I would like to congratulate Dr. Manaf Gharaibeh for defending his PhD at Colorado State University in February 2020 and completing his doctoral dissertation “Characterizing the Visible Address Space to Enable Efficient, Continuous IP Geolocation” in March 2020.
From the abstract:

Internet Protocol (IP) geolocation is vital for location-dependent applications and many network research problems. The benefits to applications include enabling content customization, proximal server selection, and management of digital rights based on the location of users, to name a few. The benefits to networking research include providing geographic context useful for several purposes, such as to study the geographic deployment of Internet resources, bind cloud data to a location, and to study censorship and monitoring, among others.
The measurement-based IP geolocation is widely considered as the state-of-the-art client-independent approach to estimate the location of an IP address. However, full measurement-based geolocation is prohibitive when applied continuously to the entire Internet to maintain up-to-date IP-to-location mappings. Furthermore, many IP address blocks rarely move, making it unnecessary to perform such full geolocation.
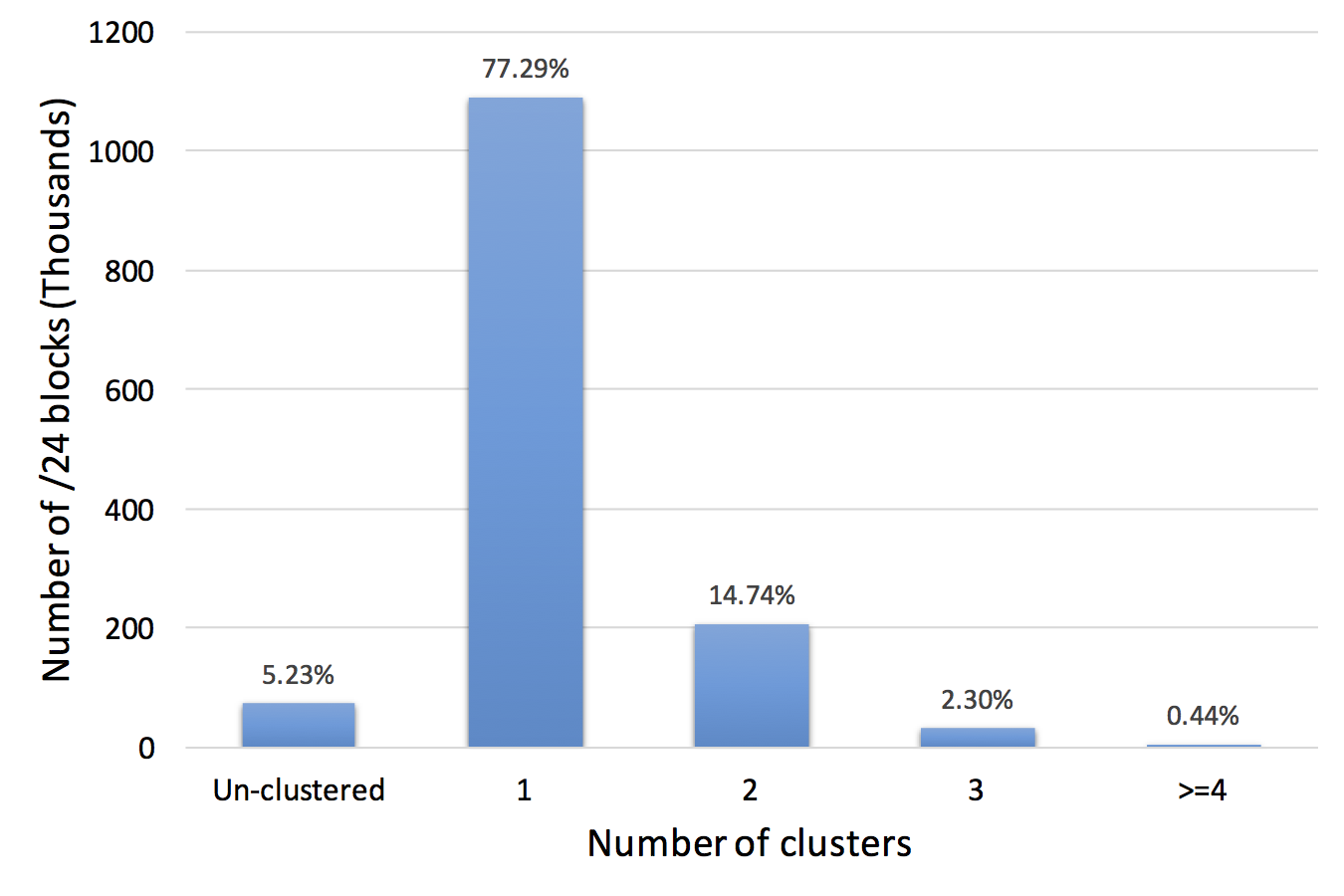
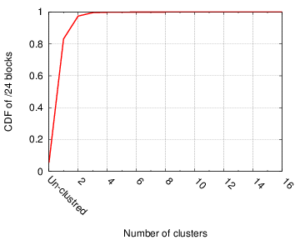
The thesis of this dissertation states that \emph{we can enable efficient, continuous IP geolocation by identifying clusters of co-located IP addresses and their location stability from latency observations.} In this statement, a cluster indicates a group of an arbitrary number of adjacent co-located IP addresses (a few up to a /16). Location stability indicates a measure of how often an IP block changes location. We gain efficiency by allowing IP geolocation systems to geolocate IP addresses as units, and by detecting when a geolocation update is required, optimizations not explored in prior work. We present several studies to support this thesis statement.
