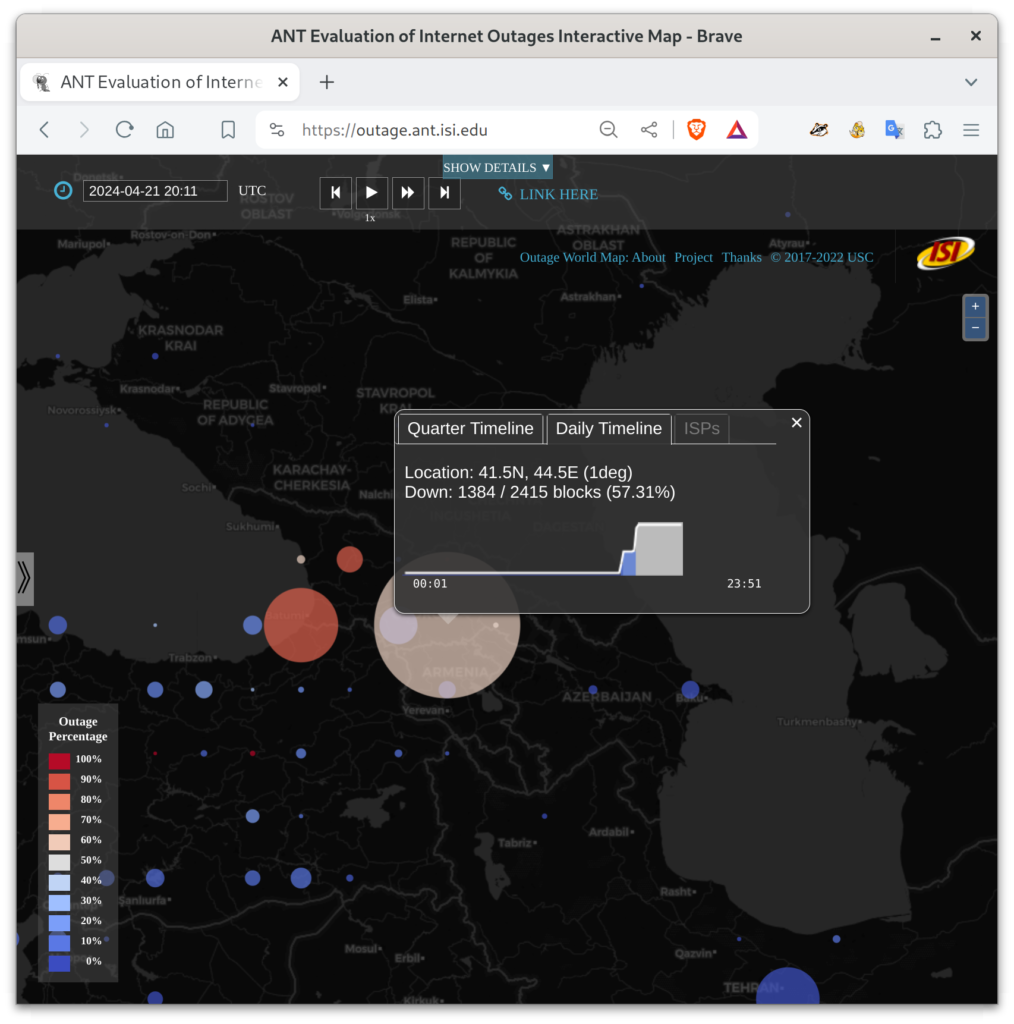
Starting on April 21, 2024, we observed a large Internet outage in the country Georgia. More than half the IP blocks in large parts of the country have become unreachable from the U.S., with the problem persisting for several days so far.
