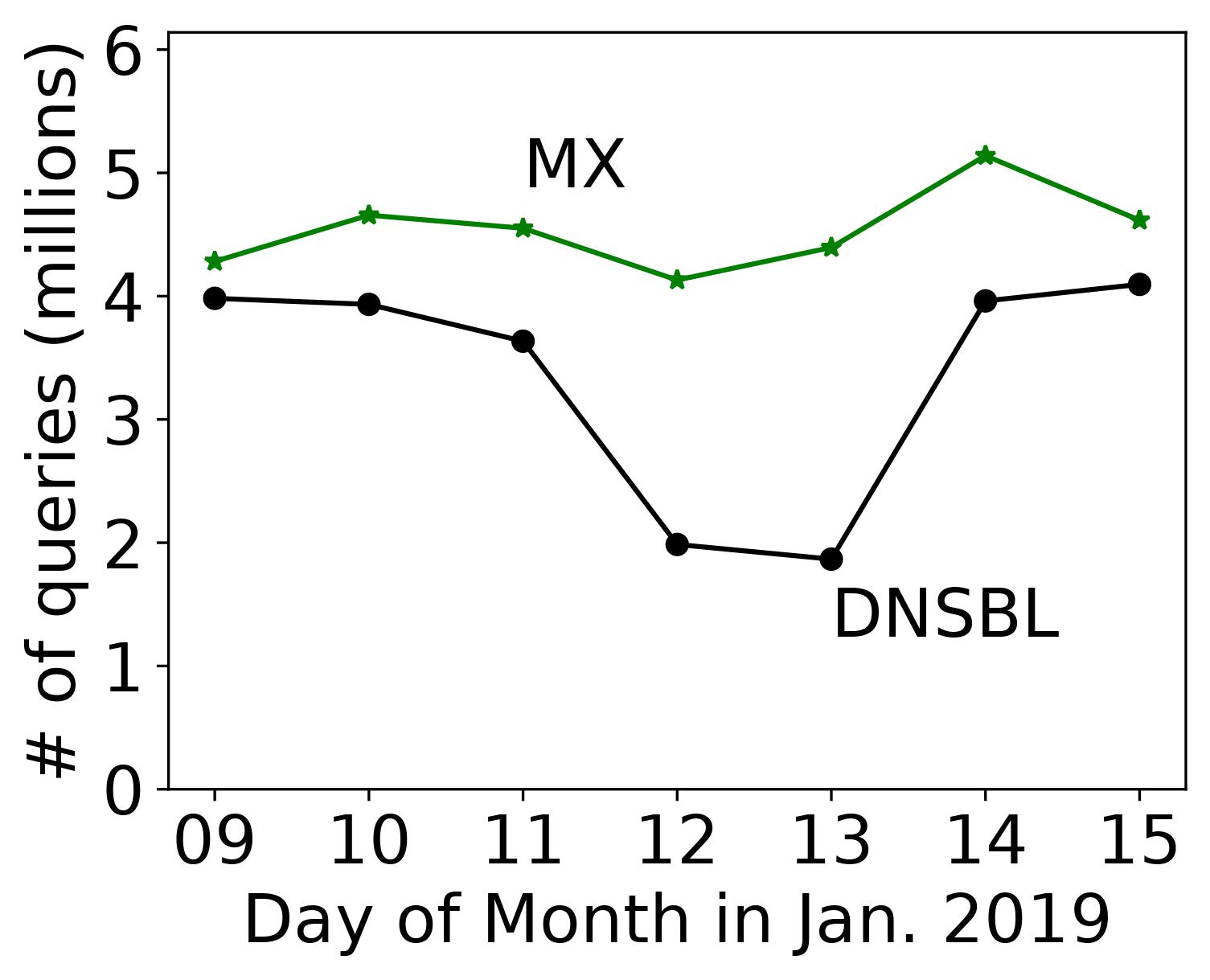
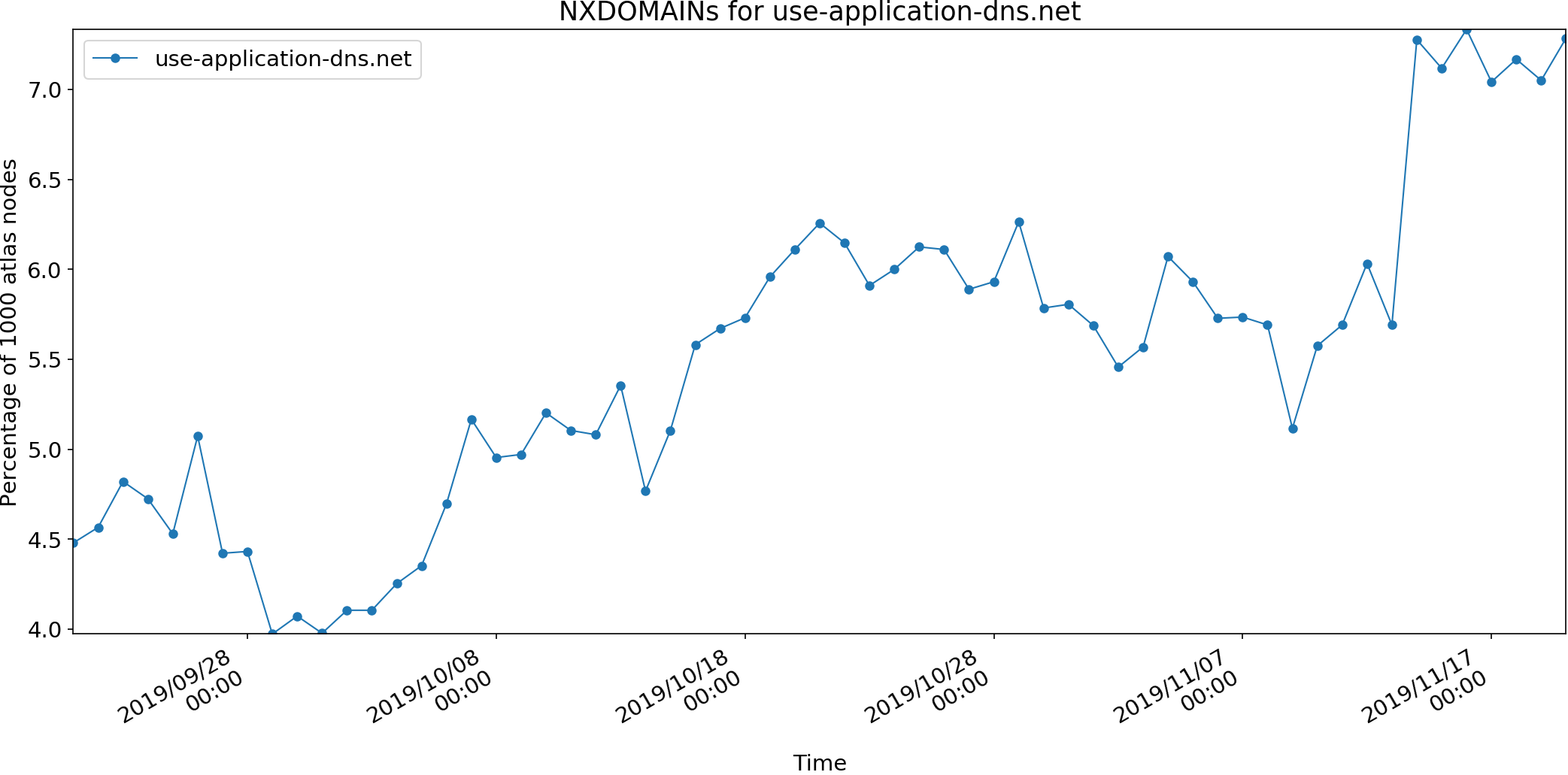
Our paper titled “Defending Root DNS Servers Against DDoS Using Layered Defenses” will appear at COMSNETS 2023 in January 2023. In this work, by ASM Rizvi, Jelena Mirkovic, John Heidemann, Wes Hardaker, and Robert Story, we design an automated system named DDIDD with multiple filters to handle an ongoing DDoS attack on a DNS root server. We evaluated ten real-world attack events on B-root and showed DDIDD could successfully mitigate these attack events. We released the datasets for these attack events on our dataset webpage (dataset names starting with B_Root_Anomaly).
Update in January: we are happy to announce that this paper was awarded Best Paper for COMSNETS 2023! Thanks for the recognition.
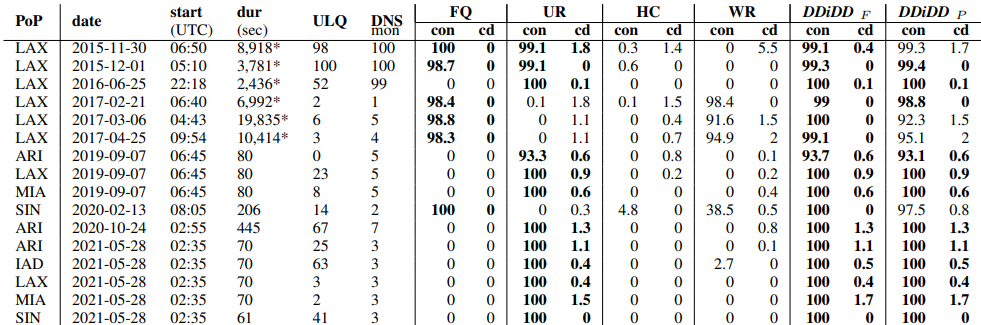
From the abstract:
Distributed Denial-of-Service (DDoS) attacks exhaust resources, leaving a server unavailable to legitimate clients. The Domain Name System (DNS) is a frequent target of DDoS attacks. Since DNS is a critical infrastructure service, protecting it from DoS is imperative. Many prior approaches have focused on specific filters or anti-spoofing techniques to protect generic services. DNS root nameservers are more challenging to protect, since they use fixed IP addresses, serve very diverse clients and requests, receive predominantly UDP traffic that can be spoofed, and must guarantee high quality of service. In this paper we propose a layered DDoS defense for DNS root nameservers. Our defense uses a library of defensive filters, which can be optimized for different attack types, with different levels of selectivity. We further propose a method that automatically and continuously evaluates and selects the best combination of filters throughout the attack. We show that this layered defense approach provides exceptional protection against all attack types using traces of real attacks from a DNS root nameserver. Our automated system can select the best defense within seconds and quickly reduce the traffic to the server within a manageable range while keeping collateral damage lower than 2%. We can handle millions of filtering rules without noticeable operational overhead.
This work is partially supported by the National Science
Foundation (grant NSF OAC-1739034) and DHS HSARPA
Cyber Security Division (grant SHQDC-17-R-B0004-TTA.02-
0006-I), in collaboration with NWO.