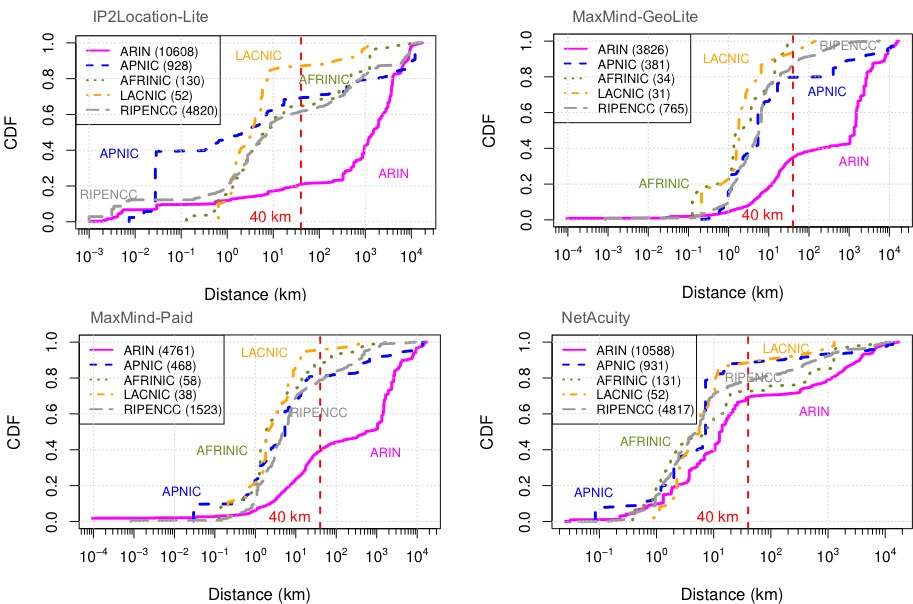
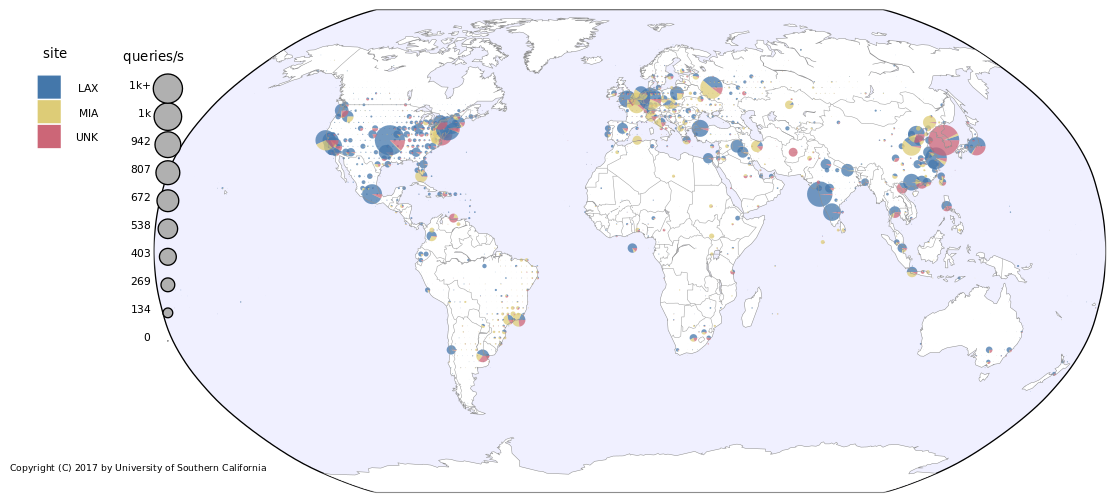
We first present a study to evaluate the reliability of router geolocation in popular geolocation services, complementing prior work that evaluates end-hosts geolocation in such services. The results show the limitations of these services and the need for better solutions, motivating our work to enable more accurate approaches. Second, we present a method to identify clusters of \emph{co-located} IP addresses by the similarity in their latency. Identifying such clusters allows us to geolocate them efficiently as units without compromising accuracy. Third, we present an efficient delay-based method to identify IP blocks that move over time, allowing us to recognize when geolocation updates are needed and avoid frequent geolocation of the entire Internet to maintain up-to-date geolocation. In our final study, we present a method to identify cellular blocks by their distinctive variation in latency compared to WiFi and wired blocks. Our method to identify cellular blocks allows a better interpretation of their latency estimates and to study their geographic properties without the need for proprietary data from operators or users.