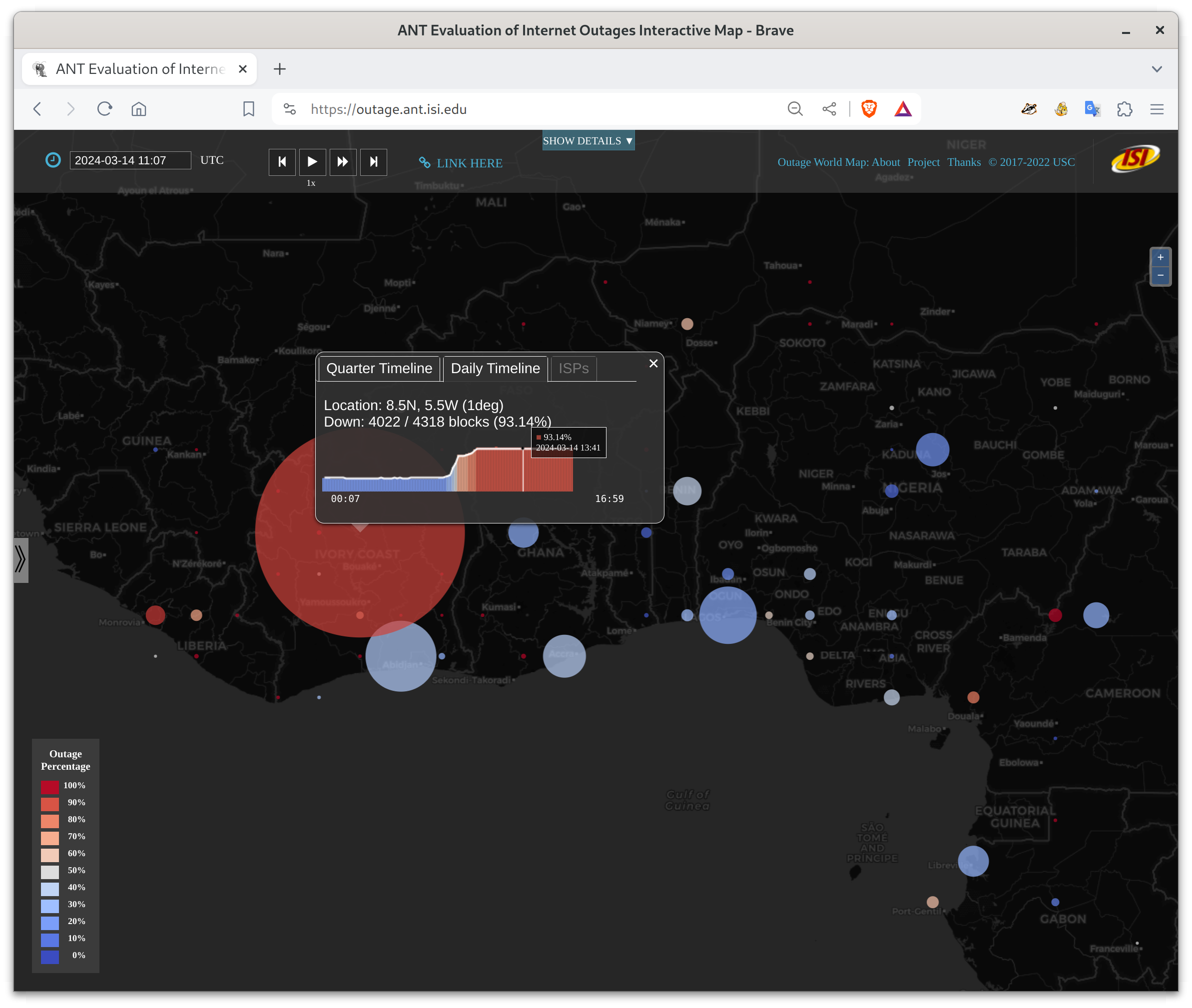
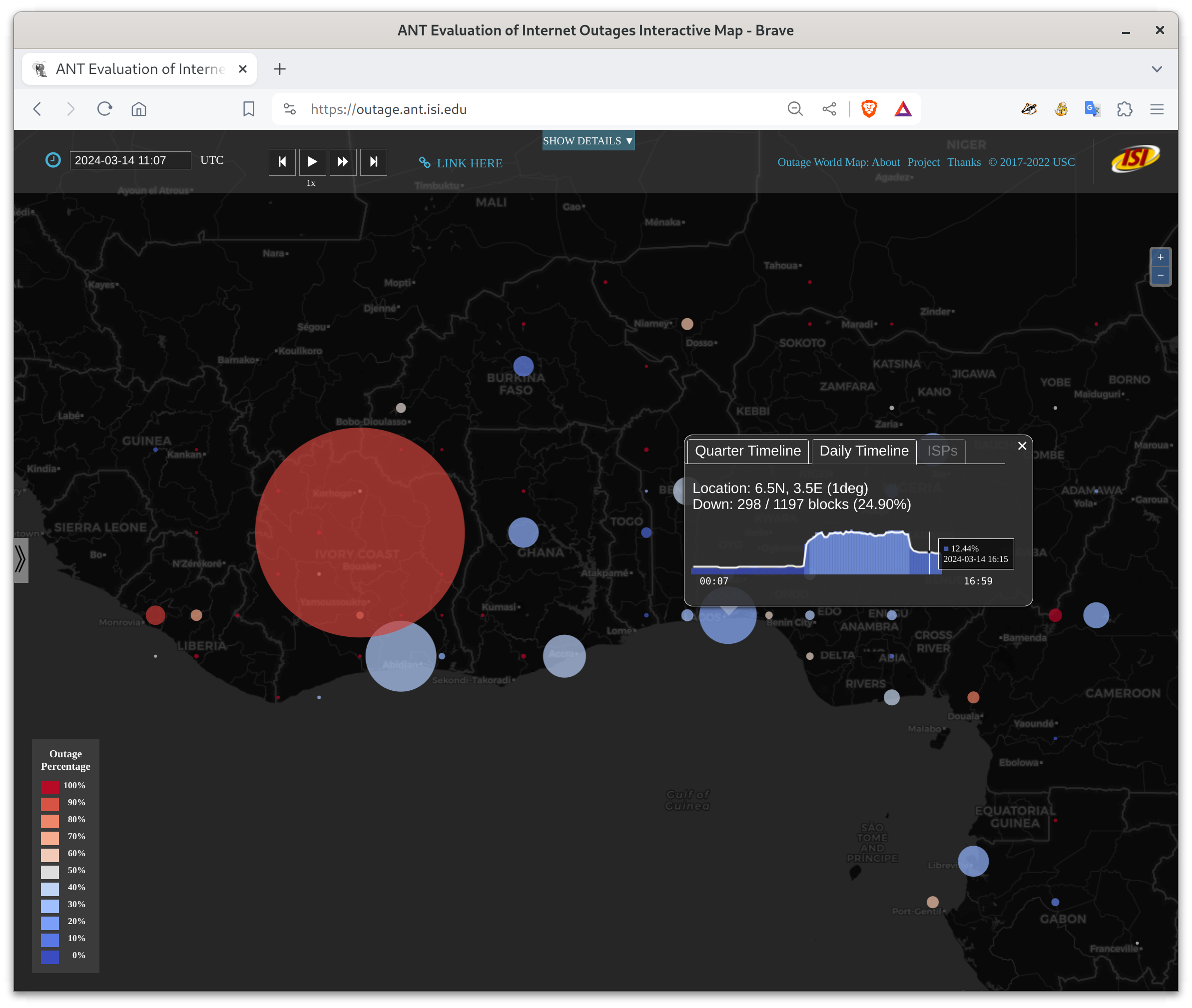
Serious Internet outages in Ivory Coast, beginning 2024-03-1409:00Z.
Fortunately some locations were able to partially recover from the problems, presumably by routing through different paths:
Lagos, Nigeria showed outages starting at 2024-03-14t08:00Z, with a partial recovery around t15:00Z.
The root cause for these outages is likely a problems in multiple undersea telecommunication cables, as has been reported in the Washington Post and the Guardian, among other places.
