As part of research at ANT we generate a lot of data, and our goal is to keep it safe even in the face of an imperfect world of data storage.
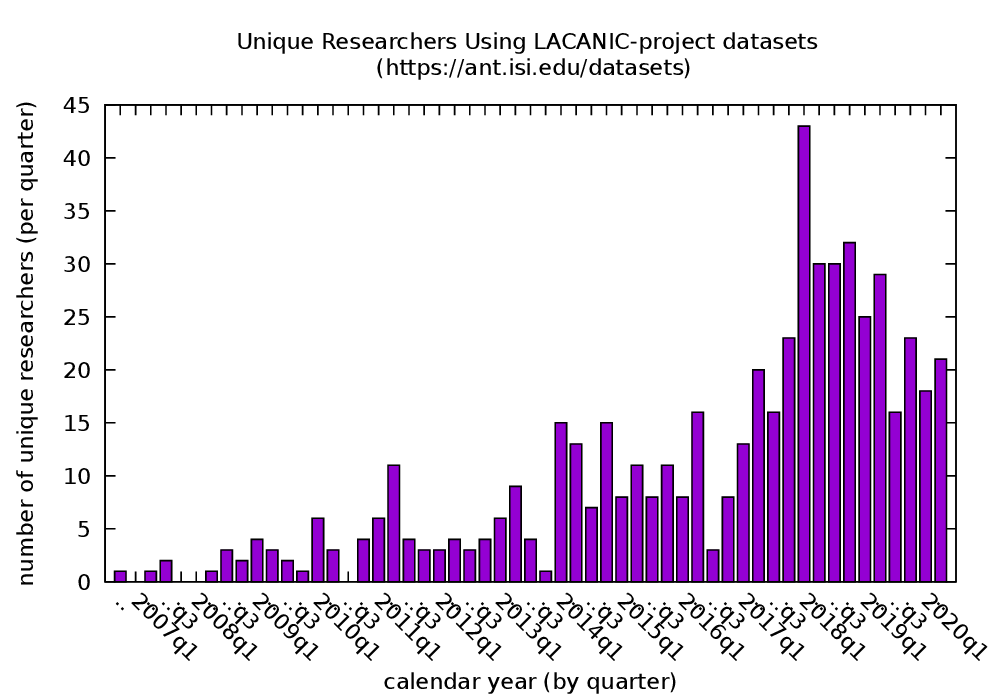
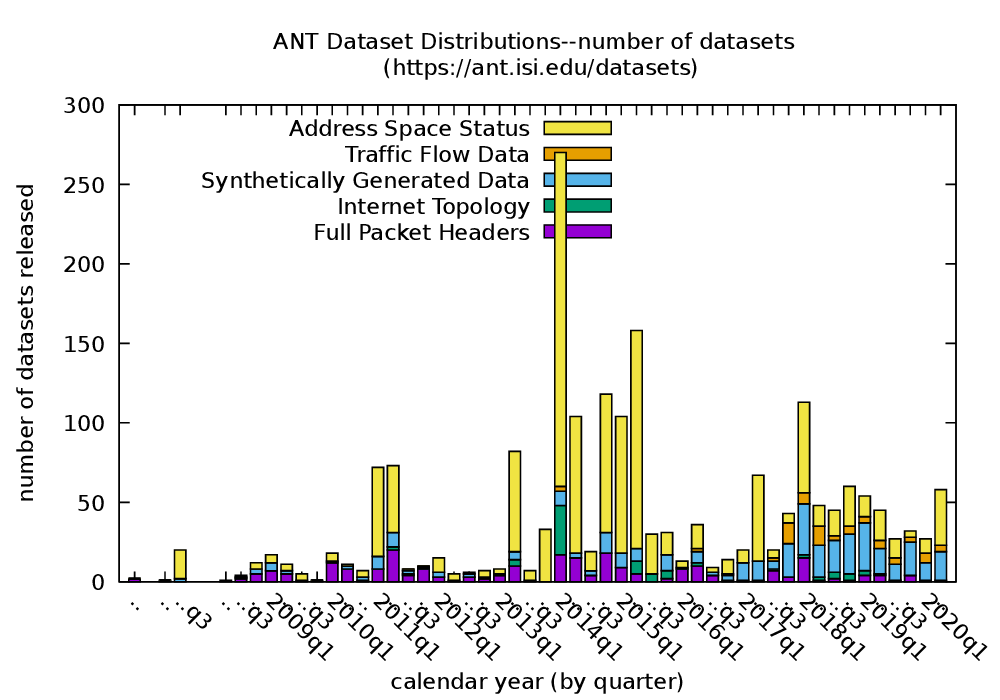
When we say a lot, we mean hundreds of terabytes: As of May 2020, we have releasable 860 datasets making up 134 TB of storage (510TB if we uncompressed it). We provide this data at no cost to researchers, and since 2008 we’ve provided 2049 datasets (338 TB, or 1.1PB if uncompressed!) to 406 researchers!
