I would like to congratulate Dr. Liang Zhu for defending his PhD in August 2018 and completing his doctoral dissertation “Balancing Security and Performance of Network Request-Response Protocols” in September 2018.

From the abstract:
The Internet has become a popular tool to acquire information and knowledge. Usually information retrieval on the Internet depends on request-response protocols, where clients and servers exchange data. Despite of their wide use, request-response protocols bring challenges for security and privacy. For example, source-address spoofing enables denial-of-service (DoS) attacks, and eavesdropping of unencrypted data leaks sensitive information in request-response protocols. There is often a trade-off between security and performance in request-response protocols. More advanced protocols, such as Transport Layer Security (TLS), are proposed to solve these problems of source spoofing and eavesdropping. However, developers often avoid adopting those advanced protocols, due to performance costs such as client latency and server memory requirement. We need to understand the trade-off between security and performance for request-response protocols and find a reasonable balance, instead of blindly prioritizing one of them.
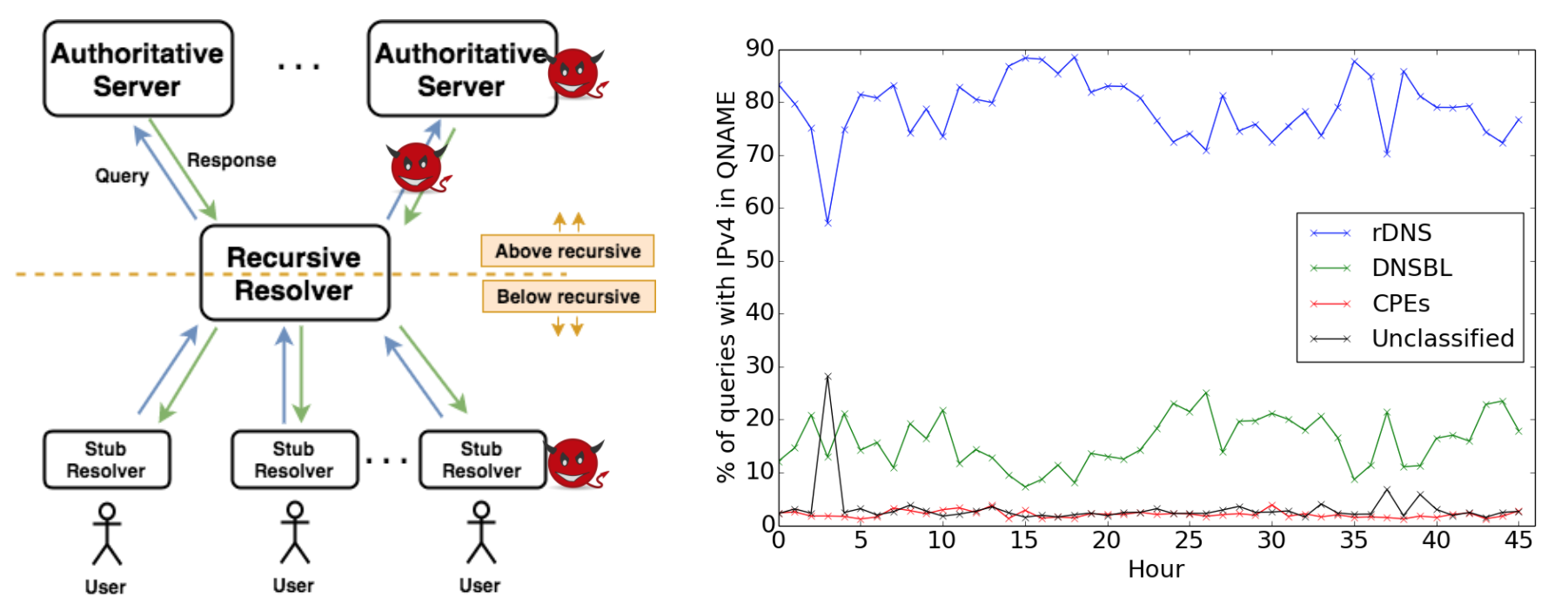
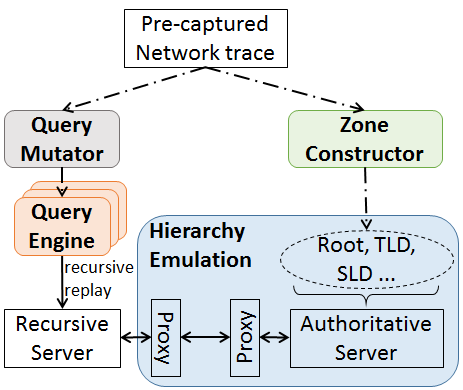
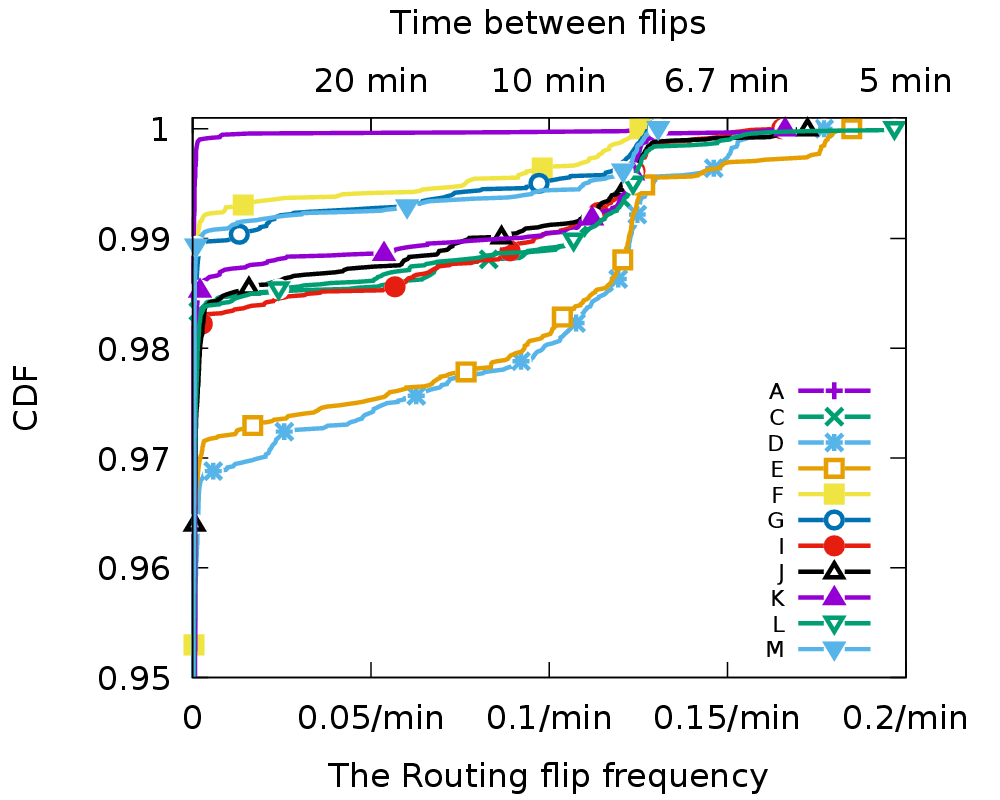
This thesis of this dissertation states that it is possible to improve security of network request-response protocols without compromising performance, by protocol and deployment optimizations, that are demonstrated through measurements of protocol developments and deployments. We support the thesis statement through three specific studies, each of which uses measurements and experiments to evaluate the development and optimization of a request-response protocol. We show that security benefits can be achieved with modest performance costs. In the first study, we measure the latency of OCSP in TLS connections. We show that OCSP has low