Our new paper “Anycast Polarization in The Wild” will appear at the 2024 Conference on Passive and Active Measurements (PAM 2024).
From the abstract:
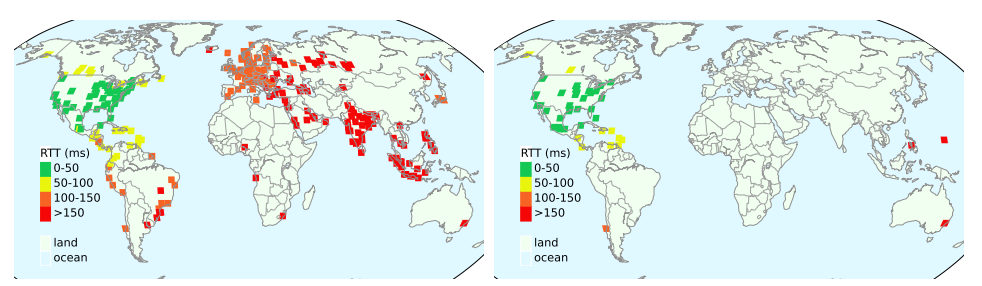
The left figure shows the impacts of polarization. The Dallas, USA site for a CDN is receiving traffic from all over the world due to polarization. The red dots indicate high latency from Europe and Asia, even if Europe and India have anycast sites in their continent. We show this type of polarization is not uncommon. The right figure shows how a change in the routing configuration can improve the polarization problem. We can see almost no red dots from Europe and Asia continents.
