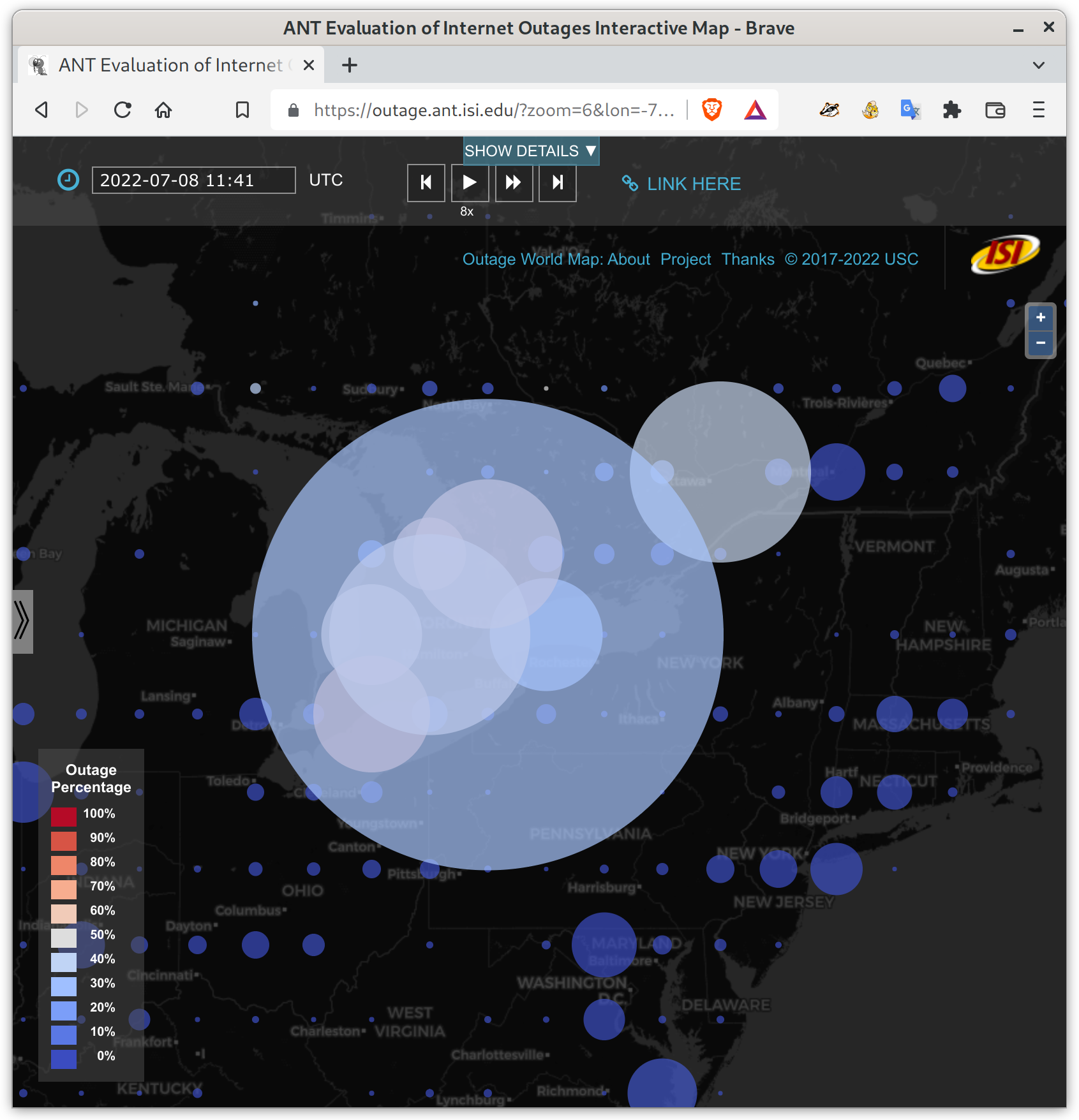
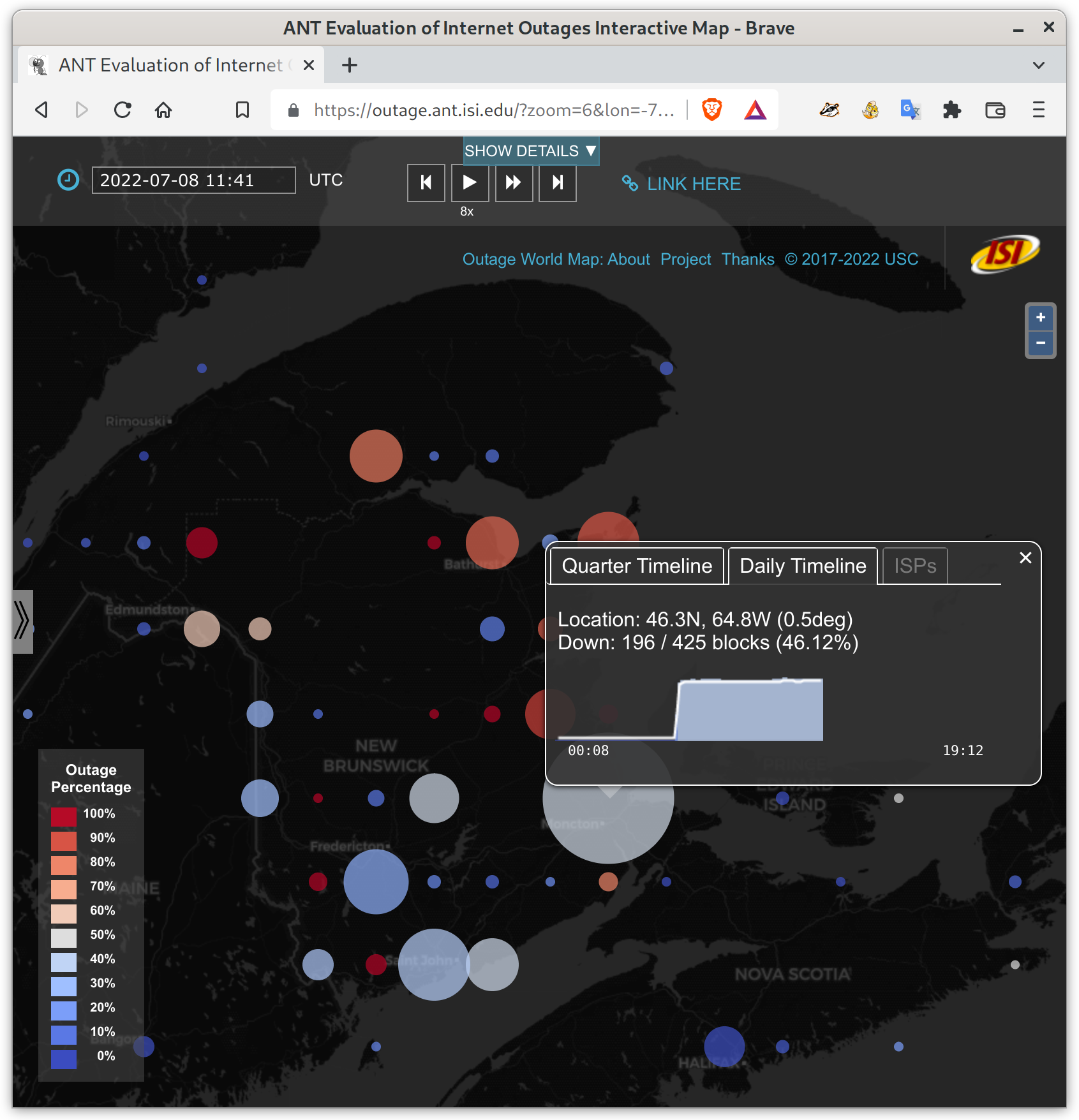
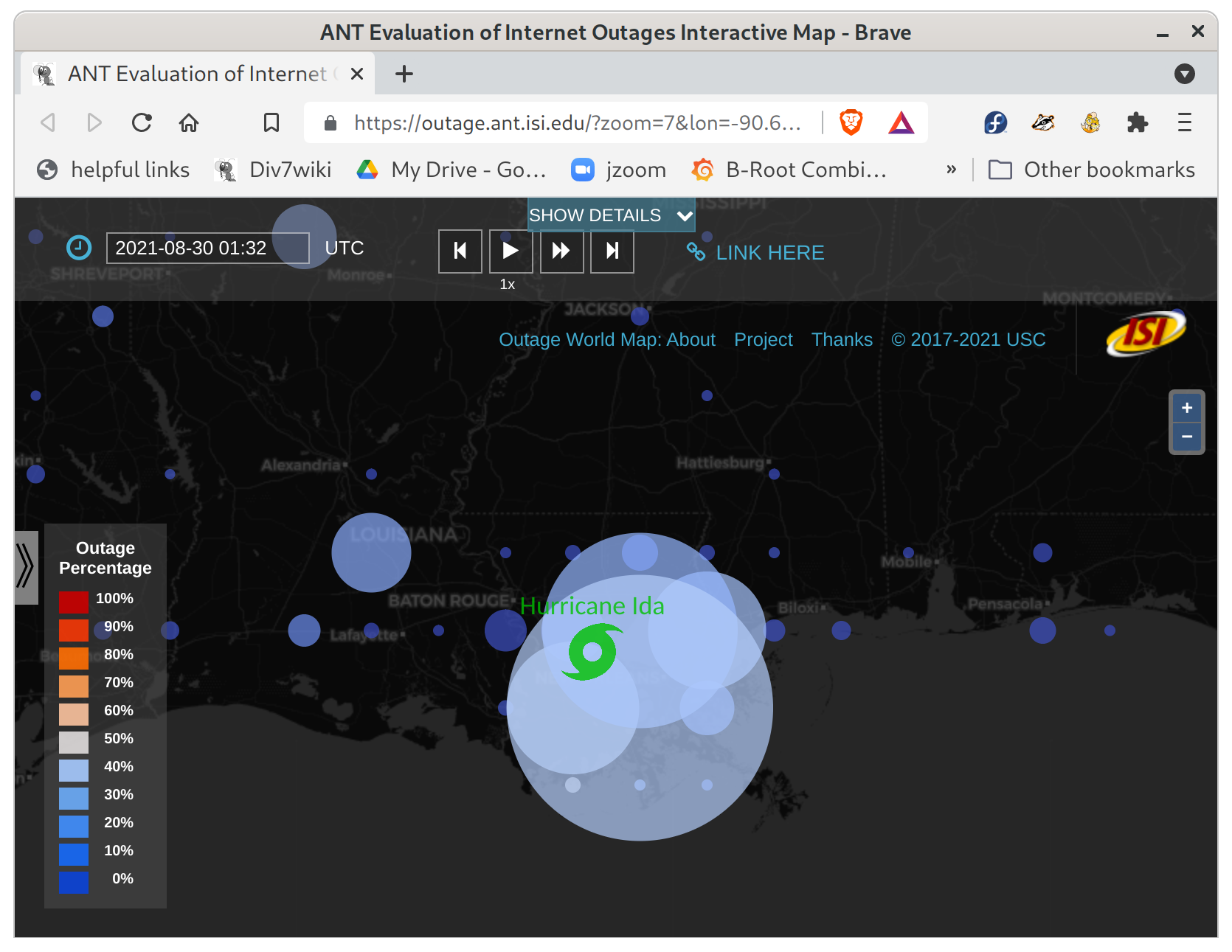
It’s big! Maybe 30% of Toronto