We have released a new technical report: “Towards a Non-Binary View of IPv6 Adoption”, available at https://arxiv.org/abs/2507.11678.
From the abstract:
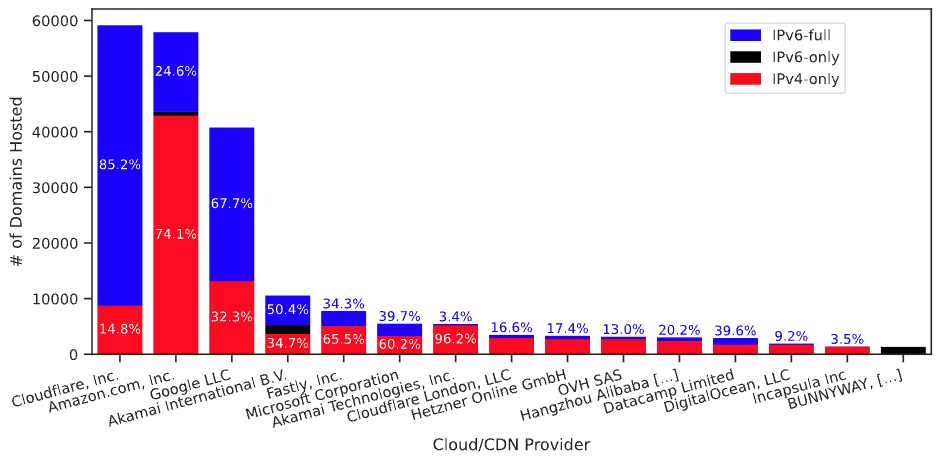
Breakdown of domains hosted by major cloud providers into IPv4-only (red), IPv6-only (black) and IPv6-full, i.e., IPv4+IPv6 (blue). See Section 5 of the technical report for details. (Figure 10 from the paper.)
Twelve years have passed since World IPv6 Launch Day, but what is the current state of IPv6 deployment? Prior work has examined IPv6 status as a binary: can you use IPv6, or not? As deployment increases we must consider a more nuanced, non-binary perspective on IPv6: how much and often can a user or a service use IPv6? We consider this question as a client, server, and cloud provider. Considering the client’s perspective, we observe user traffic. We see that the fraction of IPv6 traffic a user sends varies greatly, both across users and day-by-day, with a standard deviation of over 15%. We show this variation occurs for two main reasons. First, IPv6 traffic is primarily human-generated, thus showing diurnal patterns. Second, some services are IPv6-forward and others IPv6-laggards, so as users do different things their fraction of IPv6 varies. We look at server-side IPv6 adoption in two ways. First, we expand analysis of web services to examine how many are only partially IPv6 enabled due to their reliance on IPv4-only resources. Our findings reveal that only 12.5% of top 100k websites qualify as fully IPv6-ready. Finally, we examine cloud support for IPv6. Although all clouds and CDNs support IPv6, we find that tenant deployment rates vary significantly across providers. We find that ease of enabling IPv6 in the cloud is correlated with tenant IPv6 adoption rates, and recommend best practices for cloud providers to improve IPv6 adoption. Our results suggest IPv6 deployment is growing, but many services lag, presenting a potential for improvement.
This technical report is a joint work of Sulyab Thottungal Valapu from USC, and John Heidemann from USC/ISI. This work was partially supported by the NSF via the PIMAWAT and InternetMap projects.
We have released a new technical report: “Having your Privacy Cake and Eating it Too: Platform-supported Auditing of Social Media Algorithms for Public Interest”, available at https://arxiv.org/abs/2207.08773.