IP anycast is a commonly used method to associate users with services provided across multiple sites, and if properly used, it can provide efficient access with low latency. However, prior work has shown that polarization can occur in global anycast services, where some users of that service are routed to an anycast site on another continent, adding 100 ms or more latency compared to a nearby site. This paper describes the causes of polarization in real-world anycast and shows how to observe polarization in third-party anycast services. We use these methods to look for polarization and its causes in 7986 known anycast prefixes. We find that polarization occurs in more than a quarter of anycast prefixes, and identify incomplete connectivity to Tier-1 transit providers and route leakage by regional ISPs as common problems. Finally, working with a commercial CDN, we show how small routing changes can often address polarization, improving latency for 40% of clients, by up to 54%.
This paper is a joint work by ASM Rizvi from USC/ISI and Akamai Technologies, Tingshan Huang from Akamai Technologies, Rasit Esrefoglu from Akamai Technologies, and John Heidemann from USC/ISI. ASM Rizvi and John Heidemann’s work was partially supported by DARPA under Contract No. HR001120C0157. John Heidemann’s work was also partially supported by the NFS projects CNS-2319409, CRI-8115780, and CNS-1925737. ASM Rizvi’s work was begun while on an internship at Akamai.
Our new paper “Ebb and Flow: Implications of ISP Address Dynamics” will appear at the 2024 Conference on Passive and Active Measurements (PAM 2024).
From the abstract:
[Baltra24a, figure 1]: A known ISP maintenance event, where we see users (green dots) ove from the left block to the right block for about 15 days. The bottom graphs show what addresses respond, as observed by Trinocular. We confirm this result from a RIPE Atlas probe that also moved over this time. This kind of event is detected by the ISP Availability Sensing (IAS), a new algorithm explored in this paper.
Address dynamics are changes in IP address occupation as users come and go, ISPs renumber them for privacy or for routing maintenance. Address dynamics affect address reputation services, IP geolocation, network measurement, and outage detection, with implications of Internet governance, e-commerce, and science. While prior work has identified diurnal trends in address use, we show the effectiveness of Multi-Seasonal-Trend using Loess decomposition to identify both daily and weekly trends. We use ISP-wide dynamics to develop IAS, a new algorithm that is the first to automatically detect ISP maintenance events that move users in the address space. We show that 20% of such events result in /24 IPv4 address blocks that become unused for days or more, and correcting nearly 41k false outages per quarter. Our analysis provides a new understanding about ISP address use: while only about 2.8% of ASes (1,730) are diurnal, some diurnal ASes show more than 20% changes each day. It also shows greater fragmentation in IPv4 address use compared to IPv6.
This paper is a joint work of Guillermo Baltra, Xiao Song, and John Heidemann. Datasets from this paper can be found at https://ant.isi.edu/datasets/outage. This work was supported by NSF (MINCEQ, NSF 2028279; EIEIO CNS-2007106.
Number of ASes that are time providers per country (Figure 8 from [Moura24a]).
Time synchronization is of paramount importance on the Internet, with the Network Time Protocol (NTP) serving as the primary synchronization protocol. The NTP Pool, a volunteer-driven initiative launched two decades ago, facilitates connections between clients and NTP servers. Our analysis of root DNS queries reveals that the NTP Pool has consistently been the most popular time service. We further investigate the DNS component (GeoDNS) of the NTP Pool, which is responsible for mapping clients to servers. Our findings indicate that the current algorithm is heavily skewed, leading to the emergence of time monopolies for entire countries. For instance, clients in the US are served by 551 NTP servers, while clients in Cameroon and Nigeria are served by only one and two servers, respectively, out of the 4k+ servers available in the NTP Pool. We examine the underlying assumption behind GeoDNS for these mappings and discover that time servers located far away can still provide accurate clock time information to clients. We have shared our findings with the NTP Pool operators, who acknowledge them and plan to revise their algorithm to enhance security.
