During the summer of 2019, Haoyu Jiang and Wes Hardaker studied the effects of DNS traffic sent to the root serevr system by chromium-based web browsers. The results of this short research effort were posted to the APNIC blog.
During the summer of 2019, Haoyu Jiang and Wes Hardaker studied the effects of DNS traffic sent to the root serevr system by chromium-based web browsers. The results of this short research effort were posted to the APNIC blog.
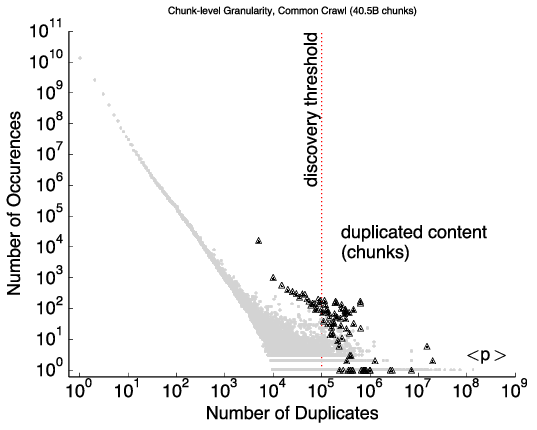
We have published a new paper “Precise Detection of Content Reuse in the Web” by Calvin Ardi and John Heidemann, in the ACM SIGCOMM Computer Communication Review (Volume 49 Issue 2, April 2019) newsletter.
From the abstract:
With vast amount of content online, it is not surprising that unscrupulous entities “borrow” from the web to provide content for advertisements, link farms, and spam. Our insight is that cryptographic hashing and fingerprinting can efficiently identify content reuse for web-size corpora. We develop two related algorithms, one to automatically discover previously unknown duplicate content in the web, and the second to precisely detect copies of discovered or manually identified content. We show that bad neighborhoods, clusters of pages where copied content is frequent, help identify copying in the web. We verify our algorithm and its choices with controlled experiments over three web datasets: Common Crawl (2009/10), GeoCities (1990s–2000s), and a phishing corpus (2014). We show that our use of cryptographic hashing is much more precise than alternatives such as locality-sensitive hashing, avoiding the thousands of false-positives that would otherwise occur. We apply our approach in three systems: discovering and detecting duplicated content in the web, searching explicitly for copies of Wikipedia in the web, and detecting phishing sites in a web browser. We show that general copying in the web is often benign (for example, templates), but 6–11% are commercial or possibly commercial. Most copies of Wikipedia (86%) are commercialized (link farming or advertisements). For phishing, we focus on PayPal, detecting 59% of PayPal-phish even without taking on intentional cloaking.
We released a new technical report “Web-scale Content Reuse Detection (extended)”, ISI-TR-2014-692, available at http://www.isi.edu/publications/trpublic/files/tr-692.pdf.
From the abstract:
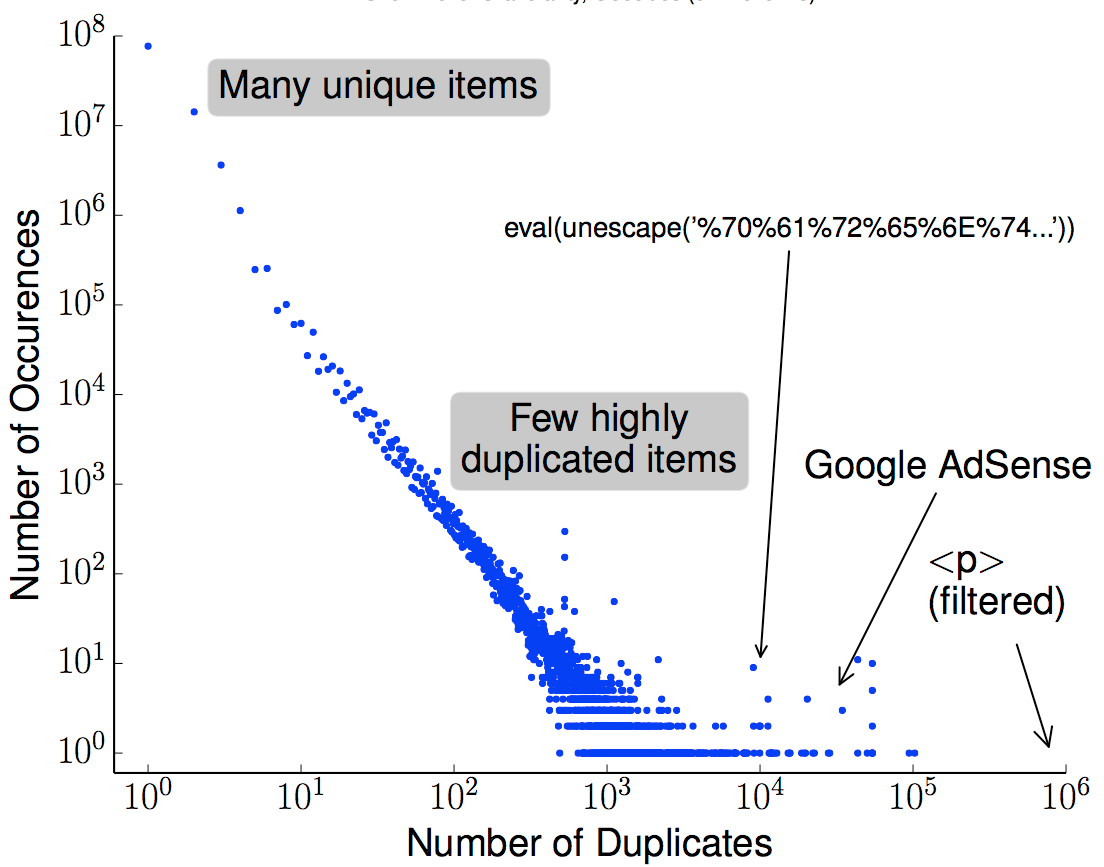
With the vast amount of accessible, online content, it is not surprising that unscrupulous entities “borrow” from the web to provide filler for advertisements, link farms, and spam and make a quick profit. Our insight is that cryptographic hashing and fingerprinting can efficiently identify content reuse for web-size corpora. We develop two related algorithms, one to automatically discover previously unknown duplicate content in the web, and the second to detect copies of discovered or manually identified content in the web. Our detection can also bad neighborhoods, clusters of pages where copied content is frequent. We verify our approach with controlled experiments with two large datasets: a Common Crawl subset the web, and a copy of Geocities, an older set of user-provided web content. We then demonstrate that we can discover otherwise unknown examples of duplication for spam, and detect both discovered and expert-identified content in these large datasets. Utilizing an original copy of Wikipedia as identified content, we find 40 sites that reuse this content, 86% for commercial benefit.