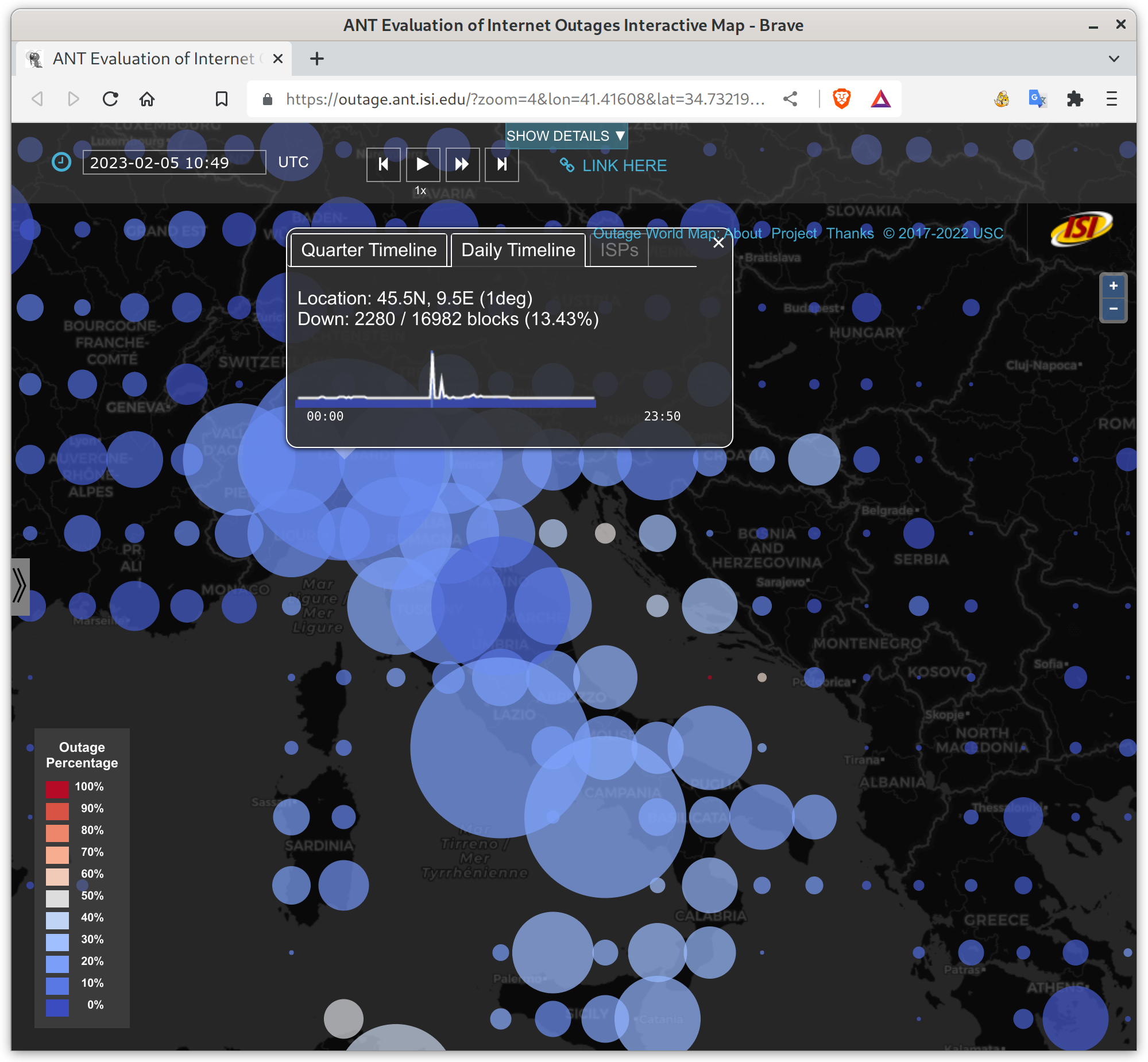
These outages were nation-wide, apparently affecting most of Italy. However, it looks like they “only” affected 20-30% of networks, and not all Italian ISPs. We’re happy they were able to recover so quickly.
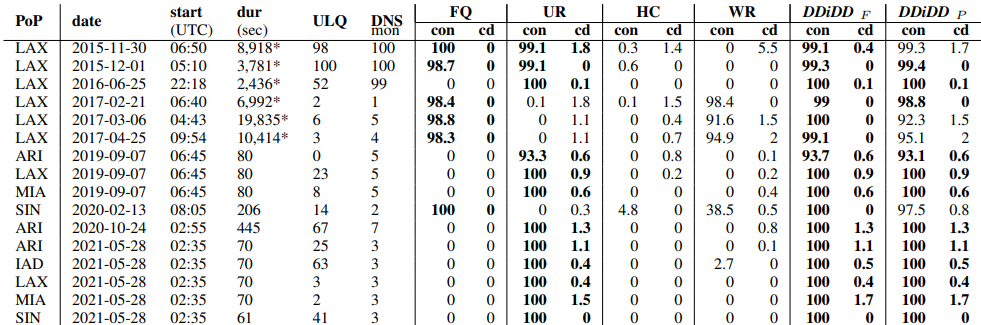
Table II from [Rizvi23a] shows the performance of each individual filter, with near-best results in bold. This table shows that one filter covers all cases, but together in DDIDD they provide very tood defense.
