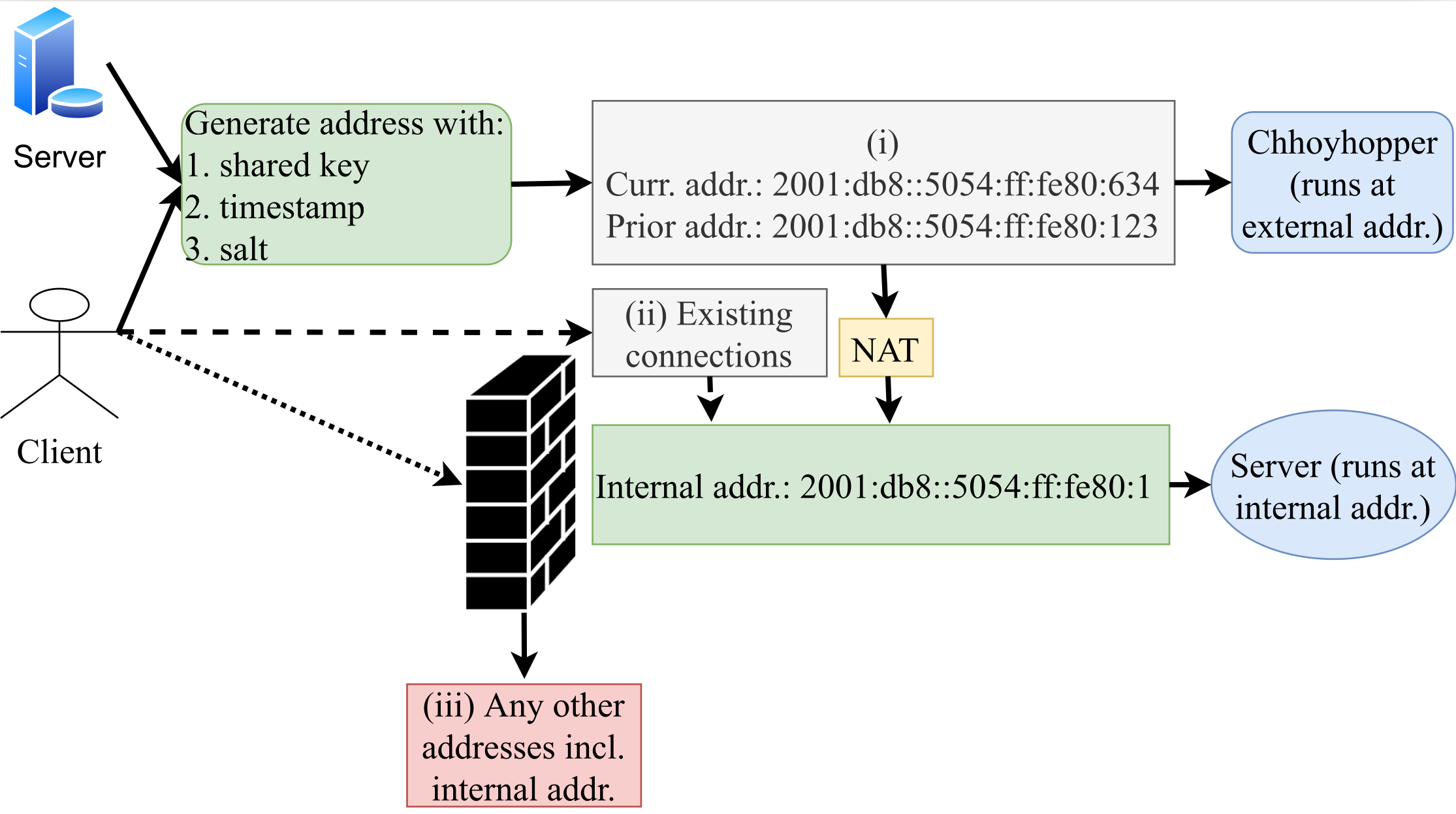
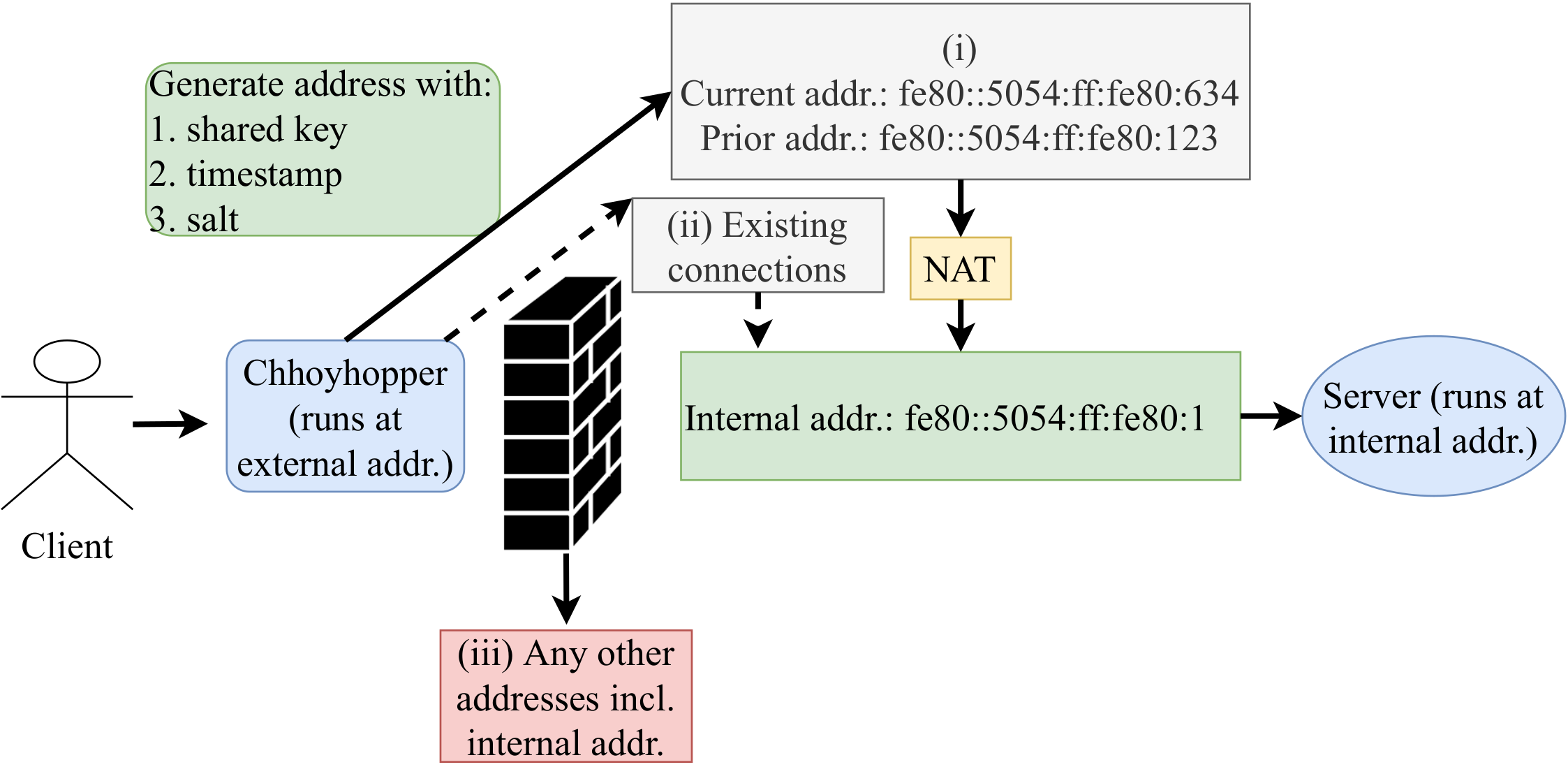
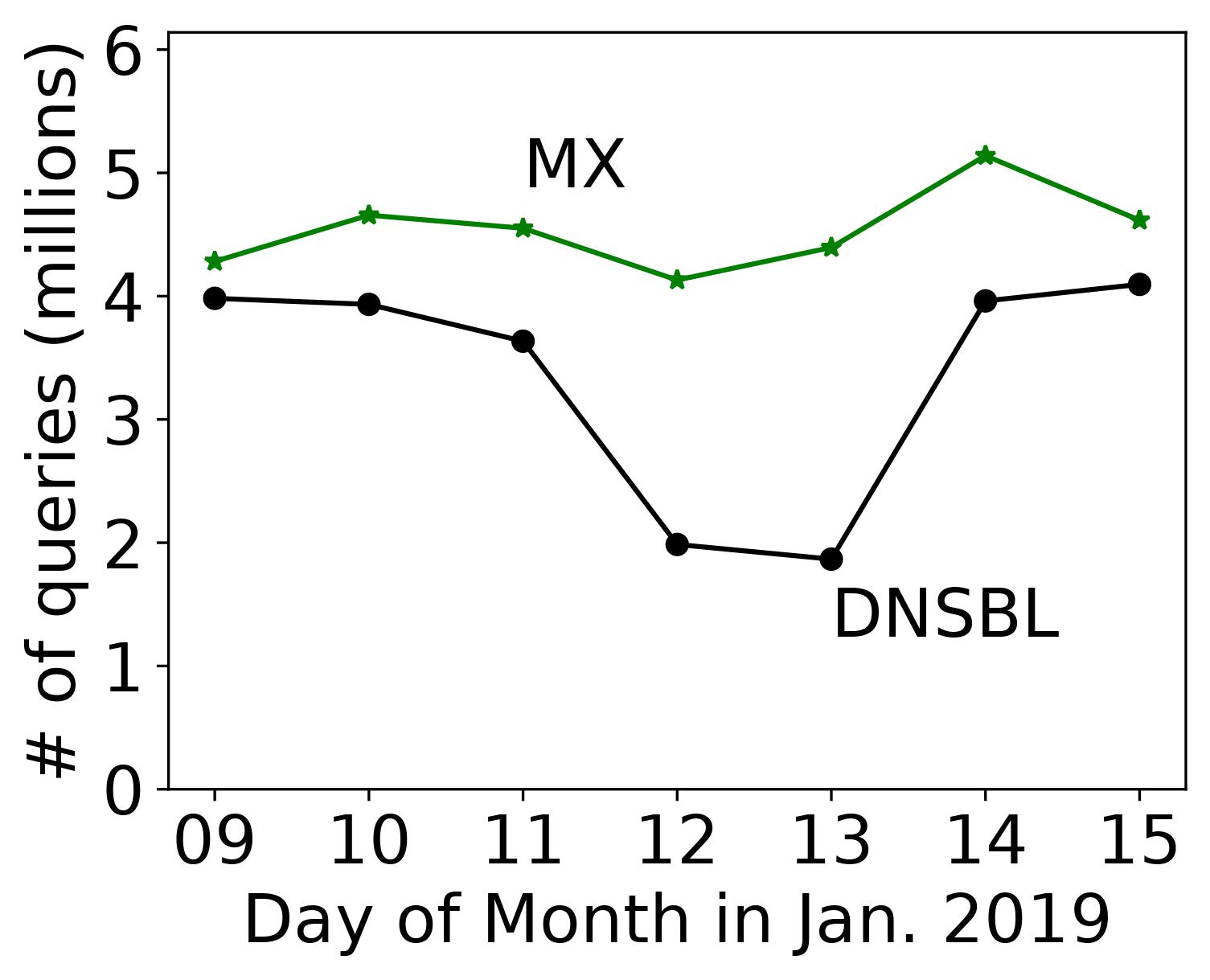