This paper is a joint work of
Giovane C. M. Moura1,2, Marco Davids1, Caspar Schutijser1, Christian Hesselman1,3, John Heidemann4,5, and Georgios Smaragdakis2 with 1: SIDN Labs, 2 Technical University, Delft, 3: the University of Twente, 4: the University of Southern California/Information Sciences Institute, 5: USC/Computer Science Dept. This work was supported by the RIPE NCC (via Atlas), the Root Operators and DNS-OARC (for DITL), SIDN Labs time.nl project, the Twente University Centre for Cyber Security Resarch, NSF projects CNS-2212480, CNS-2319409, the European Research Council ResolutioNet (679158), Duth 6G Future Network Services project, the EU programme Horizon Europe grants SEPTON (101094901), MLSysOps (101092912), and TANGO (101070052).
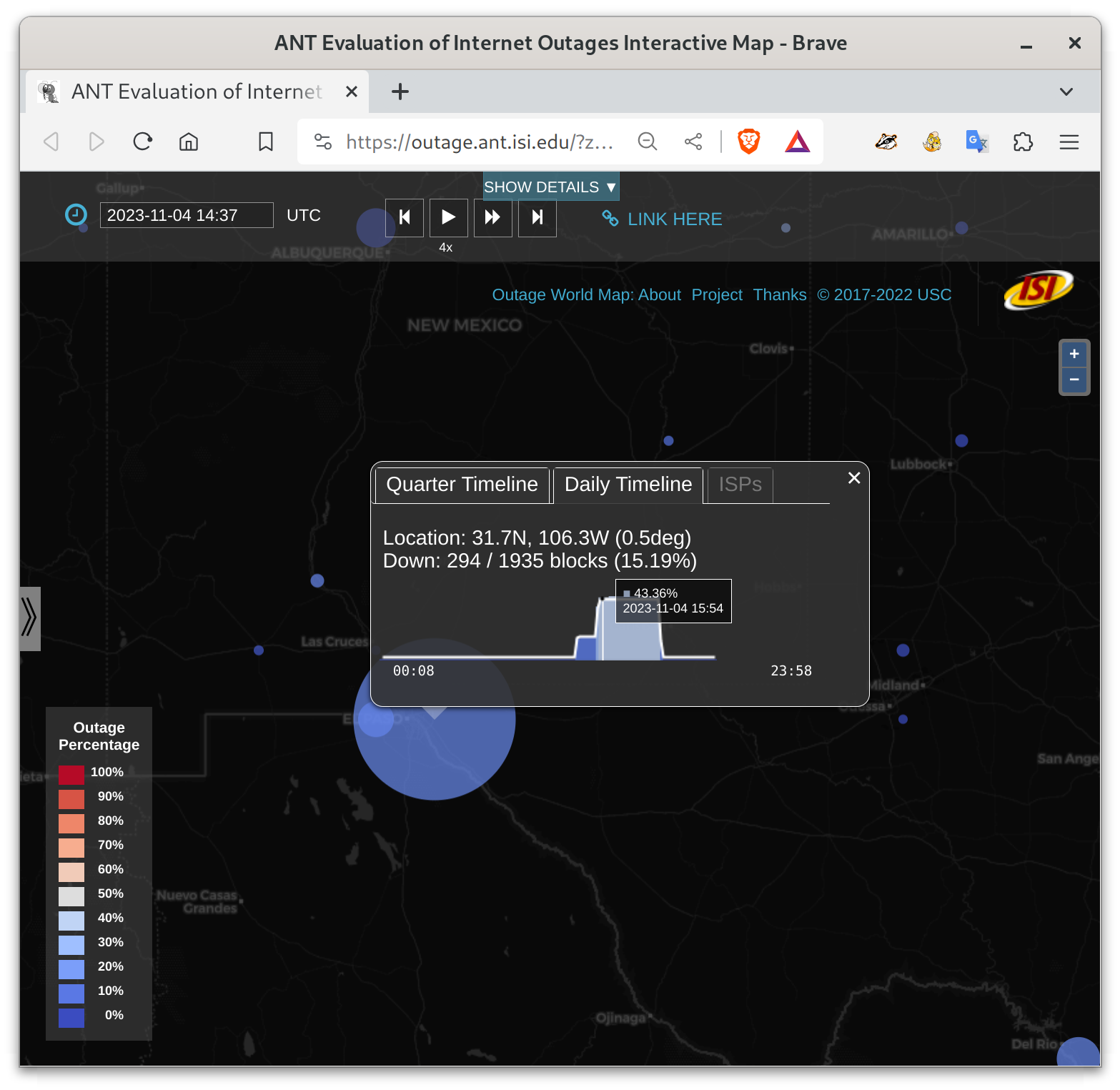
News reports indicate that Spectrum had a cable cut.