Our paper titled “Defending Root DNS Servers Against DDoS Using Layered Defenses” will appear at COMSNETS 2023 in January 2023. In this work, by ASM Rizvi, Jelena Mirkovic, John Heidemann, Wes Hardaker, and Robert Story, we design an automated system named DDIDD with multiple filters to handle an ongoing DDoS attack on a DNS root server. We evaluated ten real-world attack events on B-root and showed DDIDD could successfully mitigate these attack events. We released the datasets for these attack events on our dataset webpage (dataset names starting with B_Root_Anomaly).
Update in January: we are happy to announce that this paper was awarded Best Paper for COMSNETS 2023! Thanks for the recognition.
Table II from [Rizvi23a] shows the performance of each individual filter, with near-best results in bold. This table shows that one filter covers all cases, but together in DDIDD they provide very tood defense.
From the abstract:
Distributed Denial-of-Service (DDoS) attacks exhaust resources, leaving a server unavailable to legitimate clients. The Domain Name System (DNS) is a frequent target of DDoS attacks. Since DNS is a critical infrastructure service, protecting it from DoS is imperative. Many prior approaches have focused on specific filters or anti-spoofing techniques to protect generic services. DNS root nameservers are more challenging to protect, since they use fixed IP addresses, serve very diverse clients and requests, receive predominantly UDP traffic that can be spoofed, and must guarantee high quality of service. In this paper we propose a layered DDoS defense for DNS root nameservers. Our defense uses a library of defensive filters, which can be optimized for different attack types, with different levels of selectivity. We further propose a method that automatically and continuously evaluates and selects the best combination of filters throughout the attack. We show that this layered defense approach provides exceptional protection against all attack types using traces of real attacks from a DNS root nameserver. Our automated system can select the best defense within seconds and quickly reduce the traffic to the server within a manageable range while keeping collateral damage lower than 2%. We can handle millions of filtering rules without noticeable operational overhead.
This work is partially supported by the National Science Foundation (grant NSF OAC-1739034) and DHS HSARPA Cyber Security Division (grant SHQDC-17-R-B0004-TTA.02- 0006-I), in collaboration with NWO.
A screen capture of the presentation of the best paper award.
Figure 9 from [Saluja22a], showing fraction of query failures in RIPE Atlas after we remove observers that are islands (unable to reach any of the 13 DNS root identifiers). Blue is IPv4, red is IPv6, with data for each of the 13 DNS root identifiers. We believe this data is a better representation of what people expect to see than Atlas results that include these "broken" observers.
Figure 9 from [Saluja22a], showing fraction of query failures in RIPE Atlas after we remove observers that are islands (unable to reach any of the 13 DNS root identifiers). Blue is IPv4, red is IPv6, with data for each of the 13 DNS root identifiers. We believe this data is a better representation of what people expect to see than Atlas results that include these “broken” observers.
The Domain Name System (DNS) is an essential service for the Internet which maps host names to IP addresses. The DNS Root Sever System operates the top of this namespace. RIPE Atlas observes DNS from more than 11k vantage points (VPs) around the world, reporting the reliability of the DNS Root Server System in DNSmon. DNSmon shows that loss rates for queries to the DNS Root are nearly 10% for IPv6, much higher than the approximately 2% loss seen for IPv4. Although IPv6 is “new,” as an operational protocol available to a third of Internet users, it ought to be just as reliable as IPv4. We examine this difference at a finer granularity by investigating loss at individual VPs. We confirm that specific VPs are the source of this difference and identify two root causes: VP islands with routing problems at the edge which leave them unable to access IPv6 outside their LAN, and VP peninsulas which indicate routing problems in the core of the network. These problems account for most of the loss and nearly all of the difference between IPv4 and IPv6 query loss rates. Islands account for most of the loss (half of IPv4 failures and 5/6ths of IPv6 failures), and we suggest these measurement devices should be filtered out to get a more accurate picture of loss rates. Peninsulas account for the main differences between root identifiers, suggesting routing disagreements root operators need to address. We believe that filtering out both of these known problems provides a better measure of underlying network anomalies and loss and will result in more actionable alerts.
This work was done while Tarang was on his Summer 2022 undergraduate research internship at USC/ISI, with support from NSF grant 2051101 (PI: Jelena Mirkovich). John Heidemann and Yuri Pradkin’s work is supported by NSF through the EIEIO project (CNS-2007106). We thank Guillermo Baltra for his work on islands and peninsulas, as seen in his arXiv report.
Asma Enayet will present her poster “Internet Outage Detection Using Passive Analysis” by Asma Enayet and John Heidemann at ACM Internet Measurement Conference, Nice, France from October 25-27th, 2022.
