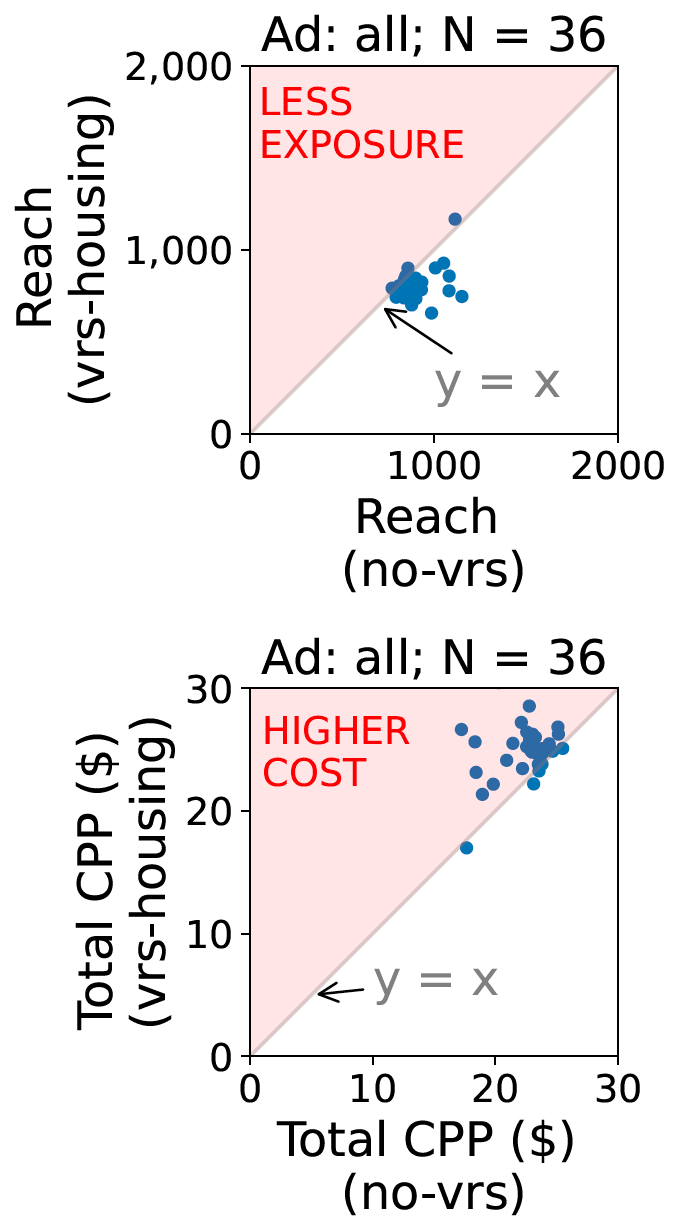
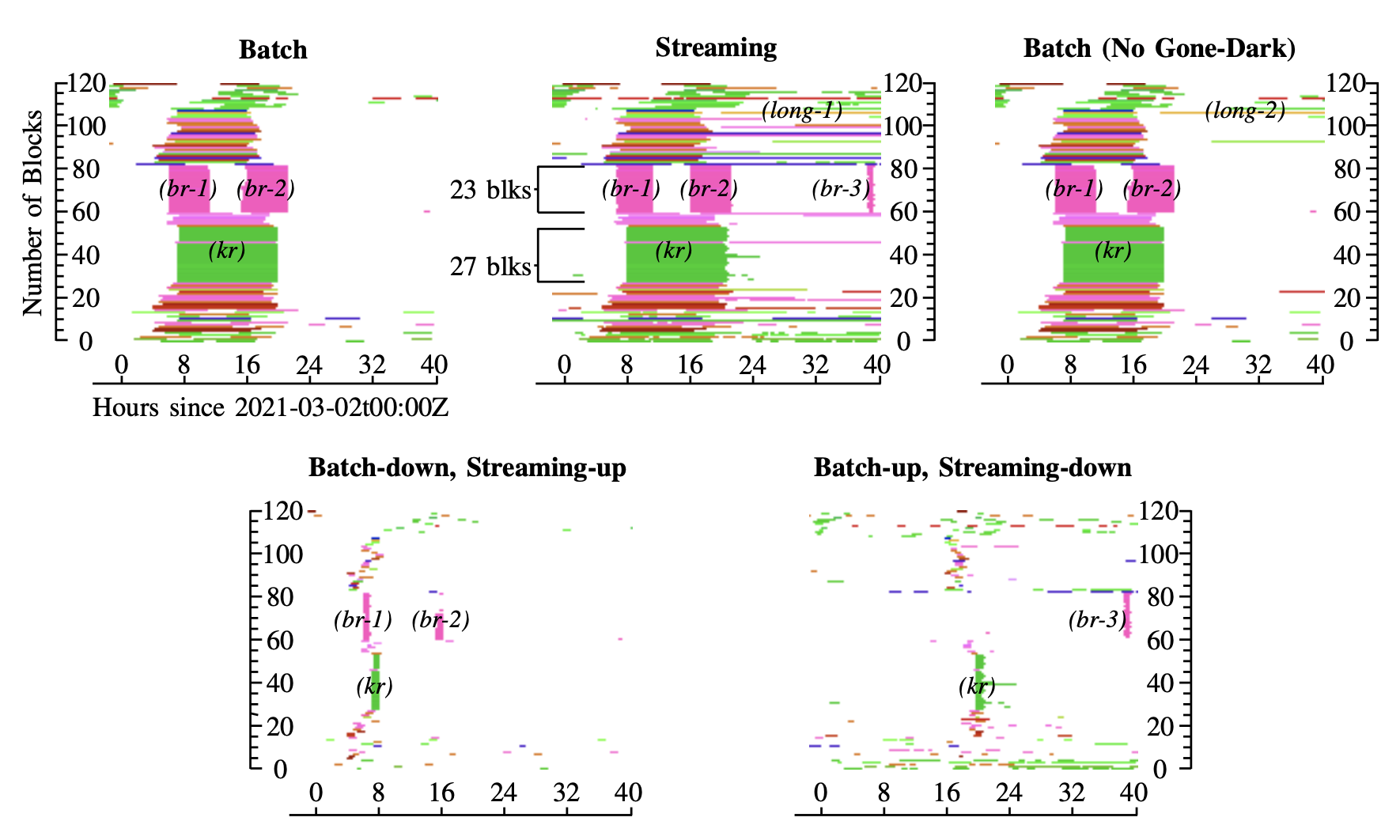
Our new paper “Understanding Partial Reachability in the Internet Core” will appear at the 2026 New Ideas in Networked Systems (NINeS), a virtual meeting on February 10, 2026.
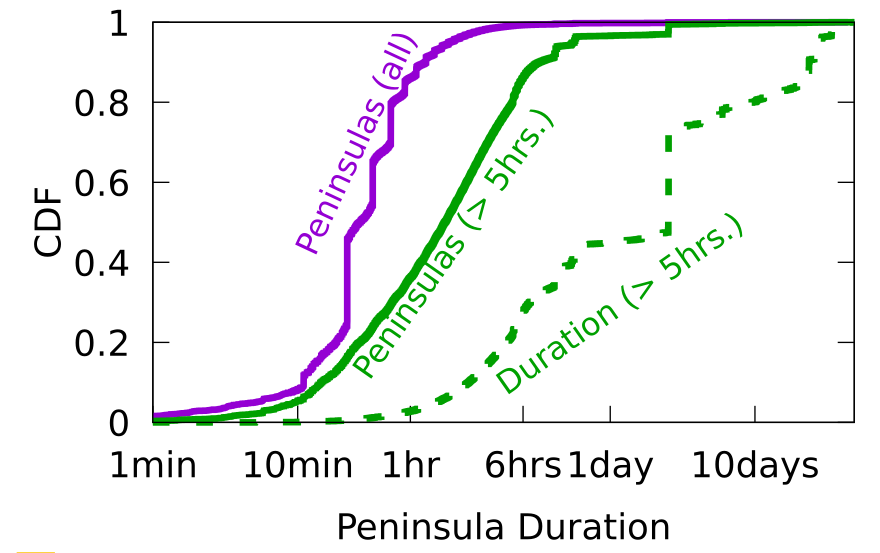
From the abstract:
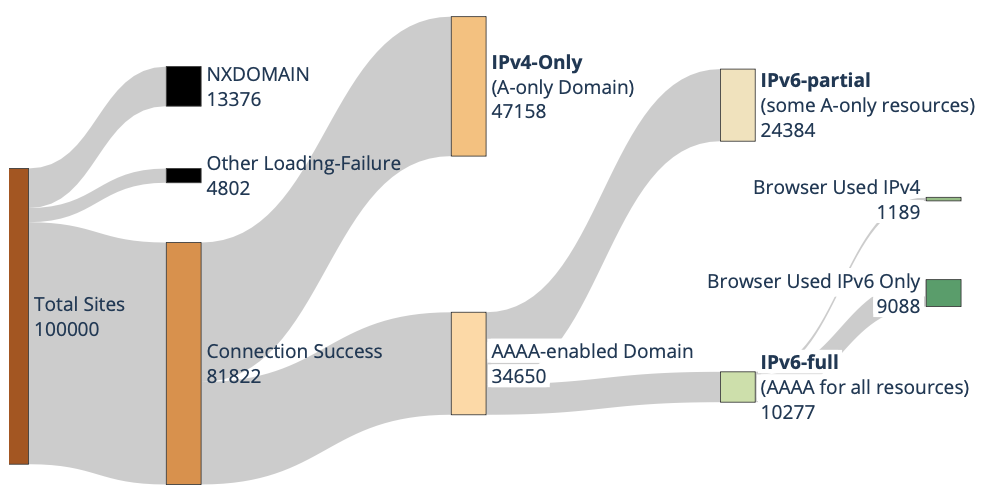
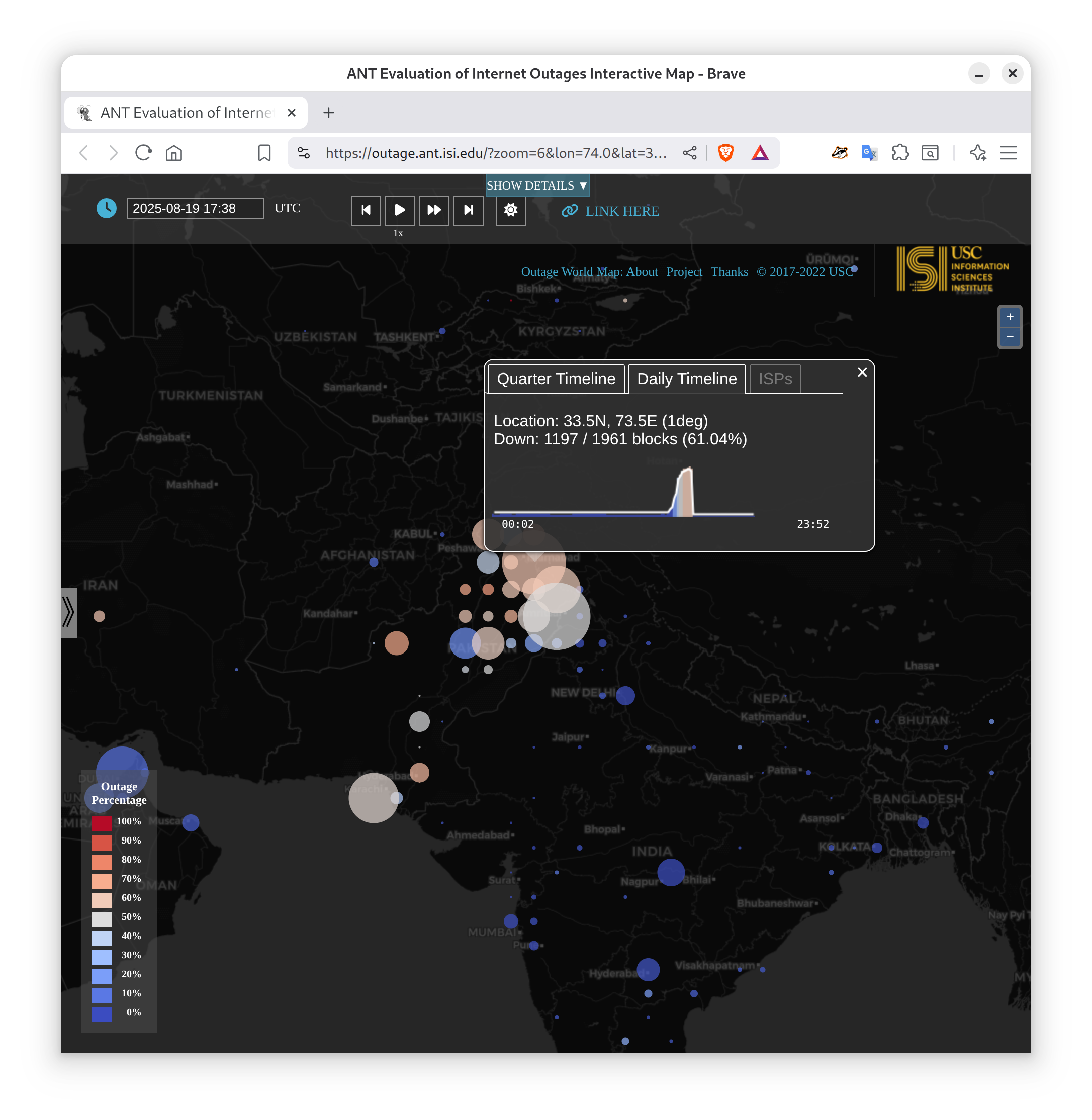
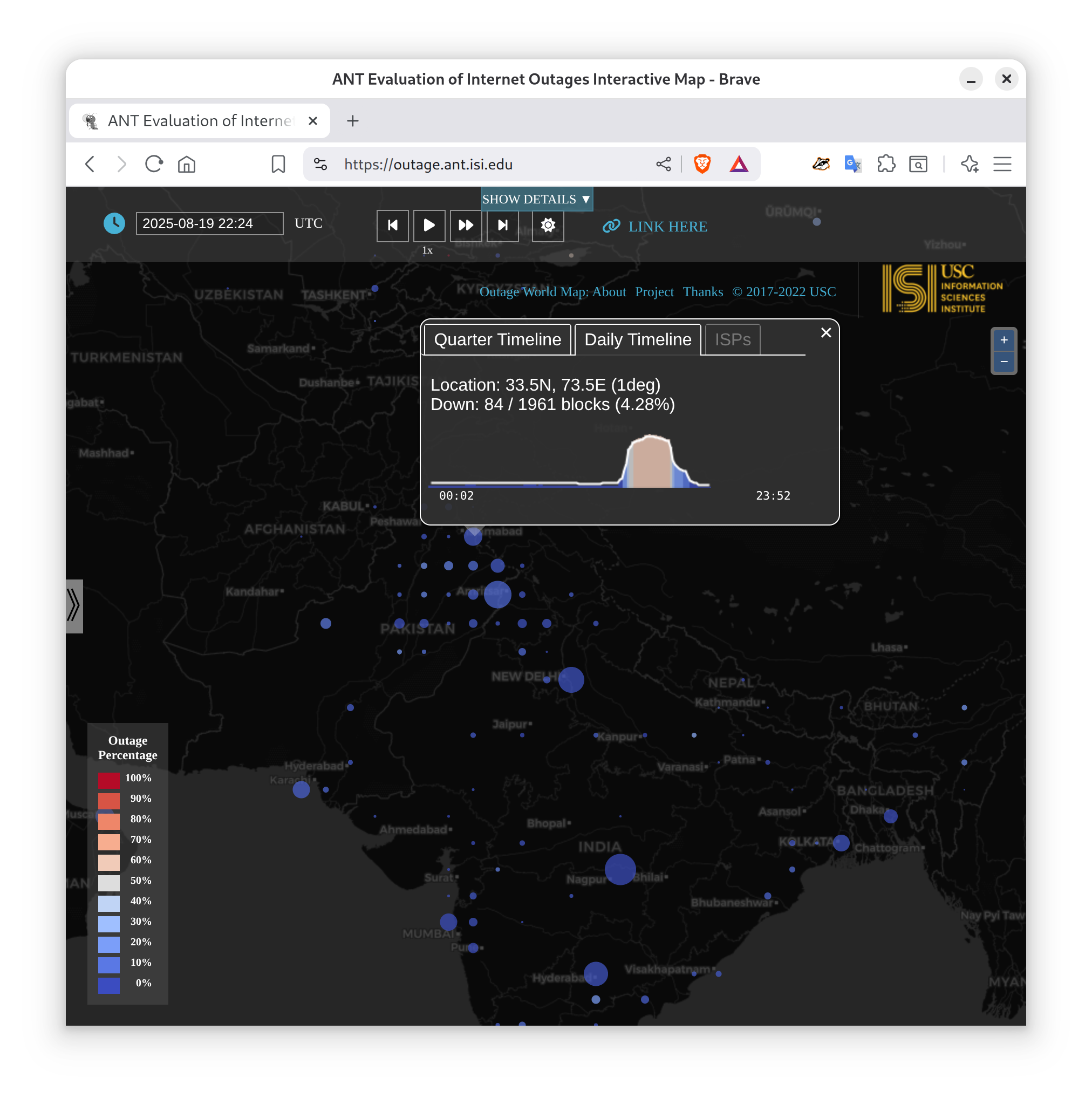
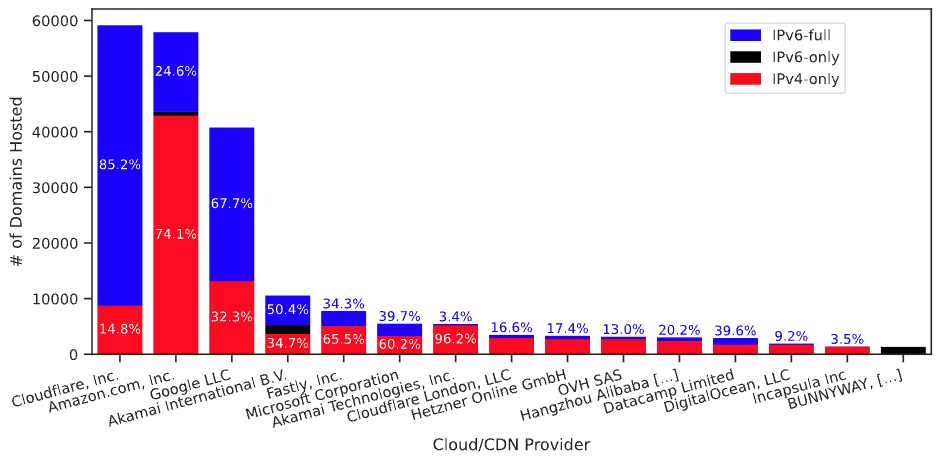
