We will publish a new paper titled “Anycast Agility: Network Playbooks to Fight DDoS” by A S M Rizvi (USC/ISI), Leandro Bertholdo (University of Twente), João Ceron (SIDN Labs), and John Heidemann (USC/ISI) at the 31st USENIX Security Symposium in Aug. 2022.
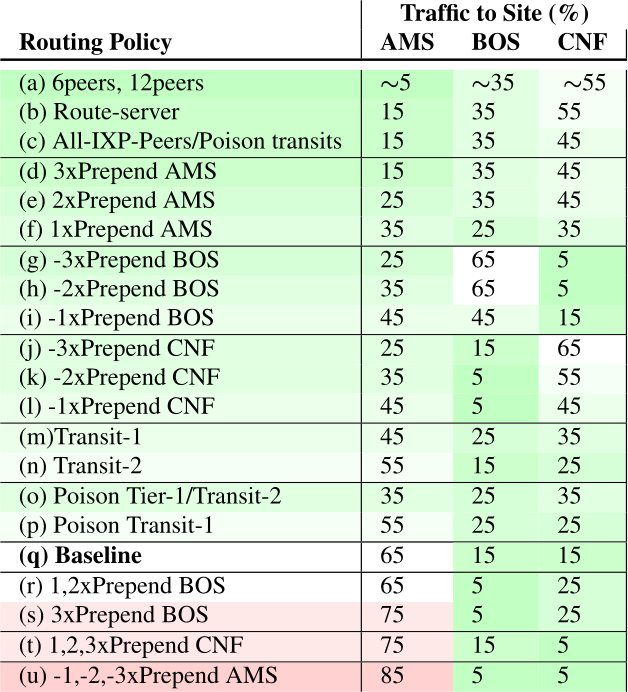
A sample anycast playbook for a 3-site anycast deployment. Different routing configurations provide different traffic mixes. From [Rizvi22a, Table 5].
From the abstract:
IP anycast is used for services such as DNS and Content Delivery Networks (CDN) to provide the capacity to handle Distributed Denial-of-Service (DDoS) attacks. During a DDoS attack service operators redistribute traffic between anycast sites to take advantage of sites with unused or greater capacity. Depending on site traffic and attack size, operators may instead concentrate attackers in a few sites to preserve operation in others. Operators use these actions during attacks, but how to do so has not been described systematically or publicly. This paper describes several methods to use BGP to shift traffic when under DDoS, and shows that a response playbook can provide a menu of responses that are options during an attack. To choose an appropriate response from this playbook, we also describe a new method to estimate true attack size, even though the operator’s view during the attack is incomplete. Finally, operator choices are constrained by distributed routing policies, and not all are helpful. We explore how specific anycast deployment can constrain options in this playbook, and are the first to measure how generally applicable they are across multiple anycast networks.
Acknowledgments: A S M Rizvi and John Heidemann’s work on this paper is supported, in part, by the DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I. Joao Ceron and Leandro Bertholdo’s work on this paper is supported by Netherlands Organisation for scientific research (4019020199), and European Union’s Horizon 2020 research and innovation program (830927). We would like to thank our anonymous reviewers for their valuable feedback. We are also grateful to the Peering and Tangled admins who allowed us to run measurements. We thank Dutch National Scrubbing Center for sharing DDoS data with us. We also thank Yuri Pradkin for his help to release our datasets.
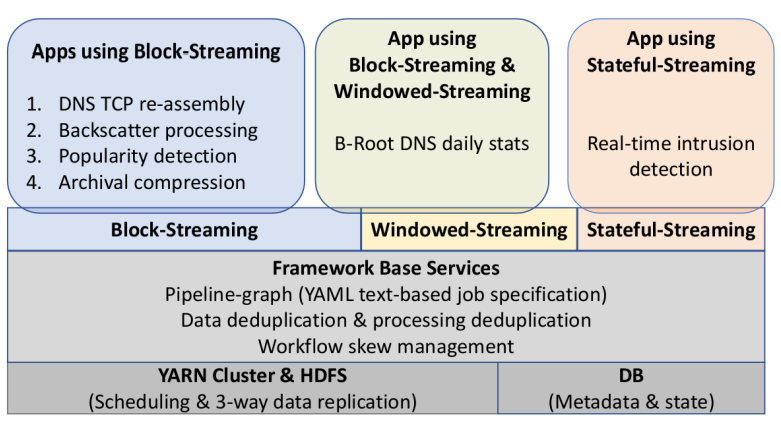
We show that one framework can efficiently support multiple abstractions. We provide three abstractions of Block, Windowed, and Stateful streaming and demonstrate that many application classes can be developed with ease, correctness, and low processing latency.
