The paper “Quantifying Differences Between Batch and Streaming Detection of Internet Outages” will appear in the 2025 Conference on Network Traffic Measurement and Analysis (TMA) June 10-13, 2025 in Copenhagen, Denmark. The batch and streaming datasets are available for download.
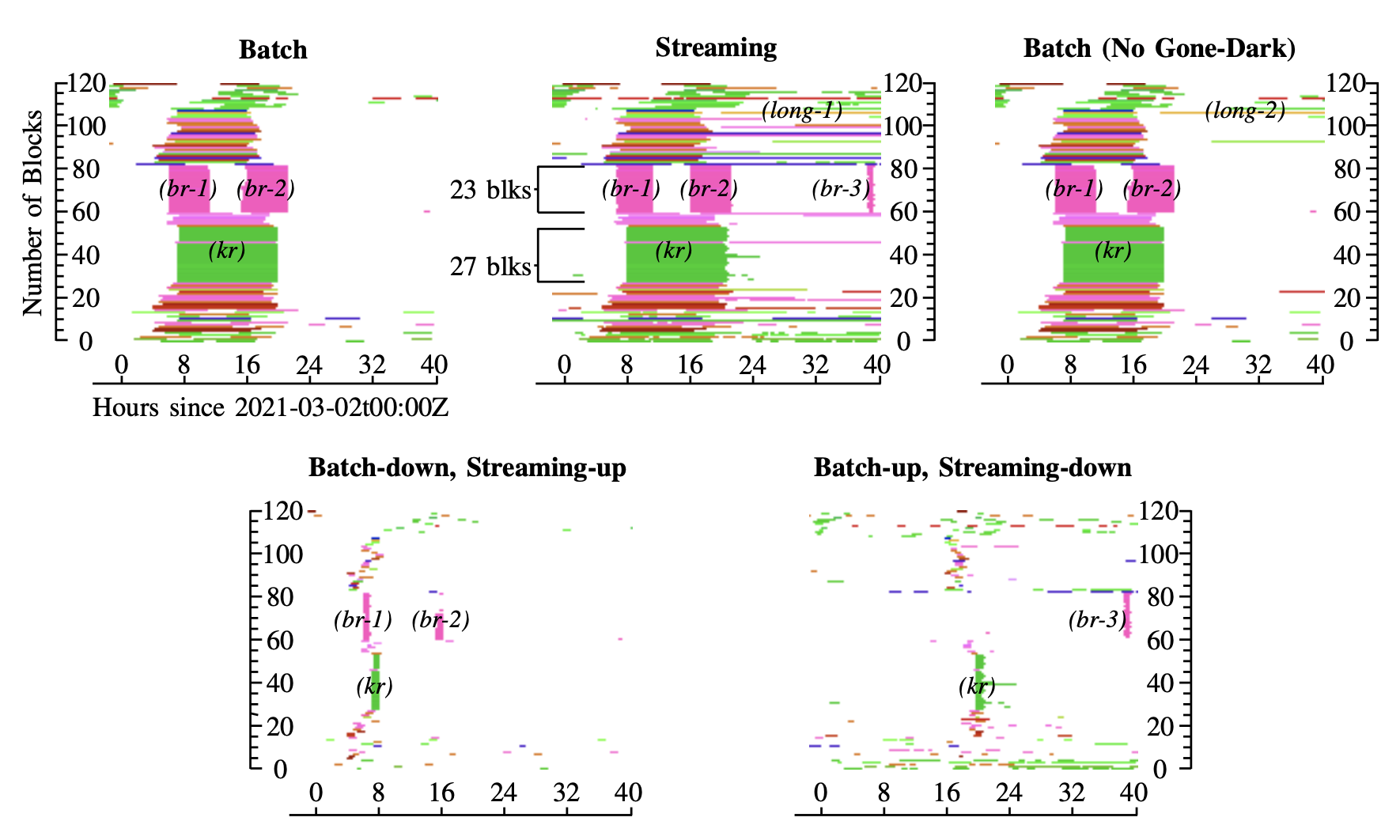
From the paper’s abstract:
A number of different systems today detect outages
in the IPv4 Internet, often using active probing and algorithms
based on Trinocular’s Bayesian inference. Outage detection
methods have evolved, both to provide results in near-real-time,
and adding algorithms to account for important but less common
cases that might otherwise be misinterpreted. We compare two
implementations of active outage detection to see how choices
to optimize for near-real-time results with streaming compare
to designs that use long-term information to maximize accuracy
using batch processing. Examining 8 days of data, starting on
2021-02-26, we show that the two similar systems agree most of
the time, more than 84%. We show that only 0.2% of the time the
algorithms disagree, and 15% of the time only one reports. We
show these differences occur due to streaming’s requirement for
rapid decisions, precluding algorithms that consider long-term
data (days or weeks). These results are important to understand
the trade-offs that occur when balancing timely results with
accuracy. Beyond the two systems we compare, our results
suggest the role that algorithmic differences can have in similar
but different systems, such as the several implementations of
Trinocular-like active probing today.
