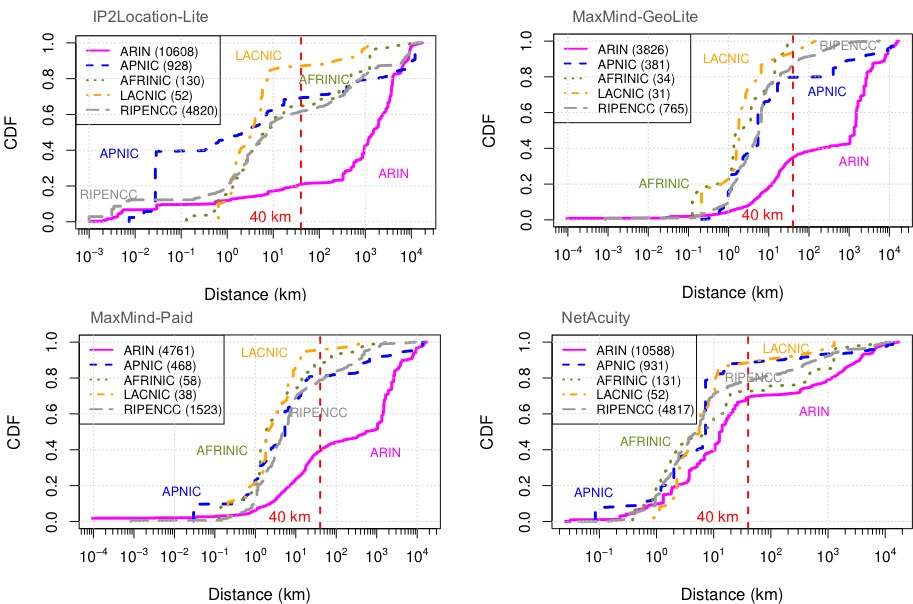
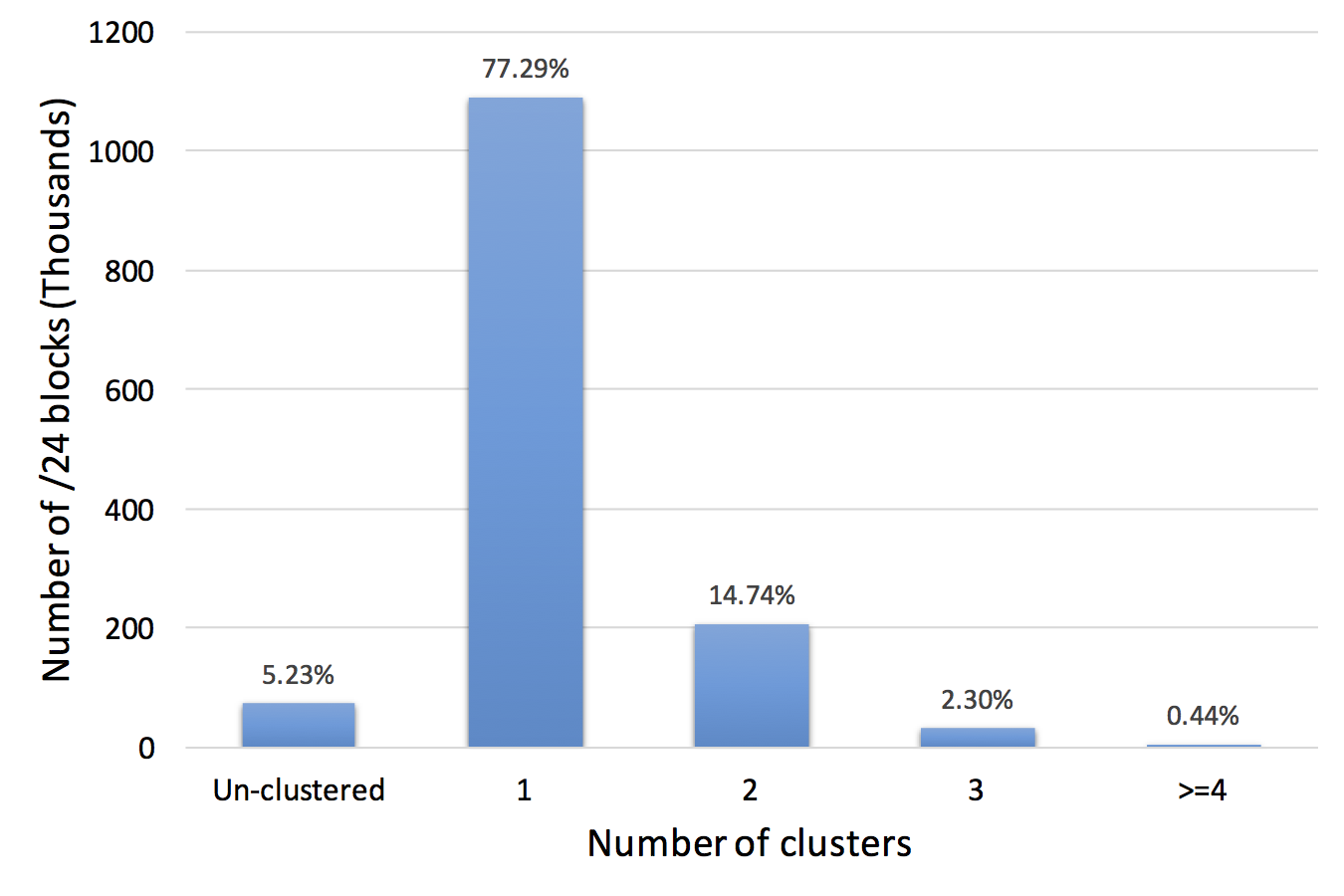
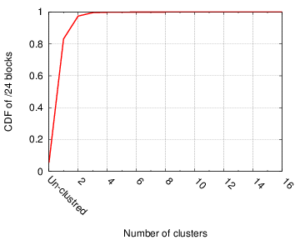
We have released a new technical report: “Reasoning about Internet Connectivity”, available at https://arxiv.org/abs/2407.14427.