From the abstract of our paper:
Large websites and distributed systems employ sophisticated analytics to evaluate successes to celebrate and problems to be addressed. As analytics grow, different teams often require different frameworks, with dozens of packages supporting with streaming and batch processing, SQL and no-SQL. Bringing multiple frameworks to bear on a large, changing dataset often create challenges where data transitions—these impedance mismatches can create brittle glue logic and performance problems that consume developer time. We propose Plumb, a meta-framework that can bridge three different abstractions to meet the needs of a large class of applications in a common workflow. Large-block streaming (Block-Streaming) is suitable for single-pass applications that care about the temporal and spatial locality. Windowed-Streaming allows applications to process a group of data and many reductions. Stateful-Streaming enables applications to keep a long-term state and always-on behavior. We show that it is possible to bridge abstractions, with a common, high-level workflow specification, while the system transitions data batch processing and block- and record-level streaming as required. The challenge in bridging abstractions is to minimize latency while allowing applications to select between sequential and parallel operation, while handling out-of-order data delivery, component failures, and providing clear semantics in the face of missing data. We demonstrate these abstractions evaluating a 10-stage workflow of DNS analytics that has been in production use with Plumb for 2 years, comparing to a brittle hand-built system that has run for more than 3 years.
This conference paper is joint work of Abdul Qadeer and John Heidemann from USC/ISI.
We have published a new journal paper “Plumb: Efficient Stream Processing of Multi-User Pipelines” in Wiley’s Journal of Software: Practice and Experience, available at https://onlinelibrary.wiley.com/doi/10.1002/spe.2909
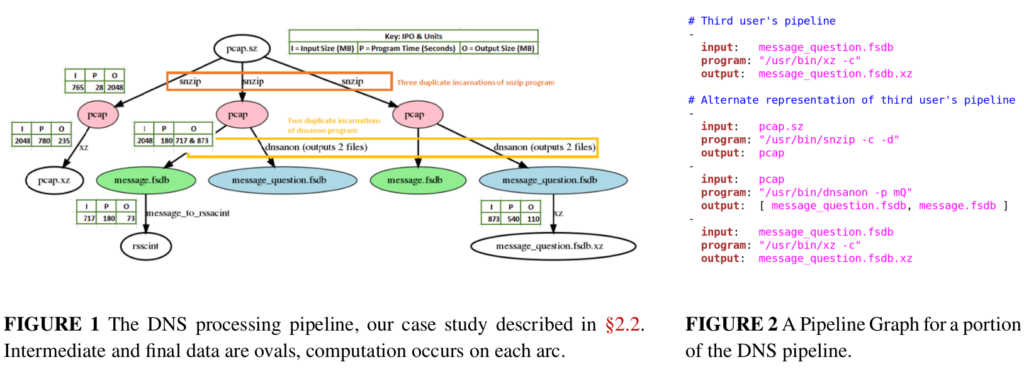
Plumb provides a new pipeline-graph abstraction that allows multiple users to specify workflows in which Plumb can detect and elimiate duplicate processing and handle processing skew due to unbalanced data or stages. The end result is that users get their results faster and a shared cluster is efficiently utilized.
