On April 24, 2022 we will publish a new paper titled “Chhoyhopper: A Moving Target Defense with IPv6” by A S M Rizvi and John Heidemann at the 4th Workshop on Measurements, Attacks, and Defenses for the Web (MADWeb 2022), co-located with NDSS. We provide Chhoyhopper as an open-source tool for SSH and HTTPS—try it out!
From the abstract:
Services on the public Internet are frequently scanned, then subject to brute-force password attempts and Denial-of-Service (DoS) attacks. We would like to run such services stealthily, where they are available to friends but hidden from adversaries. In this work, we propose a discovery-resistant moving target defense named “Chhoyhopper” that utilizes the vast IPv6 address space to conceal publicly available services. The client meets the server at an IPv6 address that changes in a pattern based on a shared, pre-distributed secret and the time of day. By hopping over a /64 prefix, services cannot be found by active scanners, and passively observed information is useless after two minutes. We demonstrate our system with the two important applications—SSH and HTTPS, and make our system publicly available.
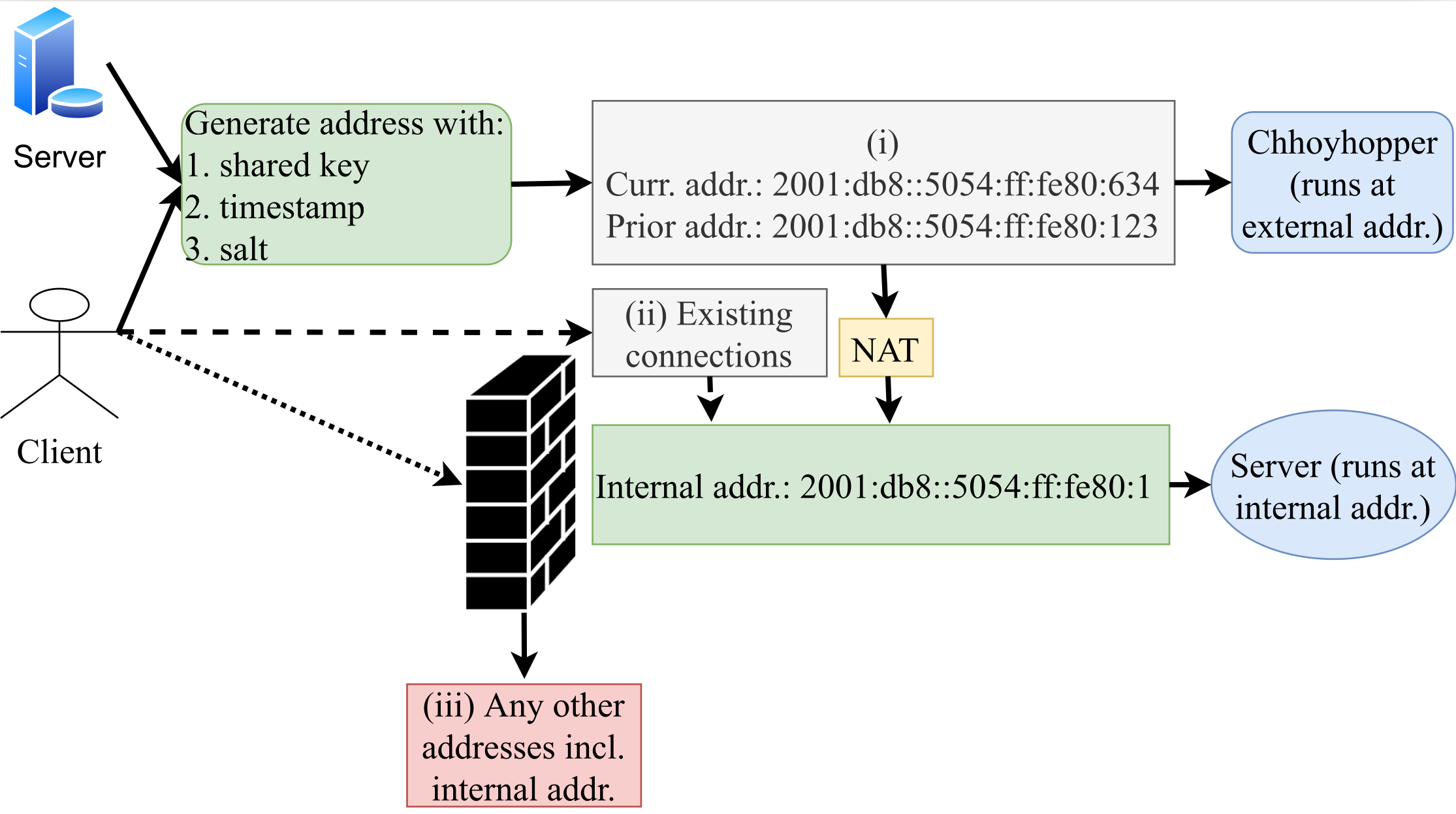
Thanks: A S M Rizvi and John Heidemann’s work on this paper is supported, in part, by the DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I (PAADDoS), and by DARPA under Contract No. HR001120C0157 (SABRES). Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of NSF or DARPA. We thank Rayner Pais who prototyped an early version of Chhoyhopper and version in IPv4 hopping over ports.