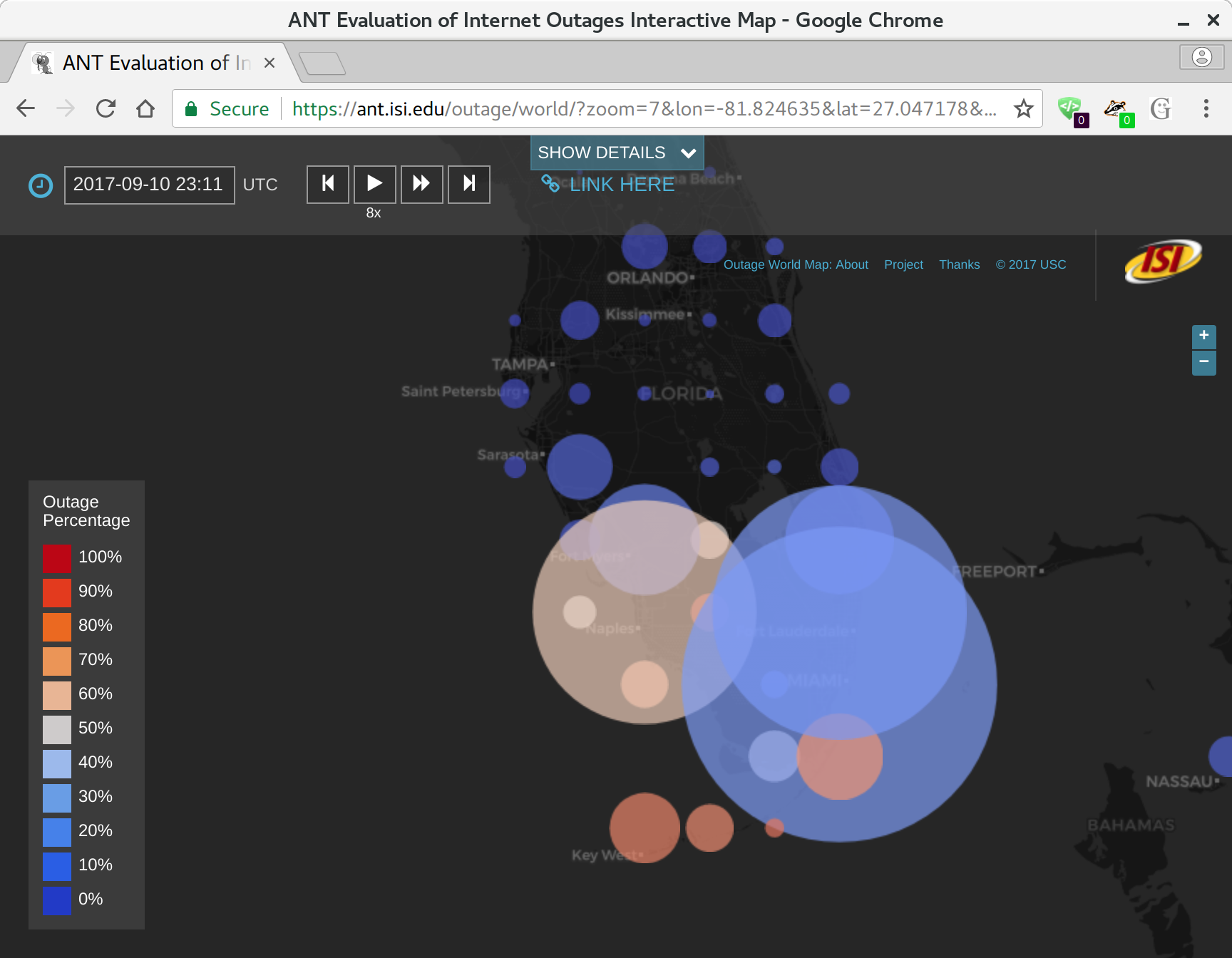
Our website supports browsing more than two years of outage data, organized by geography and time. The map is a google-maps-style world map, with circle on it at even intervals (every 0.5 to 2 degrees of latitude and longitude, depending on the zoom level). Circle sizes show how many /24 network blocks are out in that location, while circle colors show the percentage of outages, from blue (only a few percent) to red (approaching 100%).
We hope that this website makes our outage data more accessible to researchers and the public.
The raw data underlying this website is available on request, see our outage dataset webpage.
The research is funded by the Department of Homeland Security (DHS) Cyber Security Division (through the LACREND and Retro-Future Bridge and Outages projects) and Michael Keston, a real estate entrepreneur and philanthropist (through the Michael Keston Endowment). Michael Keston helped support this the initial version of this website, and DHS has supported our outage data collection and algorithm development.
The website was developed by Dominik Staros, ISI web developer and owner of Imagine Web Consulting, based on data collected by ISI researcher Yuri Pradkin. It builds on prior work by Pradkin, Heidemann and USC’s Lin Quan in ISI’s Analysis of Network Traffic Lab.
The LACANIC project’s goal is to develop datasets to improve Internet security and readability. We distribute these datasets through the DHS IMPACT program.