From the abstract of our journal paper:
Operational services run 24×7 and require analytics pipelines to evaluate performance. In mature services such as DNS, these pipelines often grow to many stages developed by multiple, loosely-coupled teams. Such pipelines pose two problems: first, computation and data storage may be duplicated across components developed by different groups, wasting resources. Second, processing can be skewed, with structural skew occurring when different pipeline stages need different amounts of resources, and computational skew occurring when a block of input data requires increased resources. Duplication and structural skew both decrease efficiency, increasing cost, latency, or both. Computational skew can cause pipeline failure or deadlock when resource consumption balloons; we have seen cases where pessimal traffic increases CPU requirements 6-fold. Detecting duplication is challenging when components from multiple teams evolve independently and require fault isolation. Skew management is hard due to dynamic workloads coupled with the conflicting goals of both minimizing latency and maximizing utilization. We propose Plumb, a framework to abstract stream processing as large-block streaming (LBS) for a multi-stage, multi-user workflow. Plumb users express analytics as a DAG of processing modules, allowing Plumb to integrate and optimize workflows from multiple users. Many real-world applications map to the LBS abstraction. Plumb detects and eliminates duplicate computation and storage, and it detects and addresses both structural and computational skew by tracking computation across the pipeline. We exercise Plumb using the analytics pipeline for B-Root DNS. We compare Plumb to a hand-tuned system, cutting latency to one-third the original, and requiring 39% fewer container hours, while supporting more flexible, multi-user analytics and providing greater robustness to DDoS-driven demands.
This journal paper is joint work of Abdul Qadeer and John Heidemann from USC/ISI.
Plumb is open source software and we will be interested in beta testers. Please contact us if you think it would be useful to manage your workflows over one or a cluster of computers.
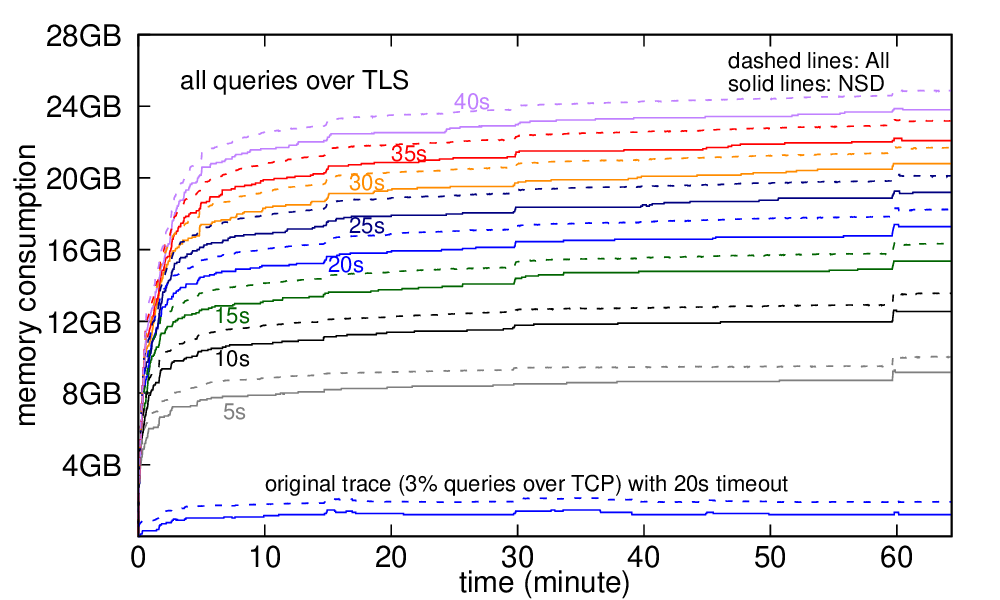
Figure 14a: Evaluation of server memory with different TCP timeouts and minimal RTT (<1 ms). Trace: B-Root-17a. Protocol: TLS
From the abstract:
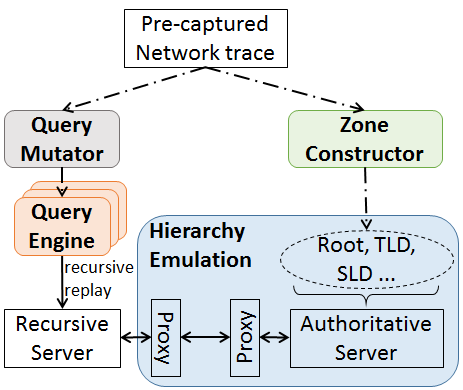
DNS has evolved over the last 20 years, improving in security and privacy and broadening the kinds of applications it supports. However, this evolution has been slowed by the large installed base and the wide range of implementations. The impact of changes is difficult to model due to complex interactions between DNS optimizations, caching, and distributed operation. We suggest that experimentation at scale is needed to evaluate changes and facilitate DNS evolution. This