From the abstract:
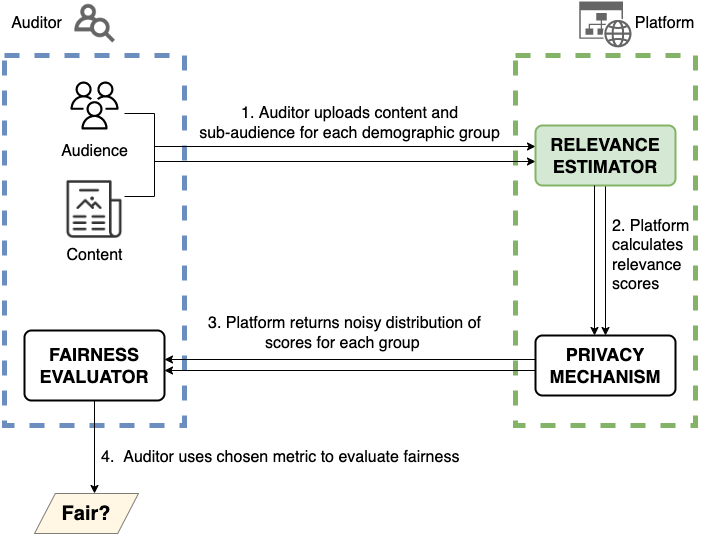
Legislations have been proposed in both the U.S. and the E.U. that mandate auditing of social media algorithms by external researchers. But auditing at scale risks disclosure of users’ private data and platforms’ proprietary algorithms, and thus far there has been no concrete technical proposal that can provide such auditing. Our goal is to propose a new method for platform-supported auditing that can meet the goals of the proposed legislations. The first contribution of our work is to enumerate these challenges and the limitations of existing auditing methods to implement these policies at scale. Second, we suggest that limited, privileged access to relevance estimators is the key to enabling generalizable platform-supported auditing of social media platforms by external researchers. Third, we show platform-supported auditing need not risk user privacy nor disclosure of platforms’ business interests by proposing an auditing framework that protects against these risks. For a particular fairness metric, we show that ensuring privacy imposes only a small constant factor increase (6.34× as an upper bound, and 4× for typical parameters) in the number of samples required for accurate auditing. Our technical contributions, combined with ongoing legal and policy efforts, can enable public oversight into how social media platforms affect individuals and society by moving past the privacy-vs-transparency hurdle.
High-level overview of our proposed platform-supported framework for auditing relevance estimators while protecting the privacy of audit participants and the business interests of platforms.
This technical report is a joint work of Basileal Imana from USC, Aleksandra Korolova from Princeton University, and John Heidemann from USC/ISI.
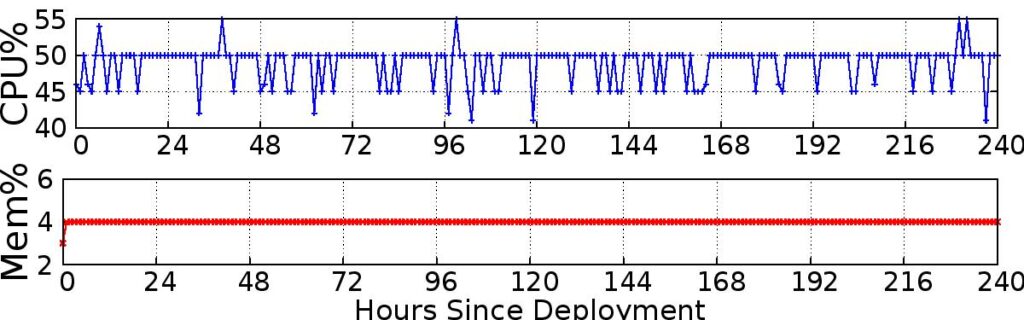
We show IoTSTEED runs well on a commodity router: memory usage is small (4% of 512MB) and the router forwards traffic at full uplink rates despite about 50% of CPU usage.
We propose IoTSTEED, a system running in edge routers to defend against Distributed Denial-of-Service (DDoS) attacks launched from compromised Internet-of-Things (IoT) devices. IoTSTEED watches traffic that leaves and enters the home network, detecting IoT devices at home, learning the benign servers they talk to, and filtering their traffic to other servers as a potential DDoS attack. We validate IoTSTEED’s accuracy and false positives (FPs) at detecting devices, learning servers and filtering traffic with replay of 10 days of benign traffic captured from an IoT access network. We show IoTSTEED correctly detects all 14 IoT and 6 non-IoT devices in this network (100% accuracy) and maintains low false-positive rates when learning the servers IoT devices talk to (flagging 2% benign servers as suspicious) and filtering IoT traffic (dropping only 0.45% benign packets). We validate IoTSTEED’s true positives (TPs) and false negatives (FNs) in filtering attack traffic with replay of real-world DDoS traffic. Our experiments show IoTSTEED mitigates all typical attacks, regardless of the attacks’ traffic types, attacking devices and victims; an intelligent adversary can design to avoid detection in a few cases, but at the cost of a weaker attack. Lastly, we deploy IoTSTEED in NAT router of an IoT access network for 10 days, showing reasonable resource usage and verifying our testbed experiments for accuracy and learning in practice.