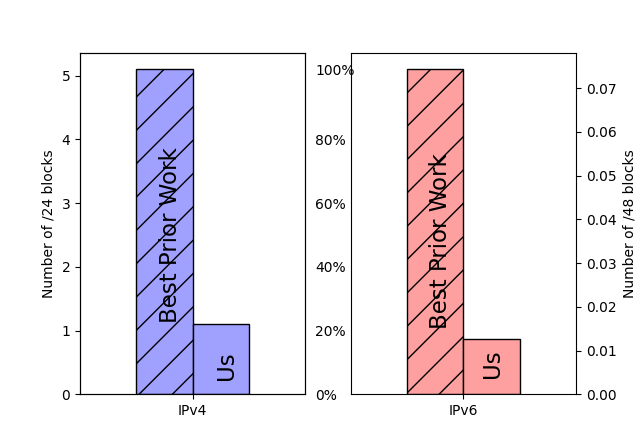
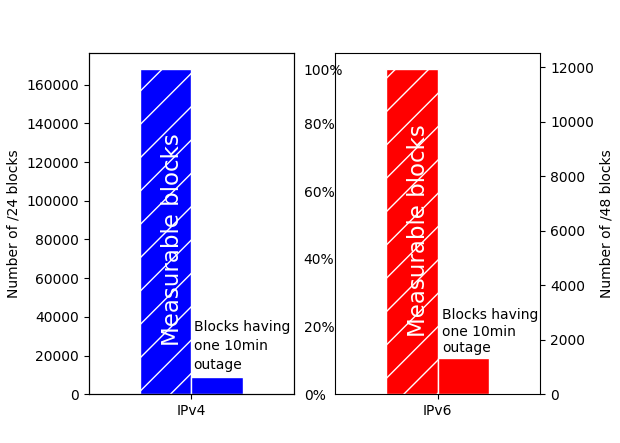
Outages from natural disasters, political events, software or hardware issues, and human error place a huge cost on e-commerce ($66k per minute at Amazon). While several existing systems detect Internet outages, these systems are often too inflexible, with fixed parameters across the whole internet with CUSUM-like change detection. We instead propose a system using passive data, to cover both IPv4 and IPv6, customizing parameters for each block to optimize the performance of our Bayesian inference model. Our poster describes our three contributions: First, we show how customizing parameters allows us often to detect outages that are at both fine timescales (5 minutes) and fine spatial resolutions (/24 IPv4 and /48 IPv6 blocks). Our second