and southern Ontario networks, plus a lot of outages in New Brunswick.
Ontario:
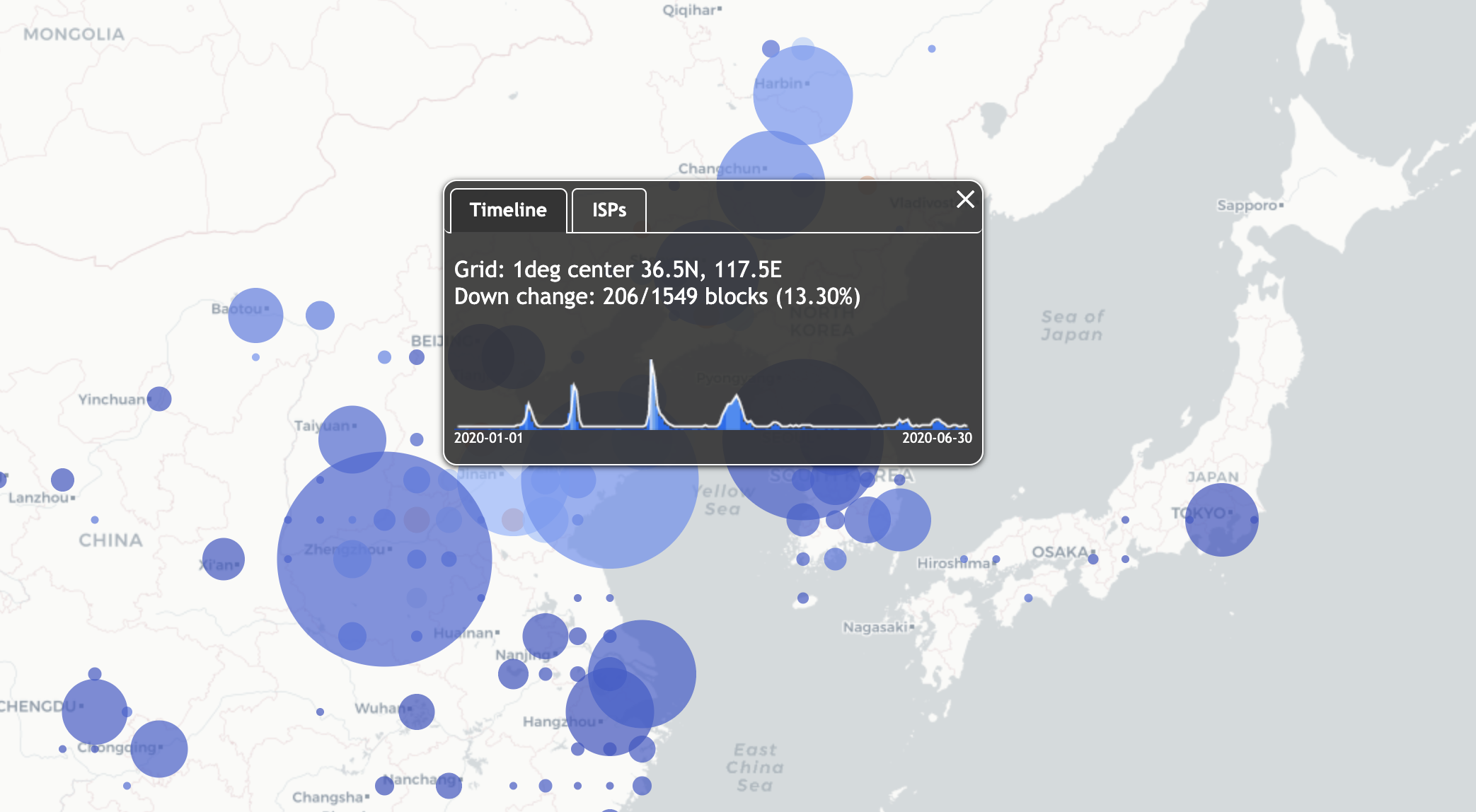
Internet outages in Ontario, Canada. The largest circle represents about 6500 /24 network blocks down near Toronto, about 30% of the /24 blocks in that area. See details on our outage website.