From the abstract:
Innovation in the Internet requires a global Internet core to enable
communication between users in ISPs and services in the cloud. Today, this Internet core is challenged by partial reachability: political pressure
threatens fragmentation by nationality, architectural changes such as
carrier-grade NAT make connectivity conditional, and operational problems and commercial disputes make reachability incomplete for months. We assert that partial reachability is a fundamental part of the Internet core. While some systems paper over partial reachability, this paper is the first to provide a conceptual definition of the Internet core
so we can reason about reachability from first principles. Following
the Internet design, our definition is guided by reachability, not
authority. Its corollaries are peninsulas: persistent regions of
partial connectivity; and islands: when networks are partitioned
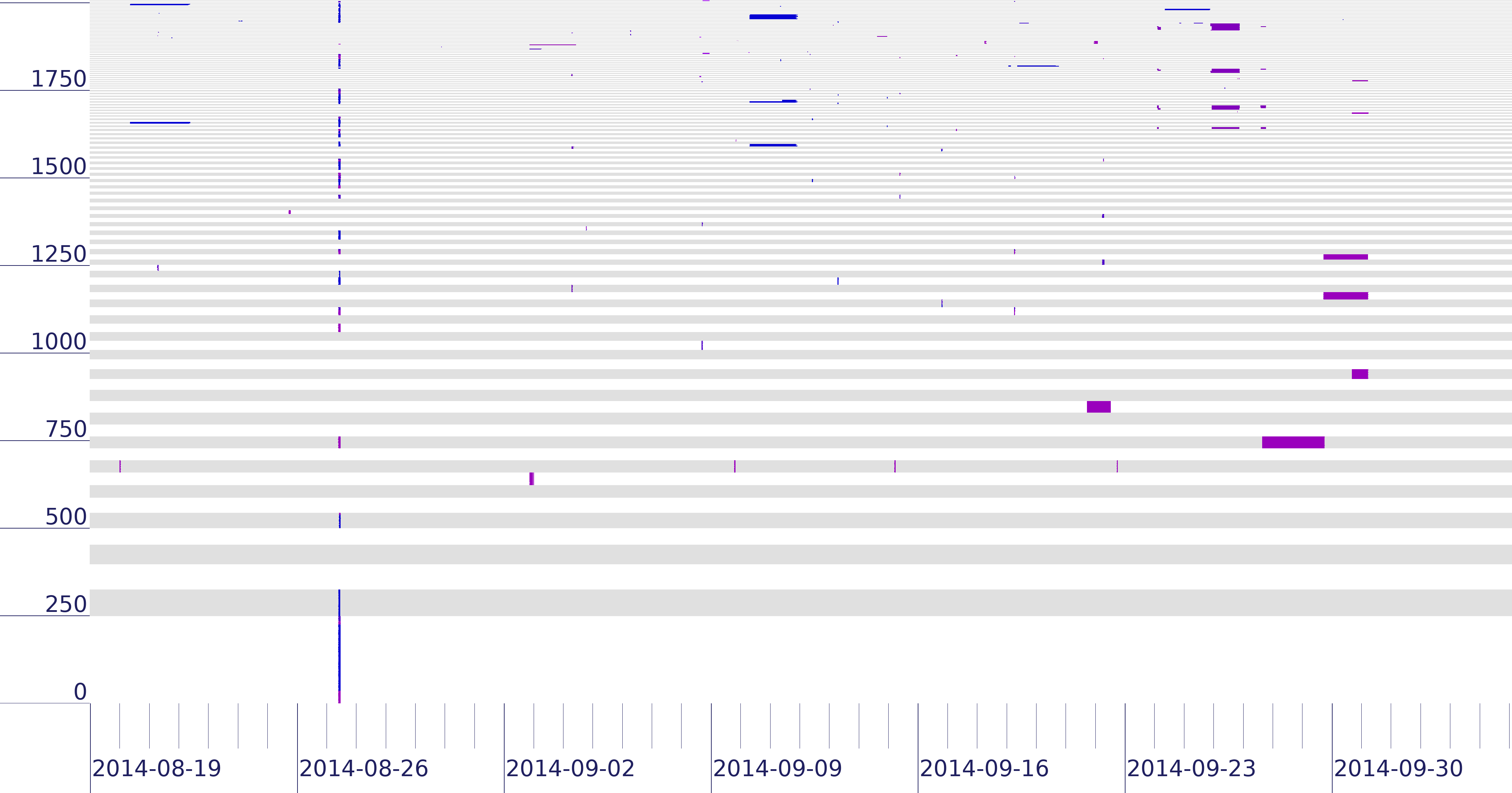
from the Internet core. We show that the concept of peninsulas and islands can improve existing measurement systems. In one example,
they show that RIPE’s DNSmon suffers misconfiguration and persistent
network problems that are important, but risk obscuring operationally
important connectivity changes because they are 5x to 9.7x larger. Our evaluation also informs policy questions, showing no single
country or organization can unilaterally control the Internet core.
This technical report is joint work of Guillermo Baltra, Tarang Saluja, Yuri Pradkin, John Heidemann done at USC/ISI. This work was supported by the NSF via the EIEIO and InternetMap projects.

![Estimated impact on user QoE in four cable cut incidents (Figure 13 from [Cai13c])](http://ant.isi.edu/blog/wp-content/uploads/2013/12/qoe_play_time_350k_vod_3d_all.png)