contribution is to show that, by tuning parameters differently for different blocks, we can scale back temporal precision to cover more challenging blocks. Finally, we show our approach extends to IPv6 and provides the first reports of IPv6 outages.
IPv6 Coverage: our source of passive data (B-Root) is incomplete, but it provides similar coverage in both IPv4 and IPv6.
IPv6 Outages: Outage rate for IPv6 (12%) is greater than for IPv4 (5.5%) —IPv6 reliability can improve.
This work was supported by NSF grant CNS-2007106 (EIEIO).
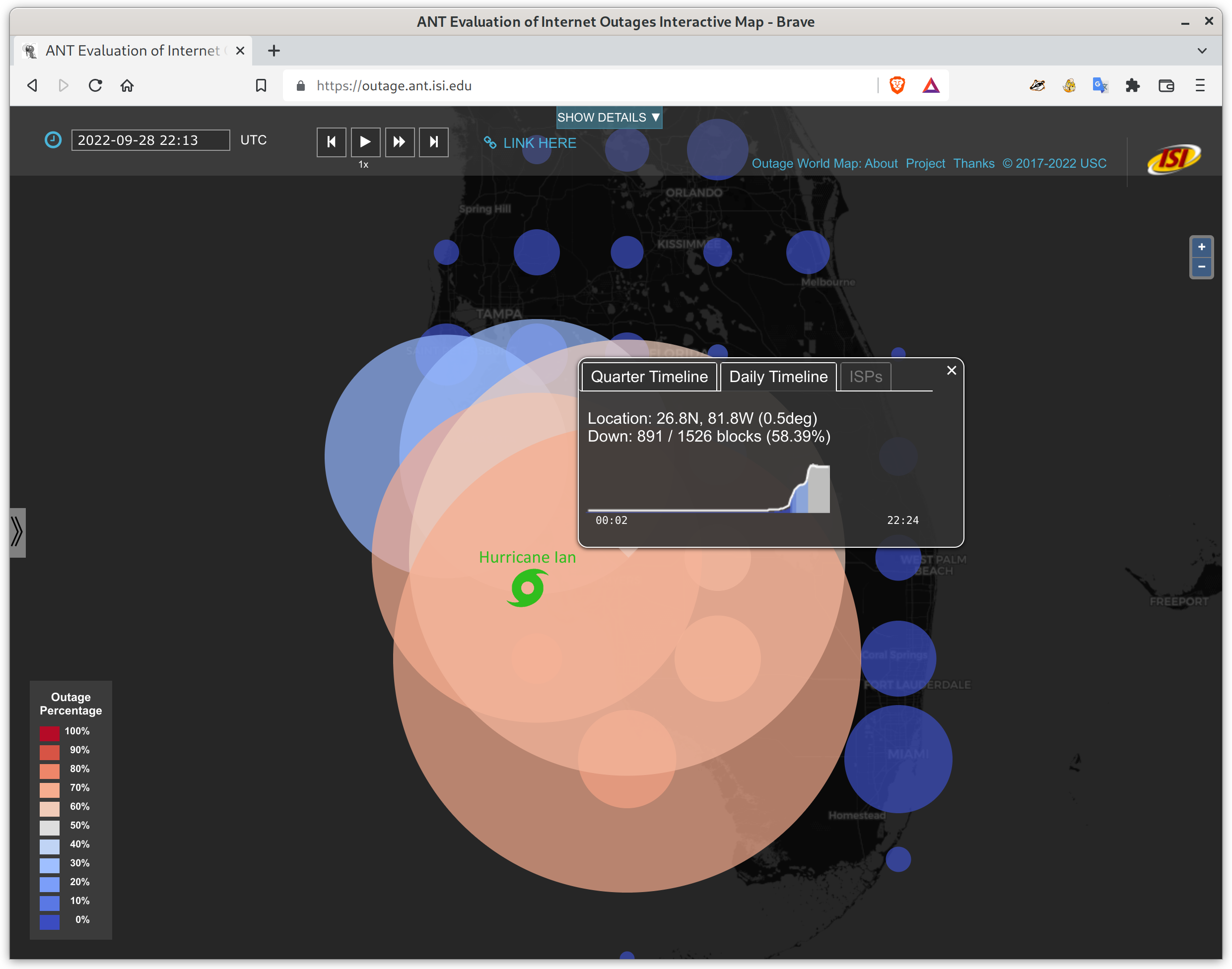
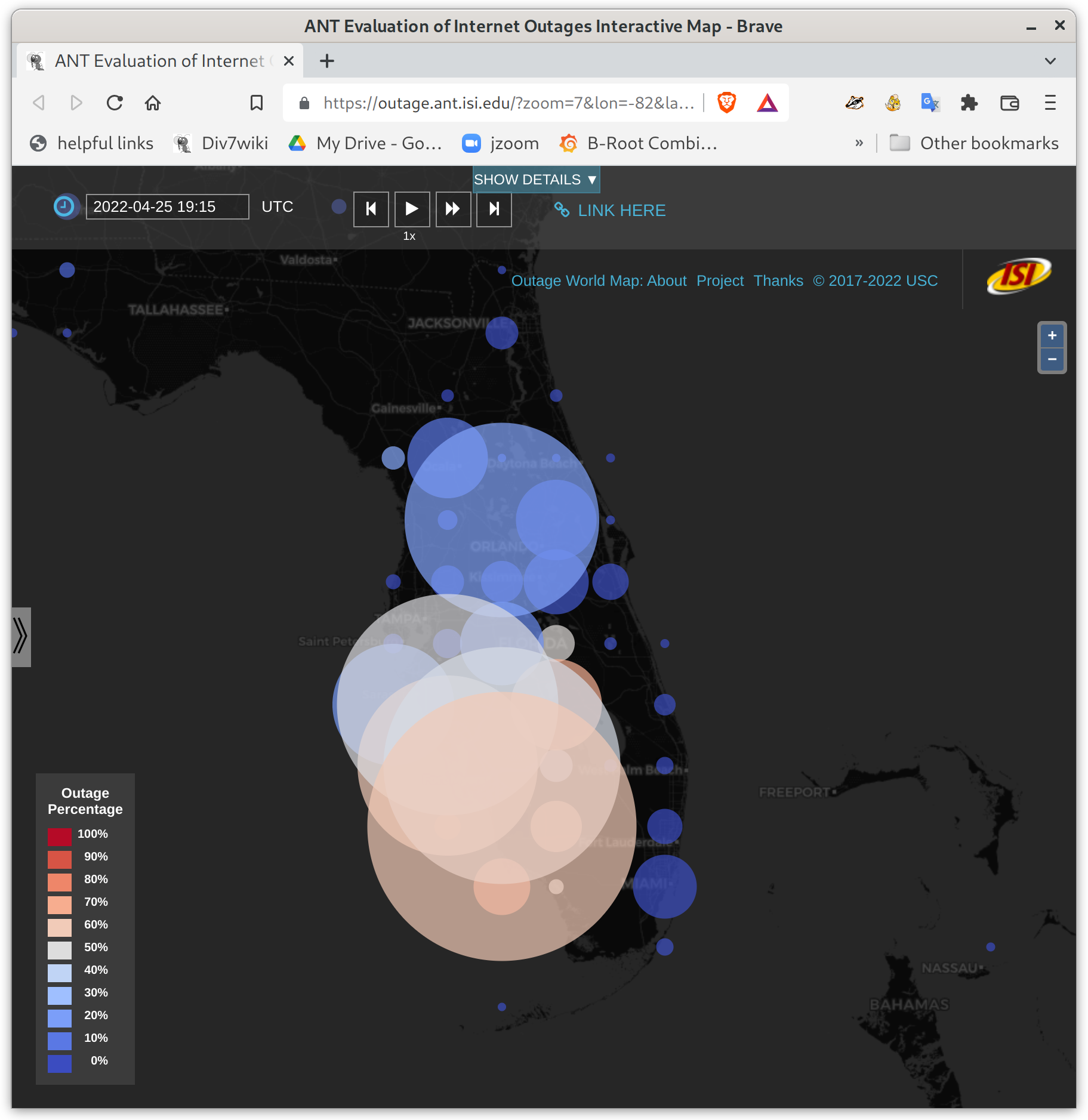
Trinocular outages in Florida at 6:13pm EDT (22:13Z). Circle area is proportional to the number of networks that are out in each 0.5×0.5 degree geographic grid cell, the color is the percentage of networks that are out.