New Brunswick:
Internet outages in New Brunswick, Canada. The largest circle here represents 196 /24 network blocks down near Moncton, more than 45% of the /24 blocks there. The red circles are areas where most or all network blocks are currently out. See details on our outage website.
An update: Newfoundland also sees a lot of outages. Quebec looks in pretty good shape, though.
And it’s lasting a long time. It looks like it started at 5am Eastern time (2022-07-08t09:00Z), it it has lasted 9.5 hours so far!
We wish Rogers personnel and our Canadian neighbors the best.
Update at 2022-07-09t06:15Z (2:15am Eastern time): Toronto is doing much better, with “only” 10% of blocks unreachable (22808 of 21.5k in the 43.8N,79.3W 0.5 grid cell). New Brunswick and Newfoundland still look the same, with outages in about 50% of blocks.
Update at 2022-07-09t21:10Z (5:10pm Eastern time): It looks like many Rogers networks recovered at 2022-07-09t05:15Z (1:15am Eastern time). This includes all of New Brunswick and Newfoundland and most of Ontario. Trinocular has about a one-hour delay while it computes results, so I did not see this result when I checked in the prior update–I needed to wait 15 minutes more.
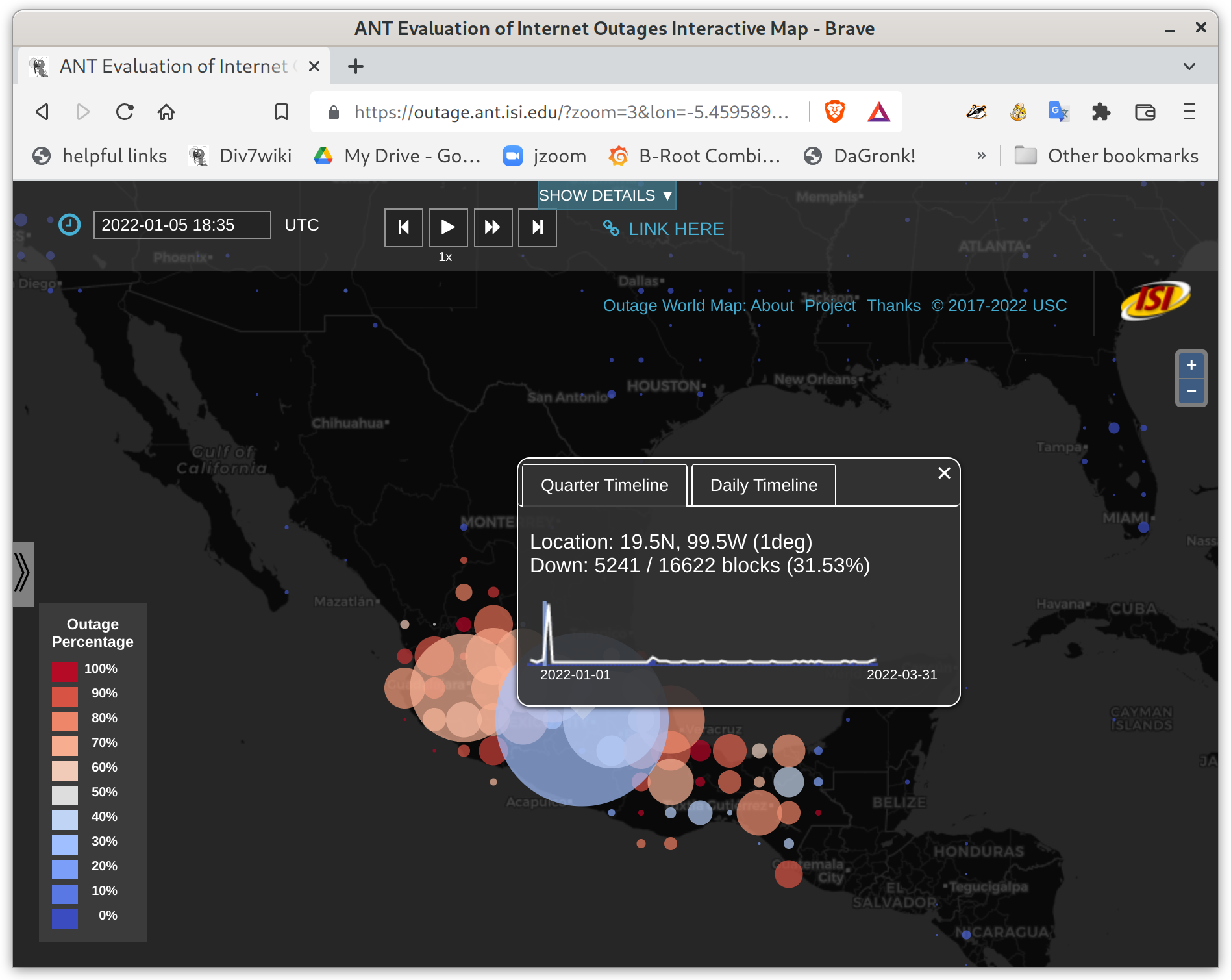
We recently added timeline support to our Outage World map–clicking on an outage bubble pops up a window with a sparkline (a small graph) showing maximum outages on each data for the current quarter, and clicking on the “daily timeline” tab shows outages for the current 24 hours. These graphs help provide context for how long an outage lasts, and if there were other outages the same quarter.