We have released a new technical report “Peek Inside the Closed World: Evaluating Autoencoder-Based Detection of DDoS to Cloud” as an ArXiv technical report 1912.05590, also available from our website (updated 2025; prior link was: https://www.isi.edu/~hangguo/papers/Guo19a.pdf)
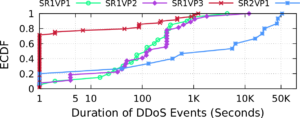
We study 4 cloud IPs (SR1VP1 to 3 and SR2VP1) that are under attack. SR1VP3 sees a large number of mostly short DDoS events (71% of its 49 events being 1 second or less). SR1VP1 and SR1VP2 see smaller numbers of longer DDoS events (median duration for their 20 and 27 events are 121 and 140 seconds). SR2VP1 sees DDoS events of broad range of durations (from 1 second to more than 14 hours).
From the abstract of our technical report:
From the abstract:
Machine-learning-based anomaly detection (ML-based AD) has been successful at detecting DDoS events in the lab. However published evaluations of ML-based AD have only had limited data and have not provided insight into why it works. To address limited evaluation against real-world data, we apply autoencoder, an existing ML-AD model, to 57 DDoS attack events captured at 5 cloud IPs from a major cloud provider. To improve our understanding for why ML-based AD works or not works, we interpret this data with feature attribution and counterfactual explanation. We show that our version of autoencoders work well overall: our models capture nearly all malicious flows to 2 of the 4 cloud IPs under attacks (at least 99.99%) but generate a few false negatives (5% and 9%) for the remaining 2 IPs. We show that our models maintain near-zero false positives on benign flows to all 5 IPs. Our interpretation of results shows that our models identify almost all malicious flows with non-whitelisted (non-WL) destination ports (99.92%) by learning the full list of benign destination ports from training data (the normality). Interpretation shows that although our models learn incomplete normality for protocols and source ports, they still identify most malicious flows with non-WL protocols and blacklisted (BL) source ports (100.0% and 97.5%) but risk false positives. Interpretation also shows that our models only detect a few malicious flows with BL packet sizes (8.5%) by incorrectly inferring these BL sizes as normal based on incomplete normality learned. We find our models still detect a quarter of flows (24.7%) with abnormal payload contents even when they do not see payload by combining anomalies from multiple flow features. Lastly, we summarize the implications of what we learn on applying autoencoder-based AD in production.problme?Machine-learning-based anomaly detection (ML-based AD) has been successful at detecting DDoS events in the lab. However published evaluations of ML-based AD have only had limited data and have not provided insight into why it works. To address limited evaluation against real-world data, we apply autoencoder, an existing ML-AD model, to 57 DDoS attack events captured at 5 cloud IPs from a major cloud provider. To improve our understanding for why ML-based AD works or not works, we interpret this data with feature attribution and counterfactual explanation. We show that our version of autoencoders work well overall: our models capture nearly all malicious flows to 2 of the 4 cloud IPs under attacks (at least 99.99%) but generate a few false negatives (5% and 9%) for the remaining 2 IPs. We show that our models maintain near-zero false positives on benign flows to all 5 IPs. Our interpretation of results shows that our models identify almost all malicious flows with non-whitelisted (non-WL) destination ports (99.92%) by learning the full list of benign destination ports from training data (the normality). Interpretation shows that although our models learn incomplete normality for protocols and source ports, they still identify most malicious flows with non-WL protocols and blacklisted (BL) source ports (100.0% and 97.5%) but risk false positives. Interpretation also shows that our models only detect a few malicious flows with BL packet sizes (8.5%) by incorrectly inferring these BL sizes as normal based on incomplete normality learned. We find our models still detect a quarter of flows (24.7%) with abnormal payload contents even when they do not see payload by combining anomalies from multiple flow features. Lastly, we summarize the implications of what we learn on applying autoencoder-based AD in production.
This technical report is joint work of Hang Guo and John Heidemann from USC/ISI and Xun Fan, Anh Cao and Geoff Outhred from Microsoft
We have released a new technical report “Improving the Optics of the Active Outage Detection (extended)”, by Guillermo Baltra and John Heidemann, as ISI-TR-733.