Trinocular showed an outage from 8:40am to 1:05pm (mountain time zone), with an smaller initial outage starting at 7am (2023-11-04t15:40 to t20:00 UTC, possibly starting at 14:00 UTC). This outage was quite severe, affecting more than 40% of the local networks that we monitor.
Cable cuts are hard to deal with, and we’re happy that they were able to restore service relatively quickly!
I would like to congratulate Dr. Guillermo Baltra for defending his PhD at the University of Southern California in August 2023 and completing his doctoral dissertation “Improving network reliability using a formal definition of the Internet core”.
Guillermo Baltra (right) and his thesis advisor.
From the abstract:
After 50 years, the Internet is still defined as “a collection of interconnected networks”. Yet seamless, universal connectivity is challenged in several ways. Political pressure threatens fragmentation due to de-peering; architectural changes such as carrier-grade NAT, the cloud makes connectivity indirect; firewalls impede connectivity; and operational problems and commercial disputes all challenge the idea of a single set of “interconnected networks”. We propose that a new, conceptual definition of the Internet core helps disambiguate questions in analysis of network reliability and address space usage.
We prove this statement through three studies. First, we improve coverage of outage detection by dealing with sparse sections of the Internet, increasing from a nominal 67% responsive /24 blocks coverage to 96% of the responsive Internet. Second, we provide a new definition of the Internet core, and use it to resolve partial reachability ambiguities. We show that the Internet today has peninsulas of persistent, partial connectivity, and that some outages cause islands where the Internet at the site is up, but partitioned from the main Internet. Finally, we use our definition to identify ISP trends, with applications to policy and improving outage detection accuracy. We show how these studies together thoroughly prove our thesis statement. We provide a new conceptual definition of “the Internet core” in our second study about partial reachability. We use our definition in our first and second studies to disambiguate questions about network reliability and in our third study, to ISP address space usage dynamics.
Guillermo’s PhD work was supported by NSF grants CNS-1806785, CNS-2007106 and NSF-2028279 and DH S&T Cyber Security Division contract 70RSAT18CB0000014 and a DHS contract administred by AFRL as contract FA8750-18-2-0280, to USC Viterbi, the Armada de Chile, and the Agencia Nacional de Investigación y Desarrollo de Chile (ANID).
Please see his individual publications for what data is available from his research; his results are also in use in ongoing Trinocular outage detection datasets.
I would like to congratulate Dr. Basileal Imana for defending his PhD at the University of Southern California in August 2023 and completing his doctoral dissertation “Methods for Auditing Social Media Algorithms in the Public Interest”.
Basi at his PhD hooding in May 2023 with his thesis advisors.
From the abstract:
Social-media platforms are entering a new era of increasing scrutiny by public interest groups and regulators. One reason for the increased scrutiny is platform-induced bias in how they deliver ads for life opportunities. Certain ad domains are legally protected against discrimination, and even when not, some domains have societal interest in equitable ad delivery. Platforms use relevance-estimator algorithms to optimize the delivery of ads. Such algorithms are proprietary and therefore opaque to outside evaluation, and early evidence suggests these algorithms may be biased or discriminatory. In response to such risks, the U.S. and the E.U. have proposed policies to allow researchers to audit platforms while protecting users’ privacy and platforms’ proprietary information. Currently, no technical solution exists for implementing such audits with rigorous privacy protections and without putting significant constraints on researchers. In this work, our thesis is that relevance-estimator algorithms bias the delivery of opportunity ads, but new auditing methods can detect that bias while preserving privacy.