paper presents LDplayer, a configurable, general-purpose DNS experimental framework that enables DNS experiments to scale in several dimensions: many zones, multiple levels of DNS hierarchy, high query rates, and diverse query sources. LDplayer provides high fidelity experiments while meeting these requirements through its distributed DNS query replay system, methods to rebuild the relevant DNS hierarchy from traces, and efficient emulation of this hierarchy on minimal hardware. We show that a single DNS server can correctly emulate multiple independent levels of the DNS hierarchy while providing correct responses as if they were independent. We validate that our system can replay a DNS root traffic with tiny error (± 8 ms quartiles in query timing and ± 0.1% difference in query rate). We show that our system can replay queries at 87k queries/s while using only one CPU, more than twice of a normal DNS Root traffic rate. LDplayer’s trace replay has the unique ability to evaluate important design questions with confidence that we capture the interplay of caching, timeouts, and resource constraints. As an example, we demonstrate the memory requirements of a DNS root server with all traffic running over TCP and TLS, and identify performance discontinuities in latency as a function of client RTT.
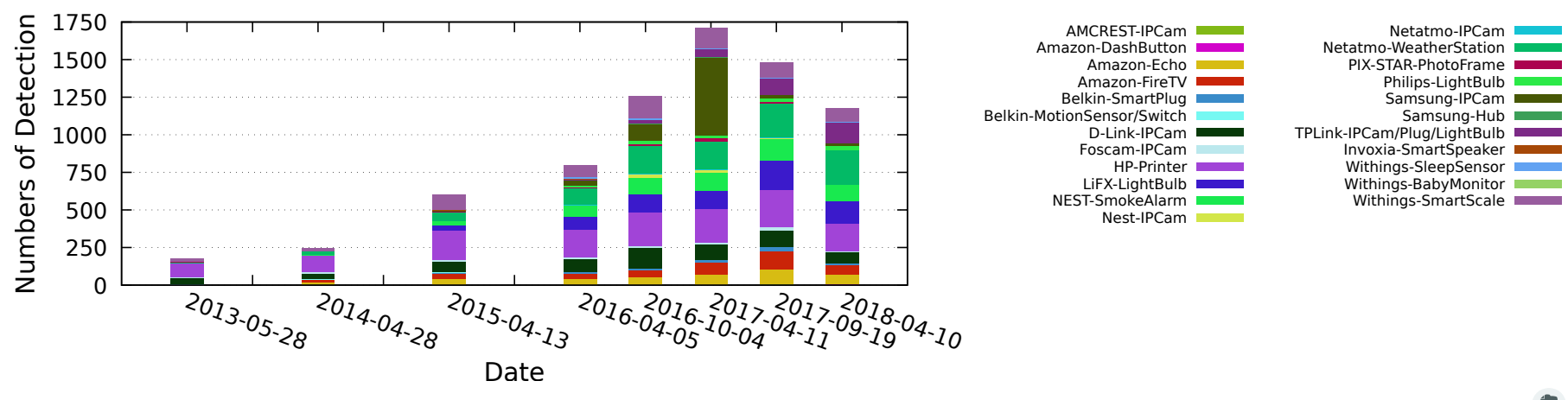
ISP-Level Deployment for 26 IoT Device Types. From Figure 2 of [Guo18c].From the abstract of our technical report:
Distributed Denial-of-Service (DDoS) attacks launched from compromised Internet-of-Things (IoT) devices have shown how vulnerable the Internet is to large-scale DDoS attacks. To understand the risks of these attacks requires learning about these IoT devices: where are they? how many are there? how are they changing? This paper describes three new methods to find IoT devices on the Internet: server IP addresses in traffic, server names in DNS queries, and manufacturer information in TLS certificates. Our primary methods (IP addresses and DNS names) use knowledge of servers run by the manufacturers of these devices. We have developed these approaches with 10 device models from 7 vendors. Our third method uses TLS certificates obtained by active scanning. We have applied our algorithms to a number of observations. Our IP-based algorithms see at least 35 IoT devices on a college campus, and 122 IoT devices in customers of a regional IXP. We apply our DNSbased algorithm to traffic from 5 root DNS servers from 2013 to 2018, finding huge growth (about 7×) in ISPlevel deployment of 26 device types. DNS also shows similar growth in IoT deployment in residential households from 2013 to 2017. Our certificate-based algorithm finds 254k IP cameras and network video recorders from 199 countries around the world.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This technical report is joint work of Hang Guo and John Heidemann from USC/ISI.