On March 29, 2022 the paper “Old but Gold: Prospecting TCP to Engineer and Live Monitor DNS Anycast” by Giovane C. M. Moura, John Heidemann, Wes Hardaker, Pithayuth Charnsethikul, Jeroen Bulten, João M. Ceron, and Cristian Hesselman appeared that the 2022 Passive and Active Measurement Conference. We’re happy that it was awarded Best Paper for this year’s conference!
From the abstract:
Google latency for .nl before (left red area) and after (middle green area) DNS polarization was corrected. Polarization was detected with ENTRADA using the work from this paper.
DNS latency is a concern for many service operators: CDNs exist to reduce service latency to end-users but must rely on global DNS for reachability and load-balancing. Today, DNS latency is monitored by active probing from distributed platforms like RIPE Atlas, with Verfploeter, or with commercial services. While Atlas coverage is wide, its 10k sites see only a fraction of the Internet. In this paper we show that passive observation of TCP handshakes can measure live DNS latency, continuously, providing good coverage of current clients of the service. Estimating RTT from TCP is an old idea, but its application to DNS has not previously been studied carefully. We show that there is sufficient TCP DNS traffic today to provide good operational coverage (particularly of IPv6), and very good temporal coverage (better than existing approaches), enabling near-real time evaluation of DNS latency from real clients. We also show that DNS servers can optionally solicit TCP to broaden coverage. We quantify coverage and show that estimates of DNS latency from TCP is consistent with UDP latency. Our approach finds previously unknown, real problems: DNS polarization is a new problem where a hypergiant sends global traffic to one anycast site rather than taking advantage of the global anycast deployment. Correcting polarization in Google DNS cut its latency from 100ms to 10ms; and from Microsoft Azure cut latency from 90ms to 20ms. We also show other instances of routing problems that add 100-200ms latency. Finally, real-time use of our approach for a European country-level domain has helped detect and correct a BGP routing misconfiguration that detoured European traffic to Australia. We have integrated our approach into several open source tools: Entrada, our open source data warehouse for DNS, a monitoring tool (ANTS), which has been operational for the last 2 years on a country-level top-level domain, and a DNS anonymization tool in use at a root server since March 2021.
This paper was made in part through DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I (PAADDOS) and by NWO, NSF CNS-1925737 (DIINER), and the Conconrdia Project, an European Union’s Horizon 2020 Research and Innovation program under Grant Agreement No 830927.