Live data from Trinocular streams in to our outage website 24×7. The specific data used in this paper is available from our website.
This work is partially supported by the project “CNS Core: Small: Event Identification and Evaluation of Internet Outages (EIEIO)” (CNS-2007106) through the U.S. National Science Foundation, and by an REU supplement to that project. Erica Stutz began this work at Swarthmore College, working remotely for the University of Southern California; her current affiliation is Yale University.
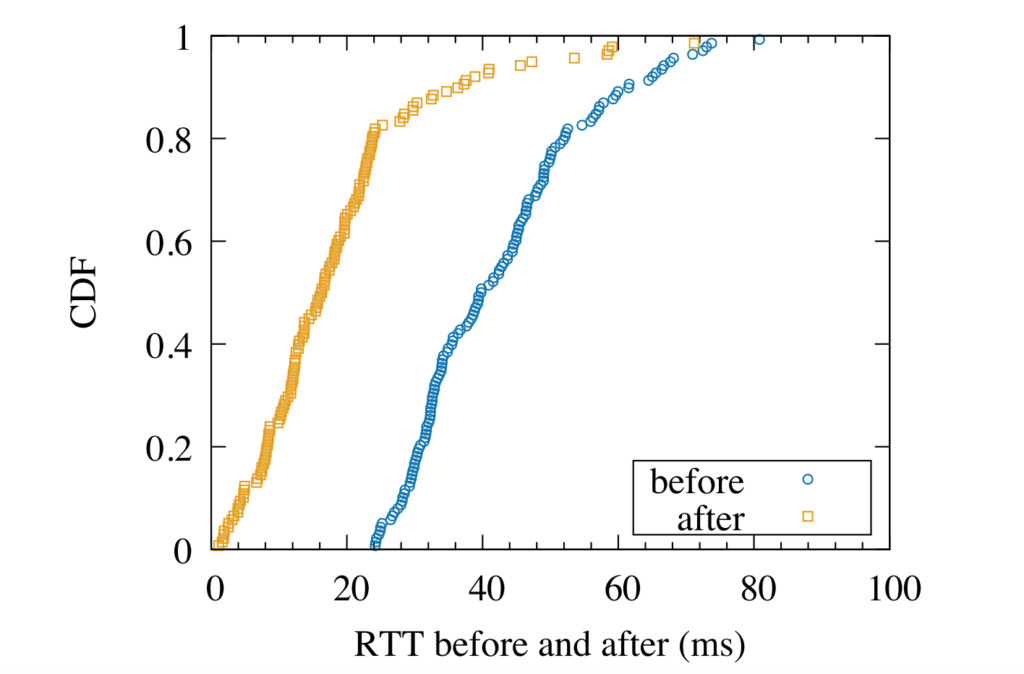
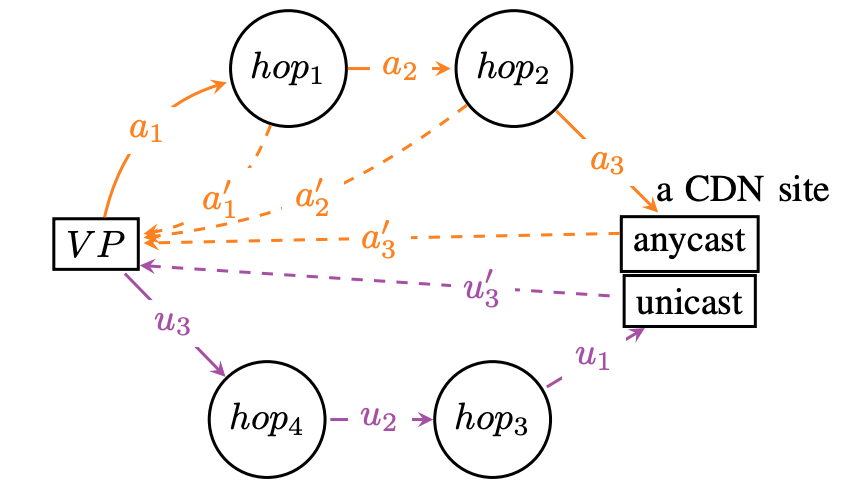
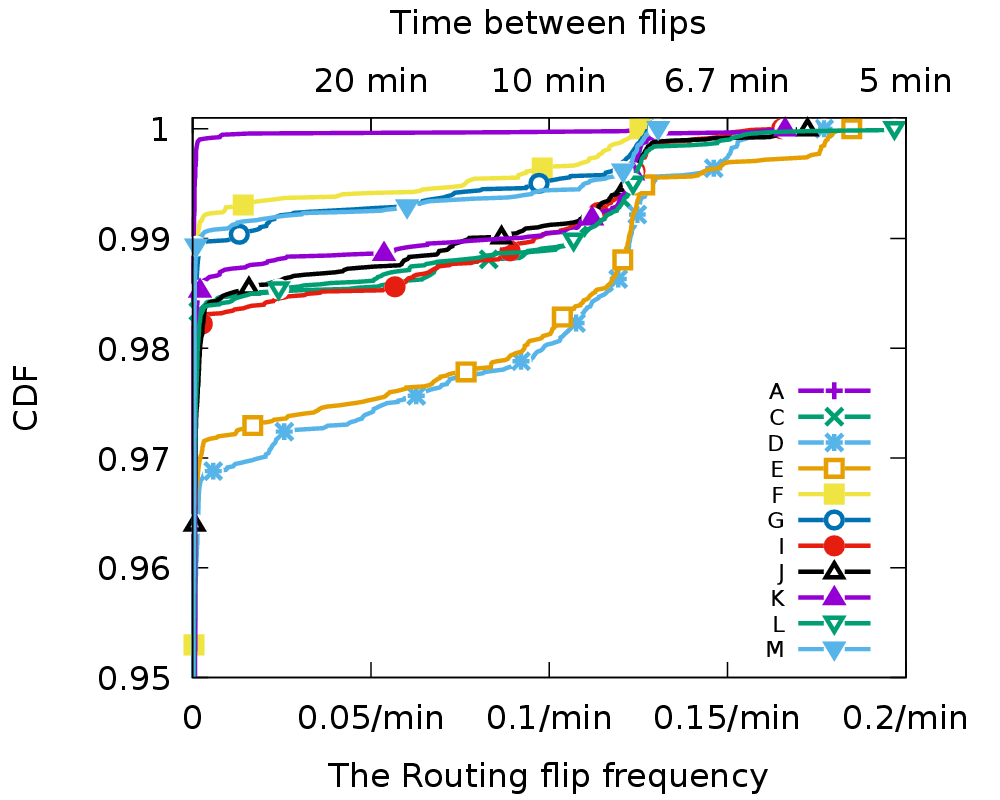
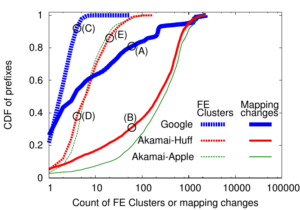 Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.
Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.