IoT devices we detect in use at a campus (Table 3 from [Guo18b])From the abstract of our paper:
Recent IoT-based DDoS attacks have exposed how vulnerable the Internet can be to millions of insufficiently secured IoT devices. To understand the risks of these attacks requires
learning about these IoT devices—where are they, how many are there, how are they changing? In this paper, we propose
a new method to find IoT devices in Internet to begin to assess this threat. Our approach requires observations of flow-level network traffic and knowledge of servers run by
the manufacturers of the IoT devices. We have developed our approach with 10 device models by 7 vendors and controlled
experiments. We apply our algorithm to observations from 6 days of Internet traffic at a college campus and partial traffic
from an IXP to detect IoT devices.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This paper is joint work of Hang Guo and John Heidemann from USC/ISI.
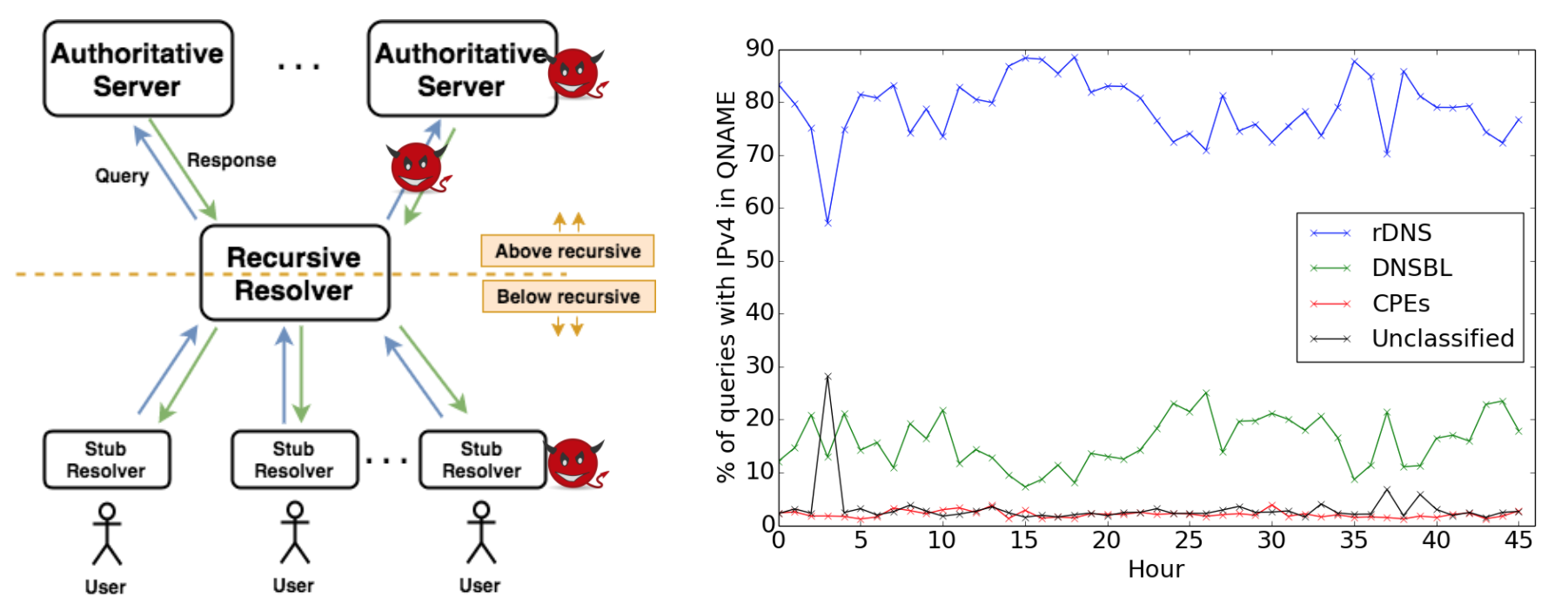
Threat model for enumerating leaks above the recursive (left). Percentage of four categories of queries containing IPv4 addresses in their QNAMEs. (right)
As with any information system consisting of data derived from people’s actions, DNS data is vulnerable to privacy risks. In DNS, users make queries through recursive resolvers to authoritative servers. Data collected below (or in) the recursive resolver directly exposes users, so most prior DNS data sharing focuses on queries above the recursive resolver. Data collected above a recursive resolver has largely been seen as posing a minimal privacy risk since recursive resolvers typically aggregate traffic for many users, thereby hiding their identity and mixing their traffic. Although this assumption is widely made, to our knowledge it has not been verified. In this paper we re-examine this assumption for DNS traffic above the recursive resolver. First, we show that two kinds of information appear in query names above the recursive resolver: IP addresses and sensitive domain names, such as those pertaining to health, politics, or personal or lifestyle information. Second, we examine how often these classes of potentially sensitive names appear in Root DNS traffic, using 48 hours of B-Root data from April 2017.
This is a joint work by Basileal Imana (USC), Aleksandra Korolova (USC) and John Heidemann (USC/ISI).
The DITL dataset (ITL_B_Root-20170411) used in this work is available from DHS IMPACT, the ANT project, and through DNS-OARC.
The LACANIC project’s goal is to develop datasets to improve Internet security and readability. We distribute these datasets through the DHS IMPACT program.
As part of this work we:
provide regular data collection to collect long-term, longitudinal data
curate datasets for special events
build websites and portals to help make data accessible to casual users
develop new measurement approaches
We provide several types of datasets:
anonymized packet headers and network flow data, often to document events like distributed denial-of-service (DDoS) attacks and regular traffic
Internet censuses and surveys for IPv4 to document address usage
Internet hitlists and histories, derived from IPv4 censuses, to support other topology studies
application data, like DNS and Internet-of-Things mapping, to document regular traffic and DDoS events
and we are developing other datasets
LACANIC allows us to continue some of the data collection we were doing as part of the LACREND project, as well as develop new methods and ways of sharing the data.
DNS has evolved over the last 20 years, improving in security and privacy and broadening the kinds of applications it supports. However, this evolution has been slowed by the large installed base with a wide range of implementations that are slow to change. Changes need to be carefully planned, and their impact is difficult to model due to DNS optimizations, caching, and distributed operation. We suggest that experimentation at scale is needed to evaluate changes and speed DNS evolution. This paper presents LDplayer, a configurable, general-purpose DNS testbed that enables DNS experiments to scale in several dimensions: many zones, multiple levels of DNS hierarchy, high query rates, and diverse query sources. LDplayer provides high fidelity experiments while meeting these requirements through its distributed DNS query replay system, methods to rebuild the relevant DNS hierarchy from traces, and efficient emulation of this hierarchy of limited hardware. We show that a single DNS server can correctly emulate multiple independent levels of the DNS hierarchy while providing correct responses as if they were independent. We validate that our system can replay a DNS root traffic with tiny error (+/- 8ms quartiles in query timing and +/- 0.1% difference in query rate). We show that our system can replay queries at 87k queries/s, more than twice of a normal DNS Root traffic rate, maxing out one CPU core used by our customized DNS traffic generator. LDplayer’s trace replay has the unique ability to evaluate important design questions with confidence that we capture the interplay of caching, timeouts, and resource constraints. As an example, we can demonstrate the memory requirements of a DNS root server with all traffic running over TCP, and we identified performance discontinuities in latency as a function of client RTT.