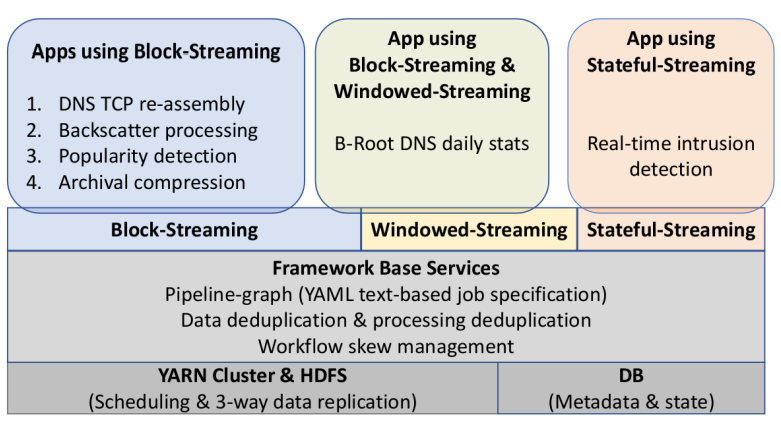
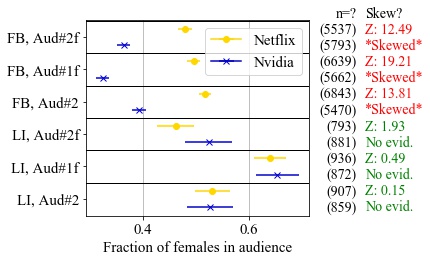
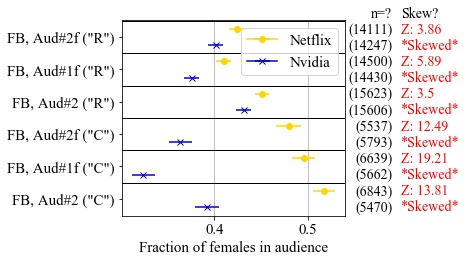
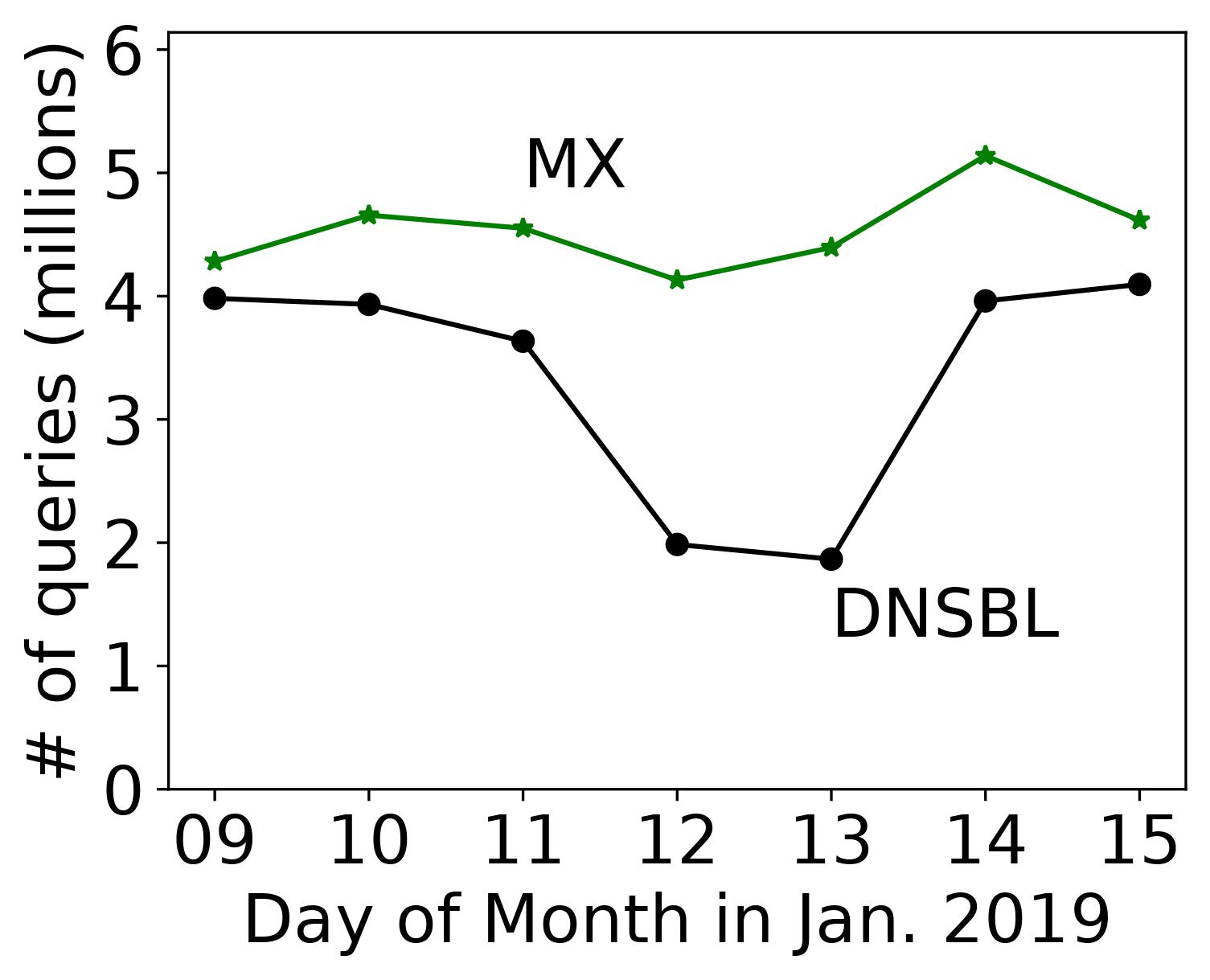
Basileal Imana presented the paper “Institutional Privacy Risks in Sharing DNS Data” by Basileal Imana, Aleksandra Korolova and John Heidemann at Applied Networking Research Workshop held virtually from July 26-28th, 2021.
From the abstract:
We document institutional privacy as a new risk
posed by DNS data collected at authoritative servers, even
after caching and aggregation by DNS recursives. We are the
first to demonstrate this risk by looking at leaks of e-mail
exchanges which show communications patterns, and leaks
from accessing sensitive websites, both of which can harm an
institution’s public image. We define a methodology to identify queries from institutions and identify leaks. We show the
current practices of prefix-preserving anonymization of IP
addresses and aggregation above the recursive are not sufficient to protect institutional privacy, suggesting the need for
novel approaches.
The data from this paper is available upon request, please see our project page.