From the abstract:
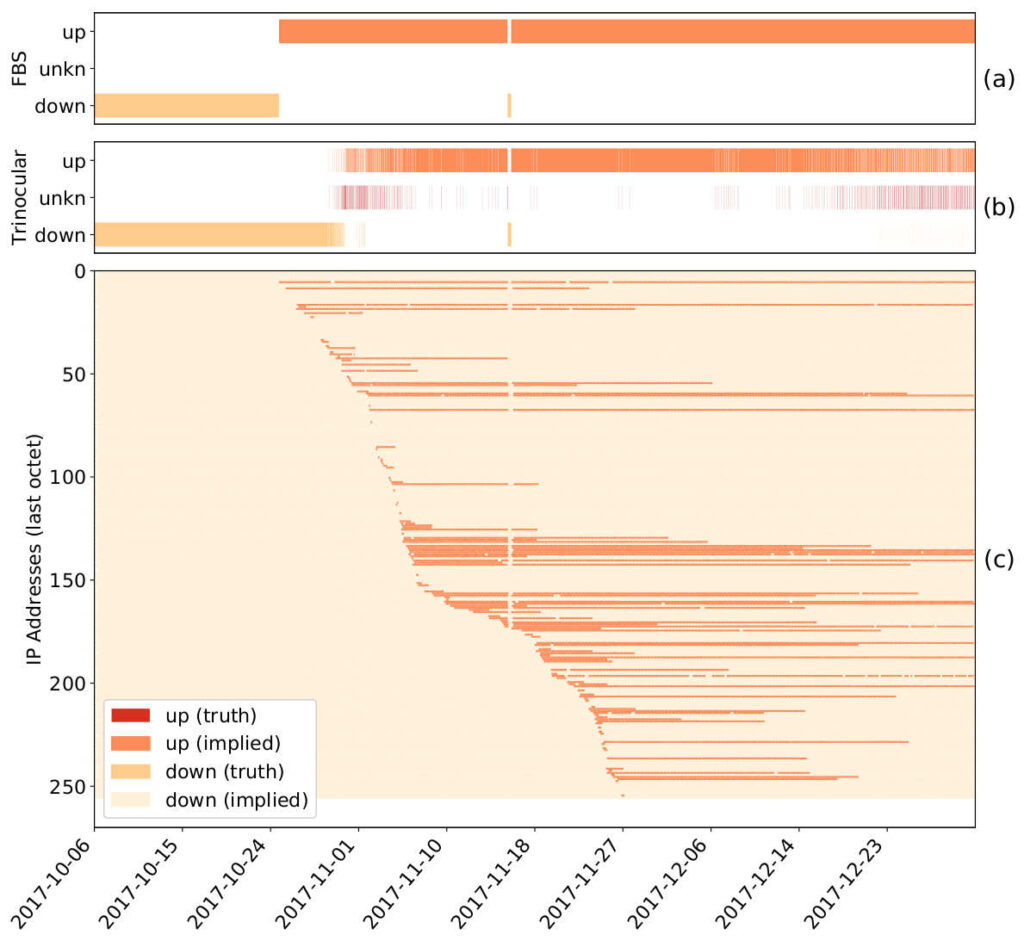
A sample block showing changes in block usage (c), and outage detection results of Trinocular (b) and improved with the Full Block Scanning Algorithm (a).
There is a growing interest in carefully observing the reliability of the Internet’s edge. Outage information can inform our understanding of Internet reliability and planning, and it can help guide operations. Outage detection algorithms using active probing from third parties have been shown to be accurate for most of the Internet, but inaccurate for blocks that are sparsely occupied. Our contributions include a definition of outages, which we use to determine how many independent observers are required to determine global outages. We propose a new Full Block Scanning (FBS) algorithm that gathers more information for sparse blocks to reduce false outage reports. We also propose ISP Availability Sensing (IAS) to detect maintenance activity using only external information. We study a year of outage data and show that FBS has a True Positive Rate of 86%, and show that IAS detects maintenance events in a large U.S. ISP.
All data from this paper will be publicly available.
We released a new technical report “Plumb: Efficient Processing of Multi-User Pipelines (Poster)”, by Abdul Qadeer and John Heidemann, as ISI-TR-731. This work was originally presented at ACM Symposium on Cloud Computing (the poster abstract is available at ACM). The poster abstract with a small version of the poster is available at https://www.isi.edu/publications/trpublic/pdfs/isi-tr-731.pdf
aqadeer at SoCC 2018 Carlsbad CA
From the abstract:
As the field of big data analytics matures, workflows are increasingly complex and often include components that are shared by different users. Individual workflows often include multiple stages, and when groups build on each other’s work it is easy to lose track of computation that may be shared across different groups.