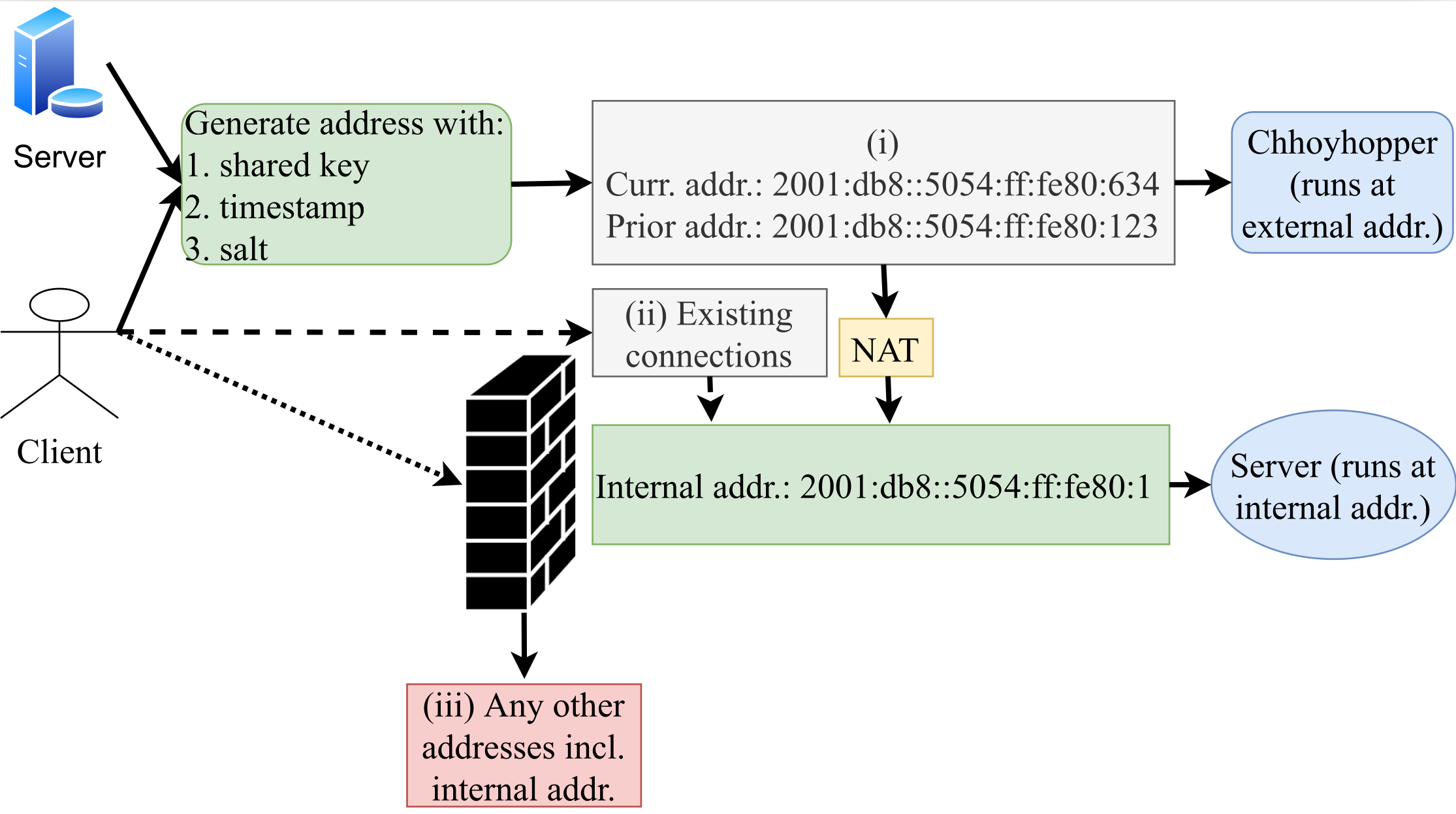
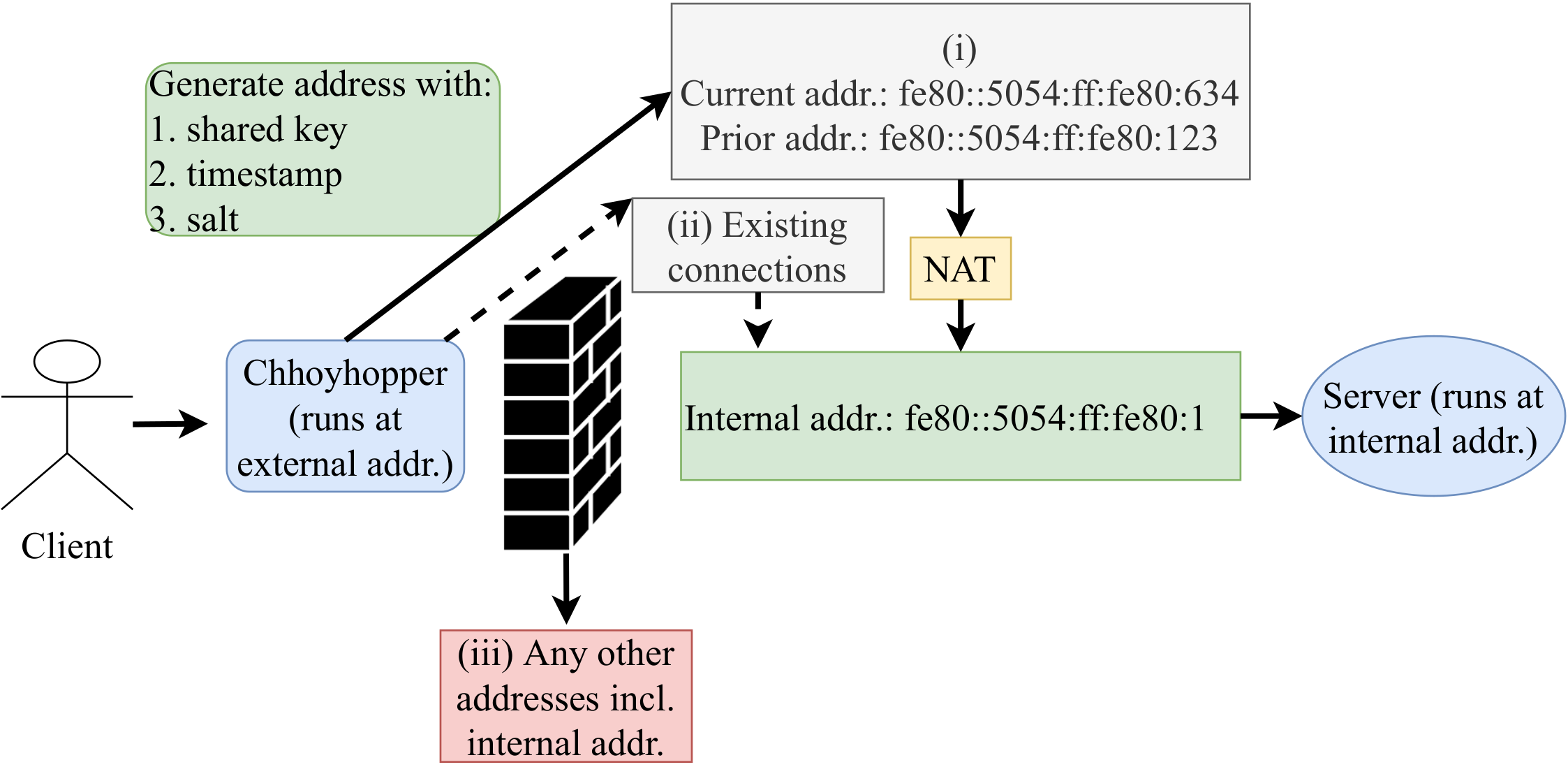
On April 24, 2022 we will publish a new paper titled “Chhoyhopper: A Moving Target Defense with IPv6” by A S M Rizvi and John Heidemann at the 4th Workshop on Measurements, Attacks, and Defenses for the Web (MADWeb 2022), co-located with NDSS. We provide Chhoyhopper as an open-source tool for SSH and HTTPS—try it out!
From the abstract:
Services on the public Internet are frequently scanned, then subject to brute-force password attempts and Denial-of-Service (DoS) attacks. We would like to run such services stealthily, where they are available to friends but hidden from adversaries. In this work, we propose a discovery-resistant moving target defense named “Chhoyhopper” that utilizes the vast IPv6 address space to conceal publicly available services. The client meets the server at an IPv6 address that changes in a pattern based on a shared, pre-distributed secret and the time of day. By hopping over a /64 prefix, services cannot be found by active scanners, and passively observed information is useless after two minutes. We demonstrate our system with the two important applications—SSH and HTTPS, and make our system publicly available.