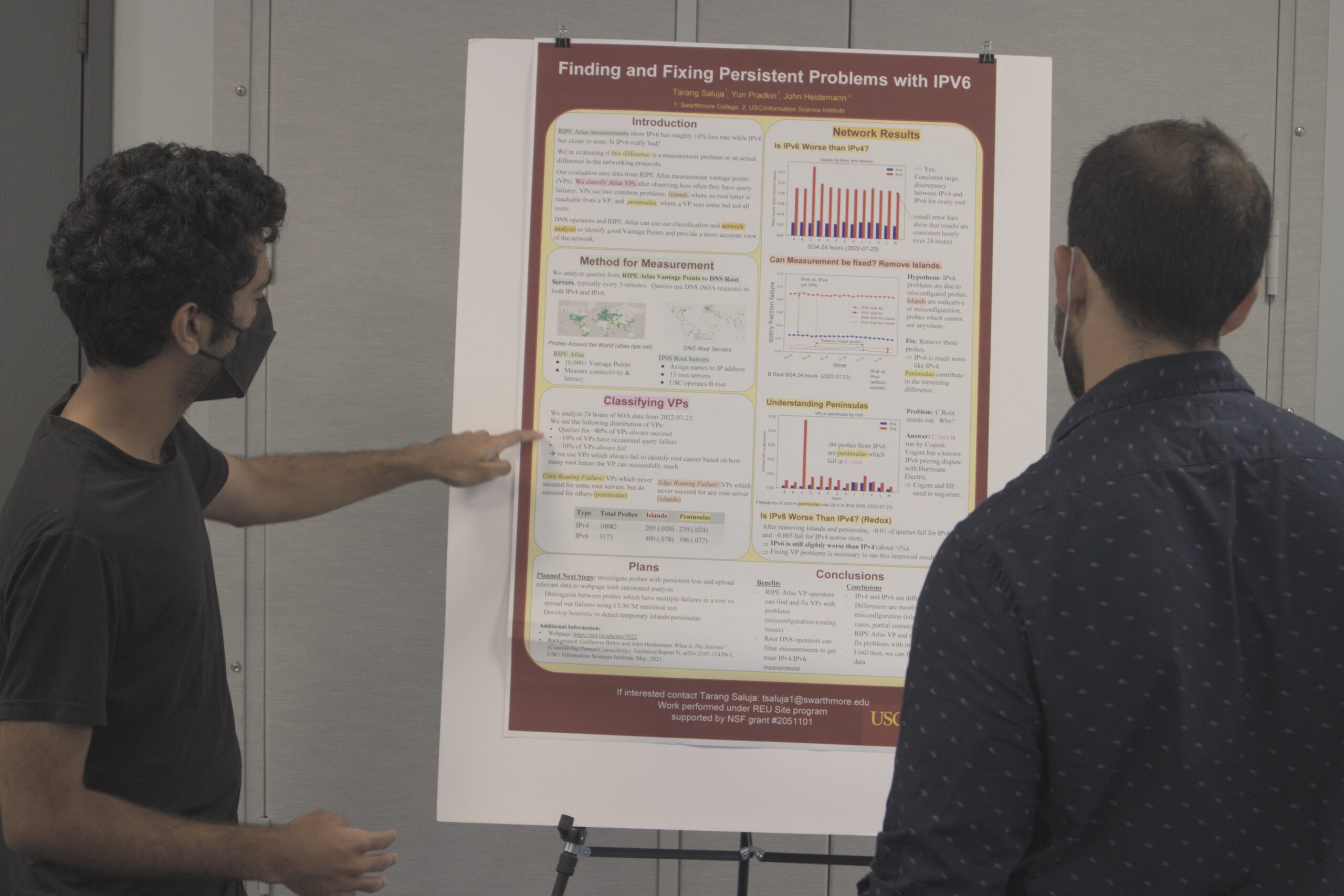
Tarang Saluja completed his summer undergraduate research internship at ISI this summer, working with John Heidemann and Yuri Pradkin on his project “Differences in Monitoring the DNS Root Over IPv4 and IPv6″.
In his project, Tarang examined RIPE Atlas’s DNSmon, a measurement system that monitors the Root Server System. DNSmon examines both IPv4 and IPv6, and its IPv6 reports show query loss rates that are consistently higher than IPv4, often 4-6% IPv6 loss vs. no or 2% IPv4 loss. Prior results by researchers at RIPE suggested these differences were due to problems at specific Atlas Vantage Points (VPs, also called Atlas Probes).
Tarang Saluja describing his research to an ISI researcher, at the ISI REU Poster Session on 2022-08-01.
Building on the Guillero Baltra’s studies of partial connectivity in the Internet, Tarang classified Atlas VPs with problems as islands and peninsulas. Islands think they are on IPv6, but cannot reach any of the 13 Root DNS “letters” over IPv6, indicating that the VP has a local network configuration problem. Peninsulas can reach some letters, but not others, indicating a routing problem somewhere in the core of the Internet.
Tarang’s work is important because these observations allow lead to potential solutions. Islands suggest VPs that do not support IPv6 and so should not be used for monitoring. Peninsulas point to IPv6 routing problems that need to be addressed by ISPs. Setting VPs with these problems aside provides a more accurate view of what IPv6 should be, and allows us to use DNSmon to detect more subtle problems. Together, his work points the way to improving IPv6 for everyone and improving Root DNS access over IPv6.
Tarang’s work was part of the ISI Research Experiences for Undergraduates program at USC/ISI. We thank Jelena Mirkovic (PI) for coordinating another year of this great program, and NSF for support through award #2051101.
We have released a new technical report: “Having your Privacy Cake and Eating it Too: Platform-supported Auditing of Social Media Algorithms for Public Interest”, available at https://arxiv.org/abs/2207.08773.
