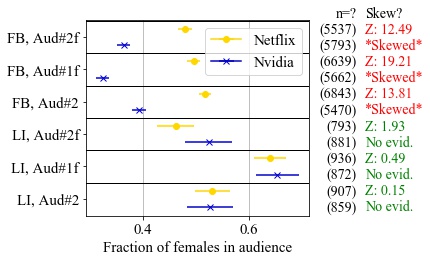
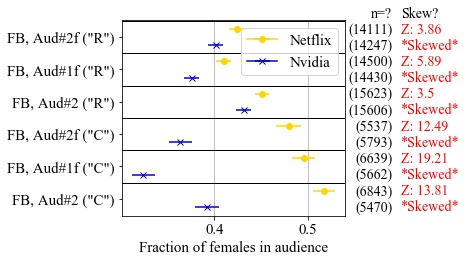
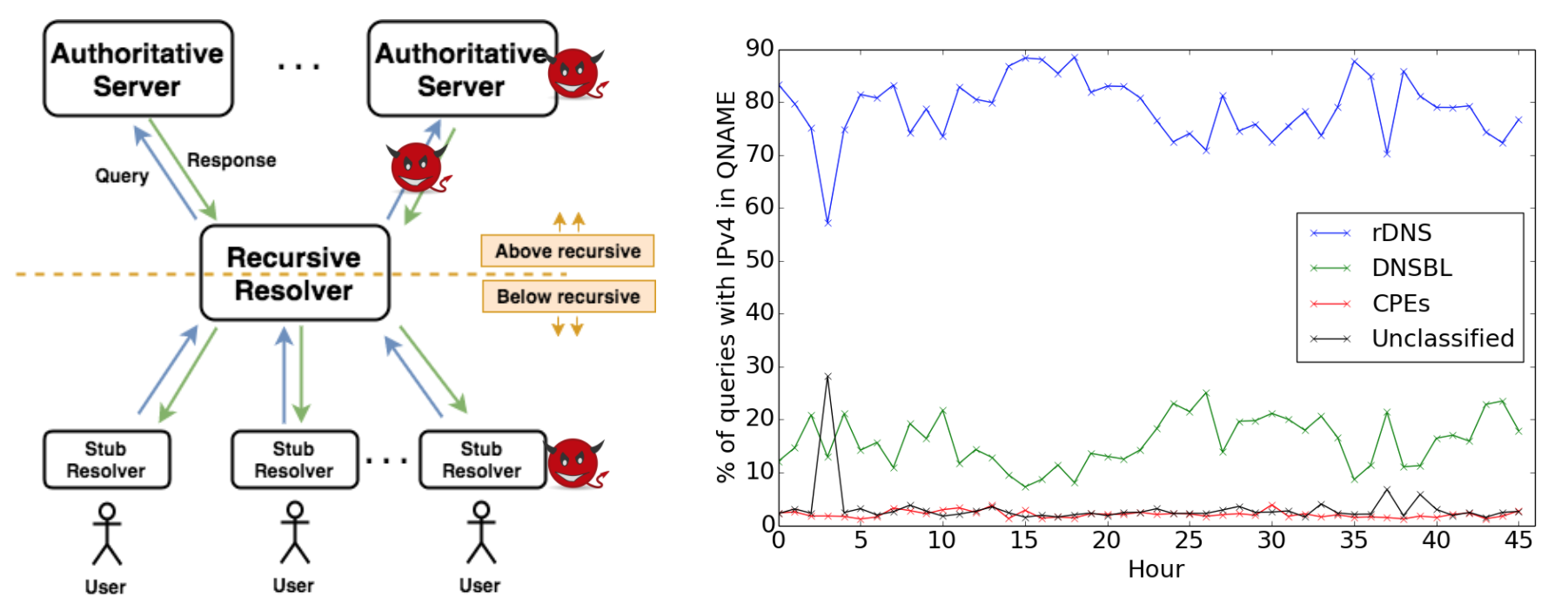
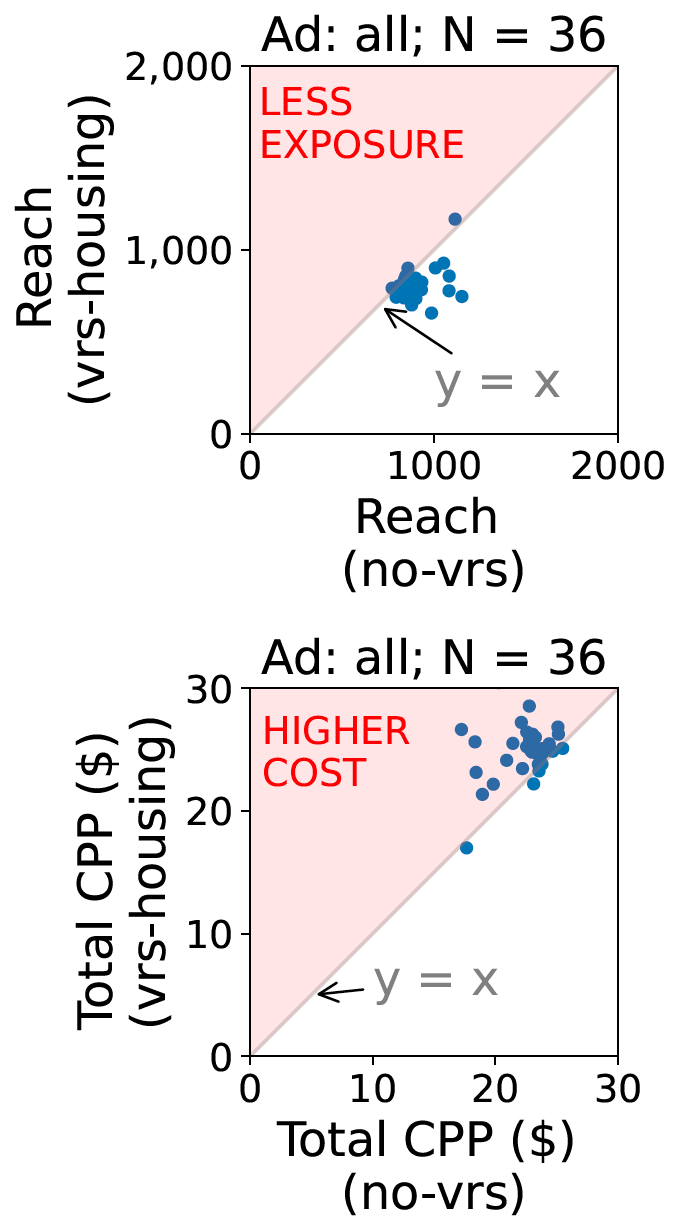
Our new paper “External Evaluation of Discrimination Mitigation Efforts in Meta’s Ad Delivery” (PDF) will appear at The eighth annual ACM FAccT conference (FAccT 2025) being held from June 23-26, 2025 in Athens, Greece.
We are happy to note that this paper was awarded Best Paper, one of the three best paper awards at FAccT 2025!
From the abstract:
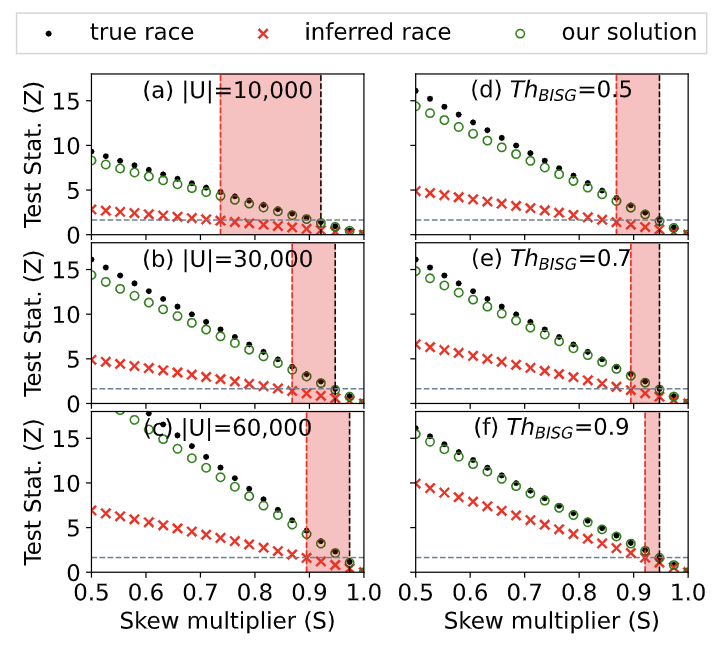
The 2022 settlement between Meta and the U.S. Department of Justice to resolve allegations of discriminatory advertising resulted is a first-of-its-kind change to Meta’s ad delivery system aimed to address algorithmic discrimination in its housing ad delivery. In this work, we explore direct and indirect effects of both the settlement’s choice of terms and the Variance Reduction System (VRS) implemented by Meta on the actual reduction in discrimination. We first show that the settlement terms allow for an implementation that does not meaningfully improve access to opportunities for individuals. The settlement measures impact of ad delivery in terms of impressions, instead of unique individuals reached by an ad; it allows the platform to level down access, reducing disparities by decreasing the overall access to opportunities; and it allows the platform to selectively apply VRS to only small advertisers. We then conduct experiments to evaluate VRS with real-world ads, and show that while VRS does reduce variance, it also raises advertiser costs (measured per-individuals-reached), therefore decreasing user exposure to opportunity ads for a given ad budget. VRS thus passes the cost of decreasing variance to advertisers}. Finally, we explore an alternative approach to achieve the settlement goals, that is significantly more intuitive and transparent than VRS. We show our approach outperforms VRS by both increasing ad exposure for users from all groups and reducing cost to advertisers, thus demonstrating that the increase in cost to advertisers when implementing the settlement is not inevitable. Our methodologies use a black-box approach that relies on capabilities available to any regular advertiser, rather than on privileged access to data, allowing others to reproduce or extend our work.
All data in this paper is publicly available to researchers at our datasets webpage.
This paper is a joint work of Basileal Imana, Zeyu Shen, and Aleksandra Korolova from Princeton University, and John Heidemann from USC/ISI. This work was supported in part by NSF grants CNS-1956435, CNS-2344925, and CNS-2319409.