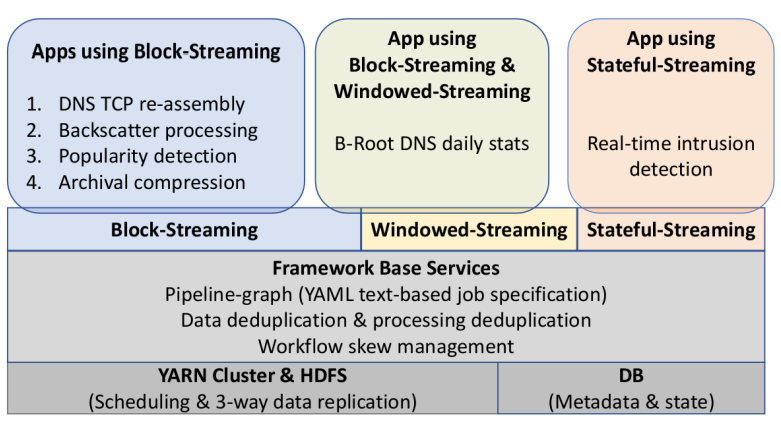
I would like to congratulate Dr. Lan Wei for defending her PhD in September 2020 and completing her doctoral dissertation “Anycast Stability, Security and Latency in The Domain Name System (DNS) and Content Deliver Networks (CDNs)” in December 2020.