From the abstract:
Legislations have been proposed in both the U.S. and the E.U. that mandate auditing of social media algorithms by external researchers. But auditing at scale risks disclosure of users’ private data and platforms’ proprietary algorithms, and thus far there has been no concrete technical proposal that can provide such auditing. Our goal is to propose a new method for platform-supported auditing that can meet the goals of the proposed legislations. The first contribution of our work is to enumerate these challenges and the limitations of existing auditing methods to implement these policies at scale. Second, we suggest that limited, privileged access to relevance estimators is the key to enabling generalizable platform-supported auditing of social media platforms by external researchers. Third, we show platform-supported auditing need not risk user privacy nor disclosure of platforms’ business interests by proposing an auditing framework that protects against these risks. For a particular fairness metric, we show that ensuring privacy imposes only a small constant factor increase (6.34× as an upper bound, and 4× for typical parameters) in the number of samples required for accurate auditing. Our technical contributions, combined with ongoing legal and policy efforts, can enable public oversight into how social media platforms affect individuals and society by moving past the privacy-vs-transparency hurdle.
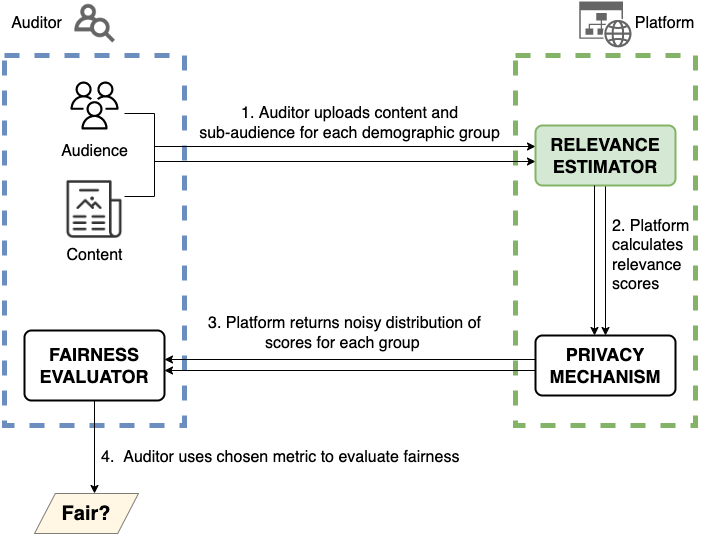
High-level overview of our proposed platform-supported framework for auditing relevance estimators while protecting the privacy of audit participants and the business interests of platforms.
This technical report is a joint work of Basileal Imana from USC, Aleksandra Korolova from Princeton University, and John Heidemann from USC/ISI.
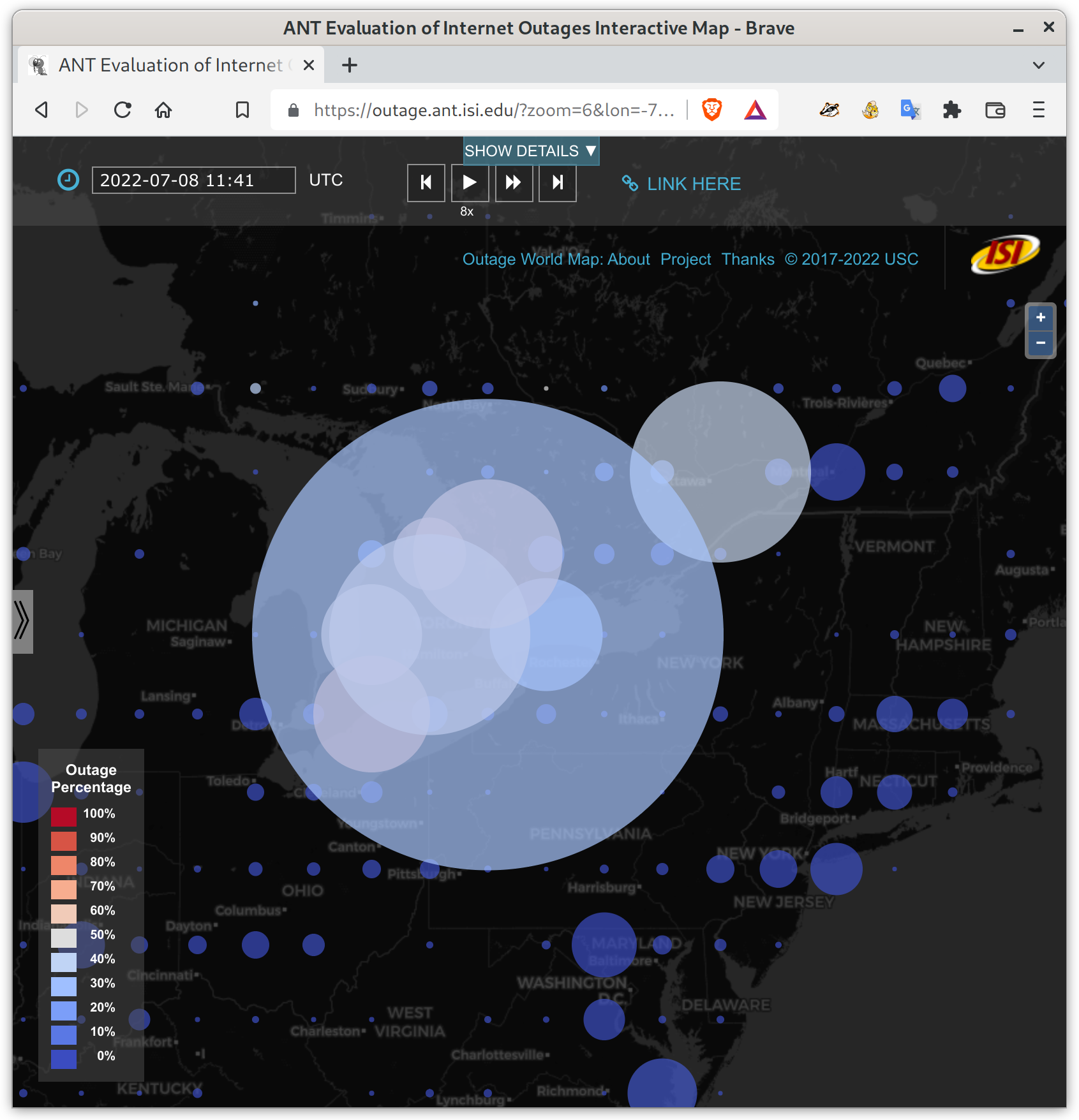
It’s big! Maybe 30% of Toronto and southern Ontario networks, plus a lot of outages in New Brunswick.