latency due to its wide use of CDN and caching, while identifying certificate revocation to secure TLS. In the second study, we propose to use TCP and TLS for DNS to solve a range of fundamental problems in DNS security and privacy. We show that DNS over TCP and TLS can achieve favorable performance with selective optimization. In the third study, we build a configurable, general-purpose DNS trace replay system that emulates global DNS hierarchy in a testbed and enables DNS experiments at scale efficiently. We use this system to further prove the reasonable performance of DNS over TCP and TLS at scale in the real world.In addition to supporting our thesis, our studies have their own research contributions. Specifically, In the first work, we conducted new measurements of OCSP by examining network traffic of OCSP and showed a significant improvement of OCSP latency: a median latency of only 20ms, much less than the 291ms observed in prior work. We showed that CDN serves 94% of the OCSP traffic and OCSP use is ubiquitous. In the second work, we selected necessary protocol and implementation optimizations for DNS over TCP/TLS, and suggested how to run a production TCP/TLS DNS server [RFC7858]. We suggested appropriate connection timeouts for DNS operations: 20s at authoritative servers and 60s elsewhere. We showed that the cost of DNS over TCP/TLS can be modest. Our trace analysis showed that connection reuse can be frequent (60%-95% for stub and recursive resolvers). We showed that server memory is manageable (additional 3.6GB for a recursive server), and latency of connection-oriented DNS is acceptable (9%-22% slower than UDP). In the third work, we showed how to build a DNS experimentation framework that can scale to emulate a large DNS hierarchy and replay large traces. We used this experimentation framework to explore how traffic volume changes (increasing by 31%) when all DNS queries employ DNSSEC. Our DNS experimentation framework can benefit other studies on DNS performance evaluations.