From the abstract:
Clients’ performance is important for both Content-Delivery Networks (CDNs) and the Domain Name System (DNS). Operators would like the service to meet expectations of their users. CDNs providing stable connections will prevent users from experiencing downloading pause from connection breaks. Users expect DNS traffic to be secure without being intercepted or injected. Both CDN and DNS operators care about a short network latency, since users can become frustrated by slow replies.
Many CDNs and DNS services (such as the DNS root) use IP anycast to bring content closer to users. Anycast-based services announce the same IP address(es) from globally distributed sites. In an anycast infrastructure, Internet routing protocols will direct users to a nearby site naturally. The path between a user and an anycast site is formed on a hop-to-hop basis—at each hop} (a network device such as a router), routing protocols like Border Gateway Protocol (BGP) makes the decision about which next hop to go to. ISPs at each hop will impose their routing policies to influence BGP’s decisions. Without globally knowing (also unable to modify) the distributed information of BGP routing table of every ISP on the path, anycast infrastructure operators are unable to predict and control in real-time which specific site a user will visit and what the routing path will look like. Also, any change in routing policy along the path may change both the path and the site visited by a user. We refer to such minimal control over routing towards an anycast service, the uncertainty of anycast routing. Using anycast spares extra traffic management to map users to sites, but can operators provide a good anycast-based service without precise control over the routing?
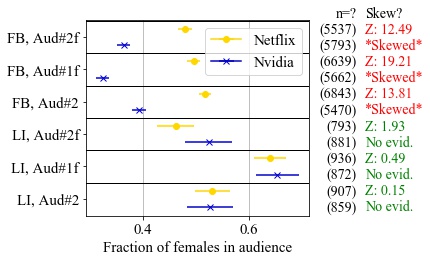
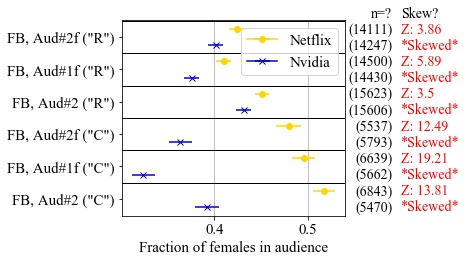
This routing uncertainty raises three concerns: routing can change, breaking connections; uncertainty about global routing means spoofing can go undetected, and lack of knowledge of global routing can lead to suboptimal latency. In this thesis, we show how we confirm the stability, how we confirm the security, and how we improve the latency of anycast to answer these three concerns. First, routing changes can cause users to switch sites, and therefore break a stateful connection such as a TCP connection immediately. We study routing stability and demonstrate that connections in anycast infrastructure are rarely broken by routing instability. Of all vantage points (VPs), fewer than 0.15% VP’s TCP connections frequently break due to timeout in 5s during all 17 hours we observed. We only observe such frequent TCP connection break in 1 service out of all 12 anycast services studied. A second problem is DNS spoofing, where a third-party can intercept the DNS query and return a false answer. We examine DNS spoofing to study two aspects of security–integrity and privacy, and we design an algorithm to detect spoofing and distinguish different mechanisms to spoof anycast-based DNS. We show that DNS spoofing is uncommon, happening to only 1.7% of all VPs, although increasing over the years. Among all three ways to spoof DNS–injections, proxies, and third-party anycast site (prefix hijack), we show that third-party anycast site is the least popular one. Last, diagnosing poor latency and improving the latency can be difficult for CDNs. We develop a new approach, BAUP (bidirectional anycast unicast probing), which detects inefficient routing with better routing replacement provided. We use BAUP to study anycast latency. By applying BAUP and changing peering policies, a commercial CDN is able to significantly reduce latency, cutting median latency in half from 40ms to 16ms for regional users.
Lan defended her PhD when USC was on work-from-home due to COVID-19; she is the third ANT student with a fully on-line PhD defense.