Client and server interaction in Chhoyhopper. A Client with the right secret key can only get access into the system.
Thanks: A S M Rizvi and John Heidemann’s work on this paper is supported, in part, by the DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I (PAADDoS), and by DARPA under Contract No. HR001120C0157 (SABRES). Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of NSF or DARPA. We thank Rayner Pais who prototyped an early version of Chhoyhopper and version in IPv4 hopping over ports.
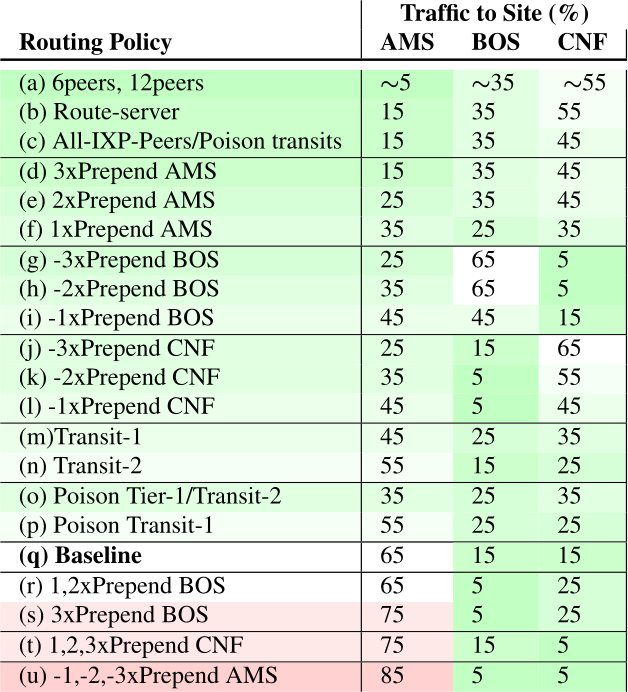
We will publish a new paper titled “Anycast Agility: Network Playbooks to Fight DDoS” by A S M Rizvi (USC/ISI), Leandro Bertholdo (University of Twente), João Ceron (SIDN Labs), and John Heidemann (USC/ISI) at the 31st USENIX Security Symposium in Aug. 2022.
A sample anycast playbook for a 3-site anycast deployment. Different routing configurations provide different traffic mixes. From [Rizvi22a, Table 5].