These datasets range from packet captures of “normal” traffic, to curated captures of DDoS attacks, as well as dozens of research paper-specific datasets, 16 years of Internet censuses and 7 years of Internet outages, plus target lists for IPv4 that are regularly used for traffic studies and tools like Verfploeter anycast mapping.
As part of keeping this data, our goal is to keep this data. We want to fight bit rot and data loss. That means the RAID-6 for primary storage, with monitoring and timely disk replacement. It means off site backup (with a big thanks to our collaborators at Colorado State University, Christos Papadopoulos, Craig Partridge, and Dimitrios Kounalakis for their help). And it means watching bits to make sure they don’t spontaneously change.
One might think that bits at rest stay at rest, but… not always. We’ve seen three times when disks have spontaneously changed a byte over the last 20 years. In 2011 and 2012 I had bit flips on my personal files, and in 2020 we had a byte flip on a packet capture.
How do we know? We have application-level checksums of every file, and every day we take 10 minutes to check at least one dataset against its checksums. (Over time, we cover all datasets and then start all over.)
Our checksumming software is babarchive–our own wrapper around collecting SHA-256 checksums over a directory tree. We encourage other researchers interested in long-term data curation to carry out active content monitoring (in addition to backups and RAID).
A huge thanks to our research sponsors: DHS (through the LANDER, LACREND, and LACANIC projects), NSF (through the MADCAT, MR-Net), and DARPA (through GAWSEED).
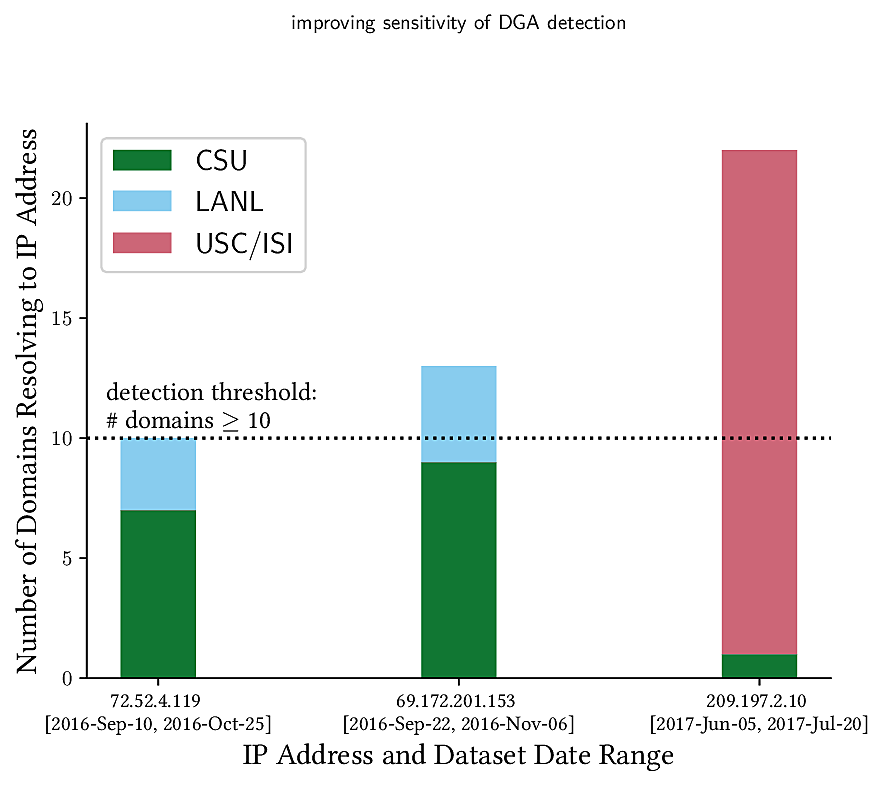
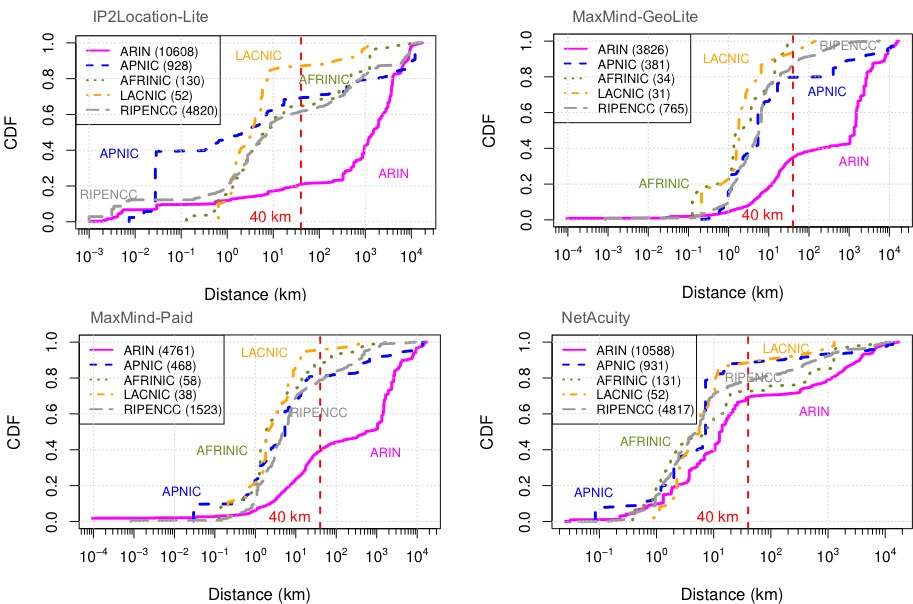


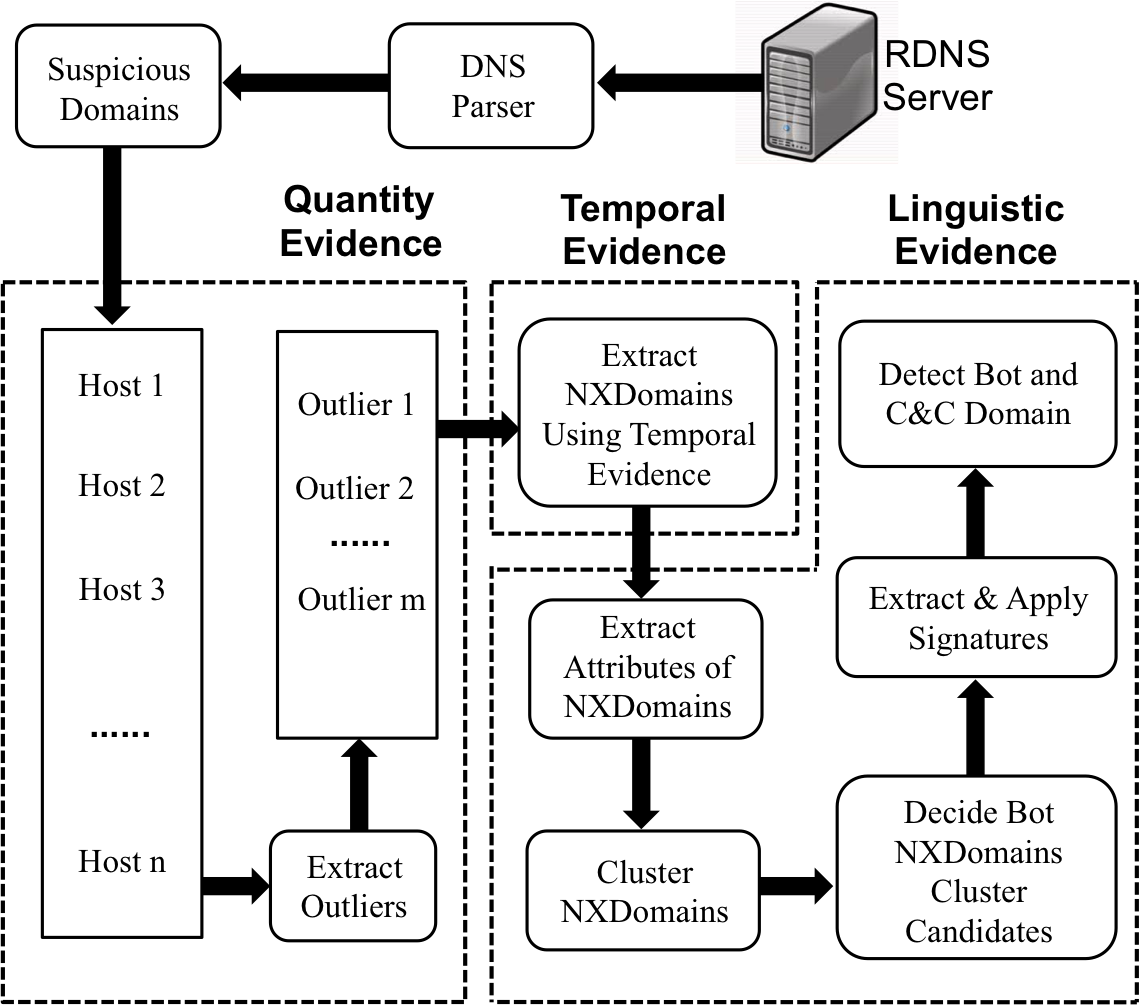
 These limitations make it very hard to detect individual bots when using traffic collected from a single network. In this paper, we introduce BotDigger, a system that detects DGA-based bots using DNS traffic without a priori knowledge of the domain generation algorithm. BotDigger utilizes a chain of evidence, including quantity, temporal and linguistic evidence
These limitations make it very hard to detect individual bots when using traffic collected from a single network. In this paper, we introduce BotDigger, a system that detects DGA-based bots using DNS traffic without a priori knowledge of the domain generation algorithm. BotDigger utilizes a chain of evidence, including quantity, temporal and linguistic evidence