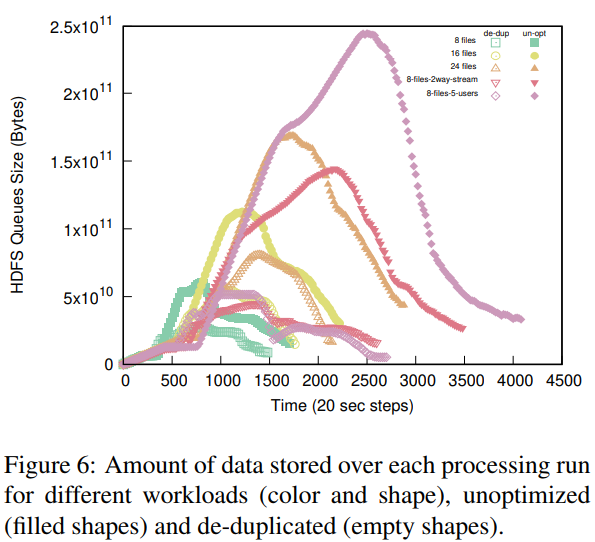
The contribution of this poster is to provide an organization-wide processing substrate Plumb that can be used to solve commonly occurring problems and to achieve a common goal. Plumb makes multi-user sharing a first-class concern by providing pipeline-graph abstraction. This abstraction is simple and based on fundamental model of input-processing-output but is powerful to capture processing and data duplication. Plumb then employs best available solutions to tackle problems of large-block processing under structural and computational skew without user intervention.
We expect to release the Plumb software this fall; please contact us if you have questions or interest in using it.
Services such as DNS and websites often produce streams of data that are consumed by analytics pipelines operated by multiple teams. Often this data is processed in large chunks (megabytes) to allow analysis of a block of time or to amortize costs. Such pipelines pose two problems: first, duplication of computation and storage may occur when parts of the pipeline are operated by different groups. Second, processing can be lumpy, with structural lumpiness occurring when different stages need different amounts of resources, and data lumpiness occurring when a block of input requires increased resources. Duplication and structural lumpiness both can result in inefficient processing. Data lumpiness can cause pipeline failure or deadlock, for example if differences in DDoS traffic compared to normal can require 6× CPU. We propose Plumb, a framework to abstract file processing for a multi-stage pipeline. Plumb integrates pipelines contributed by multiple users, detecting and eliminating duplication of computation and intermediate storage. It tracks and adjusts computation of each stage, accommodating both structural and data lumpiness. We exercise Plumb with the processing pipeline for B-Root DNS traffic, where it will replace a hand-tuned system to provide one third the original latency by utilizing 22% fewer CPU and will address limitations that occur as multiple users process data and when DDoS traffic causes huge shifts in performance.
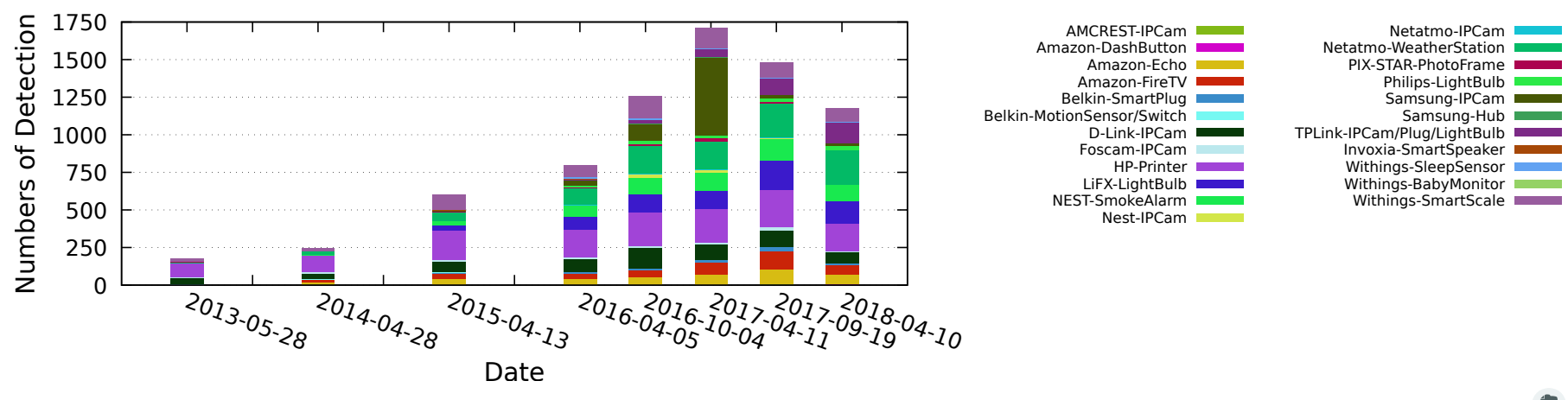
ISP-Level Deployment for 26 IoT Device Types. From Figure 2 of [Guo18c].From the abstract of our technical report:
Distributed Denial-of-Service (DDoS) attacks launched from compromised Internet-of-Things (IoT) devices have shown how vulnerable the Internet is to large-scale DDoS attacks. To understand the risks of these attacks requires learning about these IoT devices: where are they? how many are there? how are they changing? This paper describes three new methods to find IoT devices on the Internet: server IP addresses in traffic, server names in DNS queries, and manufacturer information in TLS certificates. Our primary methods (IP addresses and DNS names) use knowledge of servers run by the manufacturers of these devices. We have developed these approaches with 10 device models from 7 vendors. Our third method uses TLS certificates obtained by active scanning. We have applied our algorithms to a number of observations. Our IP-based algorithms see at least 35 IoT devices on a college campus, and 122 IoT devices in customers of a regional IXP. We apply our DNSbased algorithm to traffic from 5 root DNS servers from 2013 to 2018, finding huge growth (about 7×) in ISPlevel deployment of 26 device types. DNS also shows similar growth in IoT deployment in residential households from 2013 to 2017. Our certificate-based algorithm finds 254k IP cameras and network video recorders from 199 countries around the world.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This technical report is joint work of Hang Guo and John Heidemann from USC/ISI.
Moura18a Figure 6a, Answers received during a DDoS attack causing 100% packet loss with pre-loaded caches.
From the abstract:
The Internet’s Domain Name System (DNS) is a frequent target of Distributed Denial-of-Service (DDoS) attacks, but such attacks have had very different outcomes—some attacks have disabled major public websites, while the external effects of other attacks have been minimal. While on one hand the DNS protocol is a relatively simple, the system has many moving parts, with multiple levels of caching and retries and replicated servers. This paper uses controlled experiments to examine how these mechanisms affect DNS resilience and latency, exploring both the client side’s DNS user experience, and server-side traffic. We find that, for about about 30% of clients, caching is not effective. However, when caches are full they allow about half of clients to ride out server outages, and caching and retries allow up to half of the clients to tolerate DDoS attacks that result in 90% query loss, and almost all clients to tolerate attacks resulting in 50% packet loss. The cost of such attacks to clients are greater median latency. For servers, retries during DDoS attacks increase normal traffic up to 8x. Our findings about caching and retries can explain why some real-world DDoS cause service outages for users while other large attacks have minimal visible effects.