Ontario:
Internet outages in Ontario, Canada. The largest circle represents about 6500 /24 network blocks down near Toronto, about 30% of the /24 blocks in that area. See details on our outage website.
New Brunswick:
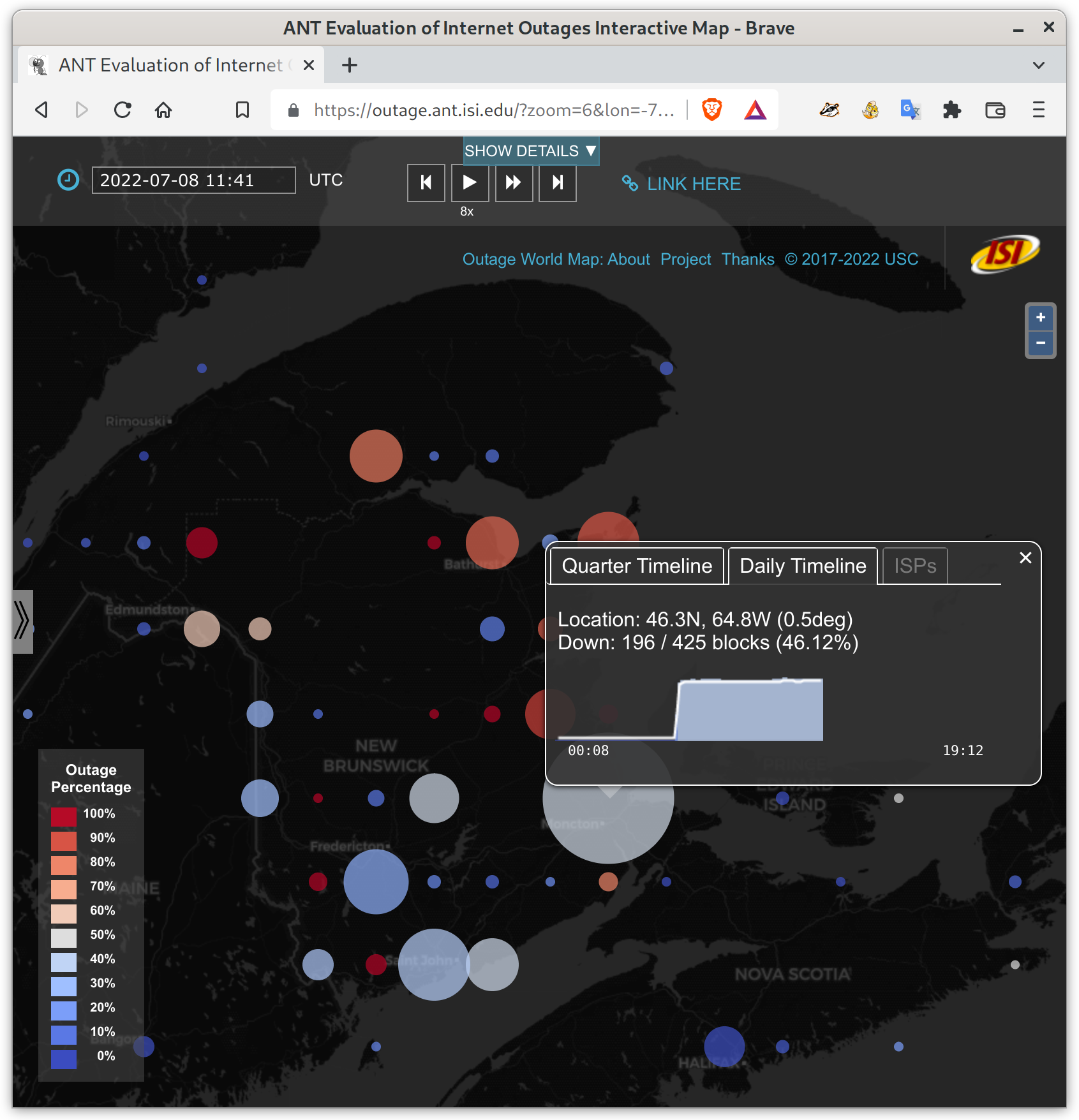
Internet outages in New Brunswick, Canada. The largest circle here represents 196 /24 network blocks down near Moncton, more than 45% of the /24 blocks there. The red circles are areas where most or all network blocks are currently out. See details on our outage website.