From the abstract:
IP anycast is used for services such as DNS and Content Delivery Networks (CDN) to provide the capacity to handle Distributed Denial-of-Service (DDoS) attacks. During a DDoS attack service operators redistribute traffic between anycast sites to take advantage of sites with unused or greater capacity. Depending on site traffic and attack size, operators may instead concentrate attackers in a few sites to preserve operation in others. Operators use these actions during attacks, but how to do so has not been described systematically or publicly. This paper describes several methods to use BGP to shift traffic when under DDoS, and shows that a response playbook can provide a menu of responses that are options during an attack. To choose an appropriate response from this playbook, we also describe a new method to estimate true attack size, even though the operator’s view during the attack is incomplete. Finally, operator choices are constrained by distributed routing policies, and not all are helpful. We explore how specific anycast deployment can constrain options in this playbook, and are the first to measure how generally applicable they are across multiple anycast networks.
Acknowledgments: A S M Rizvi and John Heidemann’s work on this paper is supported, in part, by the DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I. Joao Ceron and Leandro Bertholdo’s work on this paper is supported by Netherlands Organisation for scientific research (4019020199), and European Union’s Horizon 2020 research and innovation program (830927). We would like to thank our anonymous reviewers for their valuable feedback. We are also grateful to the Peering and Tangled admins who allowed us to run measurements. We thank Dutch National Scrubbing Center for sharing DDoS data with us. We also thank Yuri Pradkin for his help to release our datasets.
Services on the public Internet are frequently scanned, then subject to brute-force and denial-of-service attacks. We would like to run such services stealthily, available to friends but hidden from adversaries. In this work, we propose a moving target defense named “Chhoyhopper” that utilizes the vast IPv6 address space to conceal publicly available services. The client and server hop to different IPv6 addresses in a pattern based on a shared, pre-distributed secret and the time of day. By hopping over a /64 prefix, services cannot be found by active scanners, and passively observed information is useless after two minutes. We demonstrate our system with the two important applications—SSH and HTTPS.
This work is supported, in part, by DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I, and by DARPA under Contract No. HR001120C0157.
A change in Internet use seen in Malaysia on 2020-04-02, present in our Covid-WFH data but discovered through our website.
From the abstract:
The Covid-19 pandemic disrupted the world as businesses and schools shifted to work-from-home (WFH), and comprehensive maps have helped visualize how those policies changed over time and in different places. We recently developed algorithms that infer the onset of WFH based on changes in observed Internet usage. Measurements of WFH are important to evaluate how effectively policies are implemented and followed, or to confirm policies in countries with less transparent journalism.This paper describes a web-based visualization system for measurements of Covid-19-induced WFH. We build on a web-based world map, showing a geographic grid of observations about WFH. We extend typical map interaction (zoom and pan, plus animation over time) with two new forms of pop-up information that allow users to drill-down to investigate our underlying data.We use sparklines to show changes over the first 6 months of 2020 for a given location, supporting identification and navigation to hot spots. Alternatively, users can report particular networks (Internet Service Providers) that show WFH on a given day.We show that these tools help us relate our observations to news reports of Covid-19-induced changes and, in some cases, lockdowns due to other causes. Our visualization is publicly available at https://covid.ant.isi.edu, as is our underlying data.
Erica Stutz completed her summer undergraduate research internship at ISI this summer, working with John Heidemann, Yuri Pradkin, and Xiao Song on her project “Visualizing COVID-19 Work-from-Home”.
In this project, Erica developed a new Covid-19 Work-From-Home website combinng Xiao WFH data with our existing outage website, and adding new interactive drill-down methods to display additional information to the user.
Visulizing Covid-19 work-from-home: here we look at China, Korea, and Japan and pop-up information about Laiwu, China. The popup shows WFH behavior for that location for the first 6 months of 2020.
We hope Erica’s new website makes it easier to evaluate COVID-19 WFH changes, and we look forward to continue to work with Erica on this topic.
Erica worked virtually at USC/ISI in summer 2021 as part of the (ISI Research Experiences for Undergraduates. We thank Jelena Mirkovic (PI) for coordinating the second year of this great program, and NSF for support through award #2051101.
At the end of June we had an ANT research group lunch to celebrate four (!) recent PhD defenses in 2020 and 2021: Hang Guo, Calvin Ardi, Lan Wei, and Abdul Qadeer. Although not everyone could be there (Hang has already moved for his new job), and the ANT lab includes a number of people outside of L.A. who could not make it, us students, staff, and family in L.A. had a great time at Vista del Mar Park near the beach!
A big thanks to Basileal Imana and ASM Rizvi for coordinating delivery of Ethiopian food for lunch.
We are also very thankful that vaccine availability in the U.S. is widespread and we were able to get together face-to-face after a year of Covid limitations. I’m happy that we’ve been able to do good work throughout the pandemic with remote collaboration tools and occasional on-site access, but it was nice to see old friends face-to-face again and share a meal. We hope the fall’s in-person classes at USC go well.