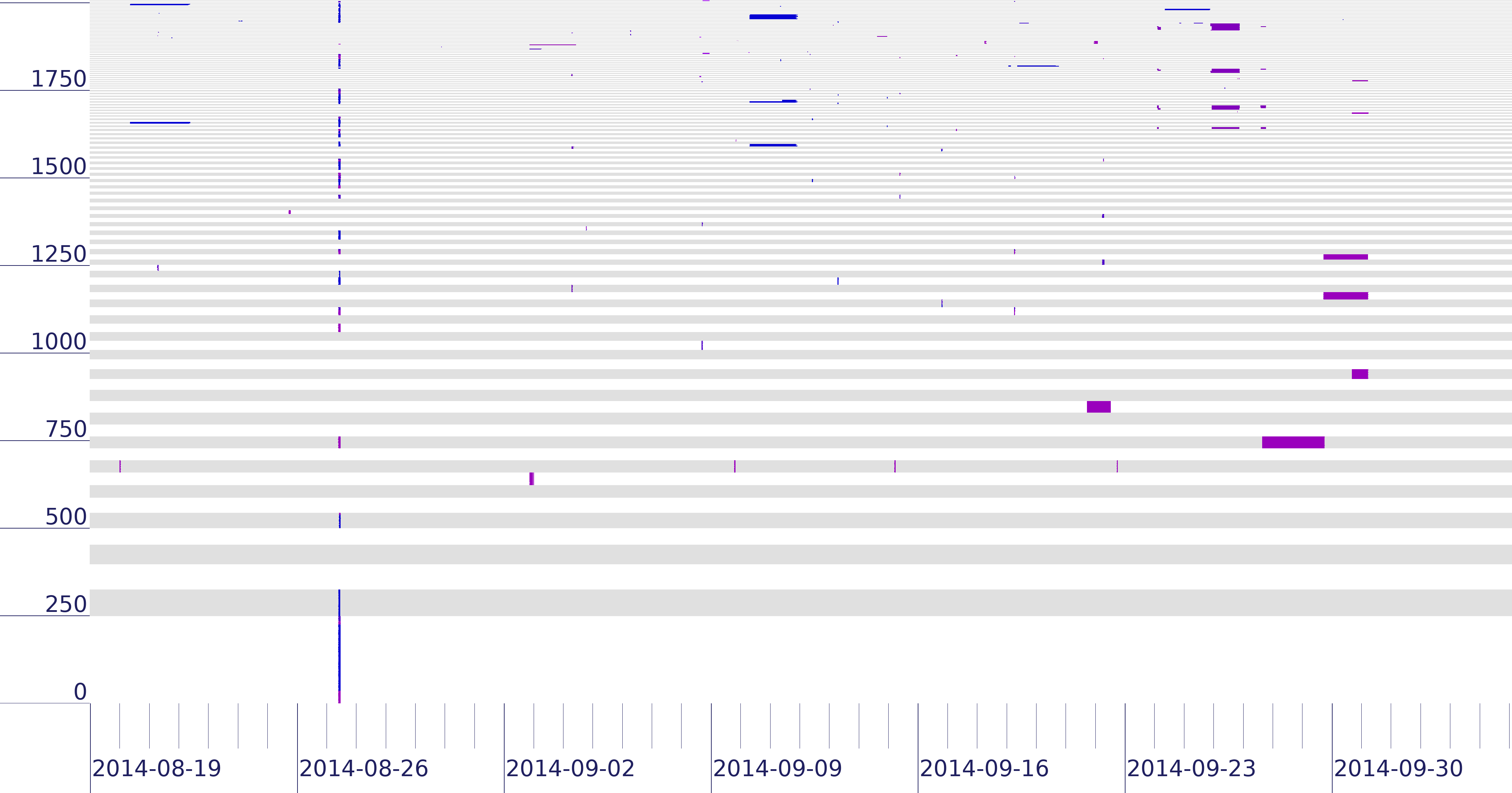
We released a new technical report “Back Out: End-to-end Inference of Common Points-of-Failure in the Internet (extended)”, ISI-TR-724, available at https://www.isi.edu/~johnh/PAPERS/Heidemann18b.pdf.
From the abstract:
Clustering (from our event clustering algorithm) of 2014q3 outages from 172/8, showing 7 weeks including the 2014-08-27 Time Warner outage.
Internet reliability has many potential weaknesses: fiber rights-of-way at the physical layer, exchange-point congestion from DDOS at the network layer, settlement disputes between organizations at the financial layer, and government intervention the political layer. This paper shows that we can discover common points-of-failure at any of these layers by observing correlated failures. We use end-to-end observations from data-plane-level connectivity of edge hosts in the Internet. We identify correlations in connectivity: networks that usually fail and recover at the same time suggest common point-of-failure. We define two new algorithms to meet these goals. First, we define a computationally-efficient algorithm to create a linear ordering of blocks to make correlated failures apparent to a human analyst. Second, we develop an event-based clustering algorithm that directly networks with correlated failures, suggesting common points-of-failure. Our algorithms scale to real-world datasets of millions of networks and observations: linear ordering is O(n log n) time and event-based clustering parallelizes with Map/Reduce. We demonstrate them on three months of outages for 4 million /24 network prefixes, showing high recall (0.83 to 0.98) and precision (0.72 to 1.0) for blocks that respond. We also show that our algorithms generalize to identify correlations in anycast catchments and routing.
Datasets from this paper are available at no cost and are listed at https://ant.isi.edu/datasets/outage/, and we expect to release the software for this paper in the coming months (contact us if you are interested).