An update: Newfoundland also sees a lot of outages. Quebec looks in pretty good shape, though.
And it’s lasting a long time. It looks like it started at 5am Eastern time (2022-07-08t09:00Z), it it has lasted 9.5 hours so far!
We wish Rogers personnel and our Canadian neighbors the best.
Update at 2022-07-09t06:15Z (2:15am Eastern time): Toronto is doing much better, with “only” 10% of blocks unreachable (22808 of 21.5k in the 43.8N,79.3W 0.5 grid cell). New Brunswick and Newfoundland still look the same, with outages in about 50% of blocks.
Update at 2022-07-09t21:10Z (5:10pm Eastern time): It looks like many Rogers networks recovered at 2022-07-09t05:15Z (1:15am Eastern time). This includes all of New Brunswick and Newfoundland and most of Ontario. Trinocular has about a one-hour delay while it computes results, so I did not see this result when I checked in the prior update–I needed to wait 15 minutes more.
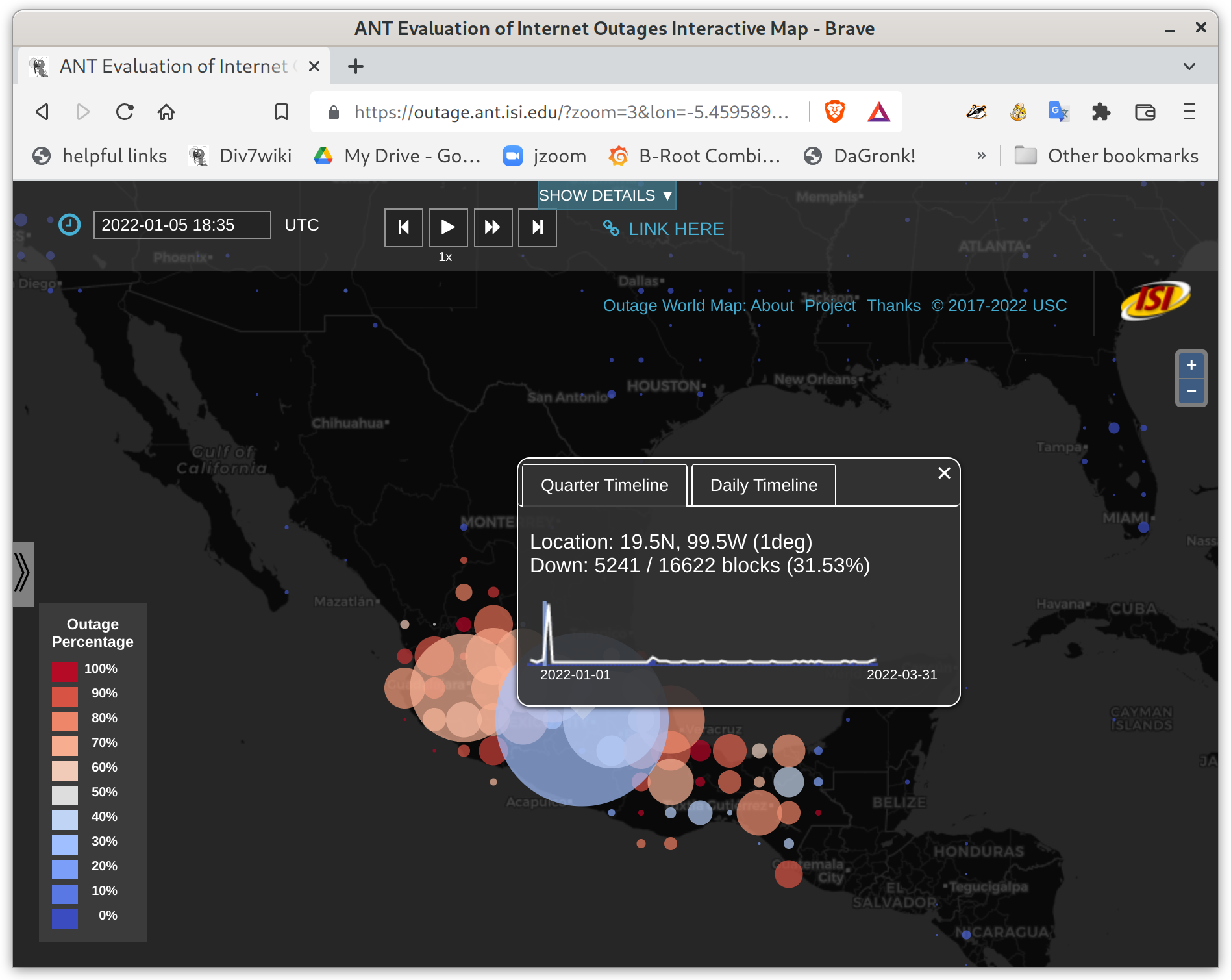
We recently added timeline support to our Outage World map–clicking on an outage bubble pops up a window with a sparkline (a small graph) showing maximum outages on each data for the current quarter, and clicking on the “daily timeline” tab shows outages for the current 24 hours. These graphs help provide context for how long an outage lasts, and if there were other outages the same quarter.