As part of this work we:
provide regular data collection to collect long-term, longitudinal data
curate datasets for special events
build websites and portals to help make data accessible to casual users
develop new measurement approaches
We provide several types of datasets:
anonymized packet headers and network flow data, often to document events like distributed denial-of-service (DDoS) attacks and regular traffic
Internet censuses and surveys for IPv4 to document address usage
Internet hitlists and histories, derived from IPv4 censuses, to support other topology studies
application data, like DNS and Internet-of-Things mapping, to document regular traffic and DDoS events
and we are developing other datasets
LACANIC allows us to continue some of the data collection we were doing as part of the LACREND project, as well as develop new methods and ways of sharing the data.
New network measurements are great–you can learn about the whole world! But new network measurements are horrible–are you sure you learn about the world, and not about bugs in your code or approach? New scientific approaches must be tested and ultimately calibrated against ground truth. Yet ground truth about the Internet can be quite difficult—often network operators themselves do not know all the details of their network. This talk will explore the role of ground truth in network measurement: getting it when you can, alternatives when it’s imperfect, and what we learn when none is available.
This talk builds on research over the last decade with many people, and the slides include some discussion from the TMA PhD school audience.
The paper “Does Anycast hang up on you?” will appear in the 2017 Conference on Network Traffic Measurement and Analysis (TMA) July 21-23, 2017 in Dublin, Ireland.
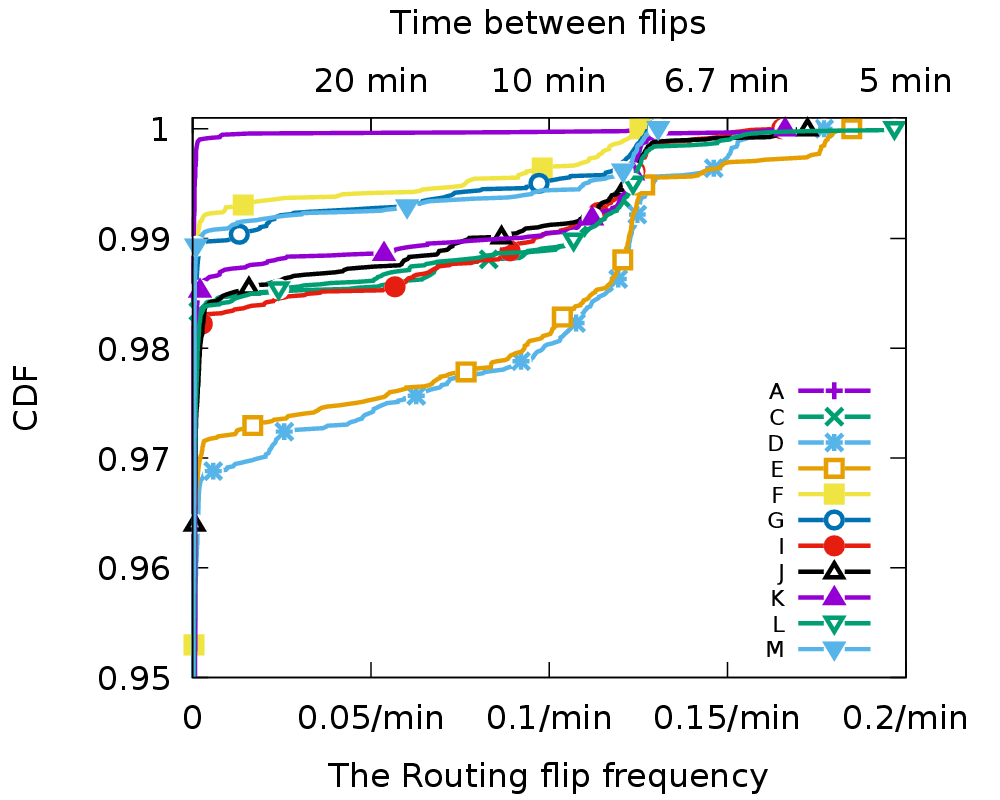
In each anycast-based DNS root service, there are about 1% VPs see a route flip happens every one or two observation during a week with an observation interval as 4 minutes. (Figure 2 from [Wei17b]).From the abstract:
Anycast-based services today are widely used commercially, with several major providers serving thousands of important websites. However, to our knowledge, there has been only limited study of how often anycast fails because routing changes interrupt connections between users and their current anycast site. While the commercial success of anycast CDNs means anycast usually work well, do some users end up shut out of anycast? In this paper we examine data from more than 9000 geographically distributed vantage points (VPs) to 11 anycast services to evaluate this question. Our contribution is the analysis of this data to provide the first quantification of this problem, and to explore where and why it occurs. We see that about 1\% of VPs are anycast unstable, reaching a different anycast site frequently (sometimes every query). Flips back and forth between two sites in 10 seconds are observed in selected experiments for given service and VPs. Moreover, we show that anycast instability is persistent for some VPs—a few VPs never see a stable connections to certain anycast services during a week or even longer. The vast majority of VPs only saw unstable routing towards one or two services instead of instability with all services, suggesting the cause of the instability lies somewhere in the path to the anycast sites. Finally, we point out that for highly-unstable VPs, their probability to hit a given site is constant, which means the flipping are happening at a fine granularity—per packet level, suggesting load balancing might be the cause to anycast routing flipping. Our findings confirm the common wisdom that anycast almost always works well, but provide evidence that a small number of locations in the Internet where specific anycast services are never stable.