Routing strives to connect all the Internet, but compete: political pressure threatens routing fragmentation; architectural changes such as private clouds, carrier-grade NAT, and firewalls make connectivity conditional; and commercial disputes create partial reachability for days or years. This paper suggests persistent, partial reachability is fundamental to the Internet and an underexplored problem. We first derive a conceptual definition of the Internet core based on connectivity, not authority. We identify peninsulas: persistent, partial connectivity; and islands: when computers are partitioned from the Internet core. Second, we develop algorithms to observe each across the Internet, and apply them to two existing measurement systems: Trinocular, where 6 locations observe 5M networks frequently, and RIPE Atlas, where 13k locations scan the DNS roots frequently. Cross-validation shows our findings are stable over three years of data, and consistent with as few as 3 geographically-distributed observers. We validate peninsulas and islands against CAIDA Ark, showing good recall (0.94) and bounding precision between 0.42 and 0.82. Finally, our work has broad practical impact: we show that peninsulas are more common than Internet outages. Factoring out peninsulas and islands as noise can improve existing measurement systems; their “noise” is 5x to 9.7x larger than the operational events in RIPE’s DNSmon. We show that most peninsula events are routing transients (45%), but most peninsula-time (90%) is due to a few (7%) long-lived events. Our work helps inform Internet policy and governance, with our neutral definition showing no single country or organization can unilaterally control the Internet core.
A technical report with additional appendices is available from our website and arXiv.
This paper is joint work of Guillermo Baltra, Tarak Saluja, Yuri Pradkin, and John Heidemann, building on work begun when Guillermo was a PhD student at USC and Tarak was a summer undergraduate researcher visiting USC from Swarthmore College.
The work is supported by NSF via the EIEIO, MINCEQ, Internet Map, and BRIPOD projects, and by DARPA via AQUARIUS.
Data created from the work is available at ANT, and the input and validation data is available from ANT, RIPE Atlas, and CAIDA.