We support our thesis statement through three studies. In the first study, we propose a black-box method for measuring gender bias in the delivery of job ads with a novel control for differences in job qualification, as well as other confounding factors that influence ad delivery. Controlling for qualification is necessary since qualification is a legally acceptable factor to target ads with, and we must separate it from bias introduced by platforms’ algorithms. We apply our method to Meta and LinkedIn, and demonstrate that Meta’s relevance estimators result in discriminatory delivery of job ads by gender. In our second study, we design a black-box methodology that is the first to propose a means to draw out potential racial bias in the delivery of education ads. Our method employs a pair of ads that are seemingly identical education opportunities but one is of inferior quality tied with a historical societal disparity that ad delivery algorithms may propagate. We apply our method to Meta and demonstrate their relevance estimators racially bias the delivery of education ads. In addition, we observe that the lack of access to demographic attributes is a growing challenge for auditing bias in ad delivery. Motivated by this challenge, we make progress towards enabling use of inferred race in black-box audits by analyzing how inference error can lead to incorrect measurement of skew in ad delivery. Going beyond the domain-specific and black-box methods we used in our first two studies, our final study proposes a novel platform-supported framework to allow researchers to audit relevance estimators that is generalizable to studying various categories of ads, demographic attributes and target platforms. The framework allows auditors to get privileged query-access to platforms’ relevance estimators to audit for bias in the algorithms while preserving the privacy interests of users and platforms. Overall, our first two studies show relevance-estimator algorithms bias the delivery of job and education ads, and thus motivate making these algorithms the target of platform-supported auditing in our third study. Our work demonstrates a platform-supported means to audit these algorithms is the key to increasing public oversight over ad platforms while rigorously protecting privacy.
Basi’s PhD work was co-advised by Aleksandra Korolova and John Heidemann, and supported by grants from the Rose Foundation and the NSF (CNS-1755992, CNS-1916153, CNS-1943584, CNS-1956435, and CNS-1925737.) Please see his individual publications for what data is available from his research.
Sandeep Muthu completed his summer undergraduate research internship at ISI this summer, working with John Heidemann and Yuri Pradkin on his project “Determining the Risks of Tunnels Over the Internet”.
In his project, Sandeep examined how unauthenticated tunneling protocols can be infiltrated, and how often they are used in the Internet. He demonstrated that tunnels can be exploited in the DETER testbed, and showed that there are many tunnels in general use based on analysis of anonymized IXP data.
Sandeep Muthu sharing his poster at the ISI undergraduate research poster session in July 2023.
Sandeep’s work was part of the ISI Research Experiences for Undergraduates program at USC/ISI. We thank Jelena Mirkovic (PI) for coordinating another year of this great program, and NSF for support through award #2051101. We also thank the University of Memphis (Christos Papadopoulos) and FIU
Network traffic is often diurnal, with some networks peaking during the workday and many homes during evening streaming hours. Monitoring systems consider diurnal trends for capacity planning and anomaly detection. In this paper, we reverse this inference and use diurnal network trends and their absence to infer human activity. We draw on existing and new ICMP echo-request scans of more than 5.2M /24 IPv4 networks to identify diurnal trends in IP address responsiveness. Some of these networks are change-sensitive, with diurnal patterns correlating with human activity. We develop algorithms to clean this data, extract underlying trends from diurnal and weekly fluctuation, and detect changes in that activity. Although firewalls hide many networks, and Network Address Translation often hides human trends, we show about 168k to 330k (3.3–6.4% of the 5.2M) /24 IPv4 networks are change-sensitive. These blocks are spread globally, representing some of the most active 60% of 2 × 2◦ geographic gridcells, regions that include 98.5% of ping-responsive blocks. Finally, we detect interesting changes in human activity. Reusing existing data allows our new algorithm to identify changes, such as Work-from-Home due to the global reaction to the emergence of Covid-19 in 2020. We also see other changes in human activity, such as national holidays and government-mandated curfews. This ability to detect trends in human activity from the Internet data provides a new ability to understand our world, complementing other sources of public information such as news reports and wastewater virus observation.
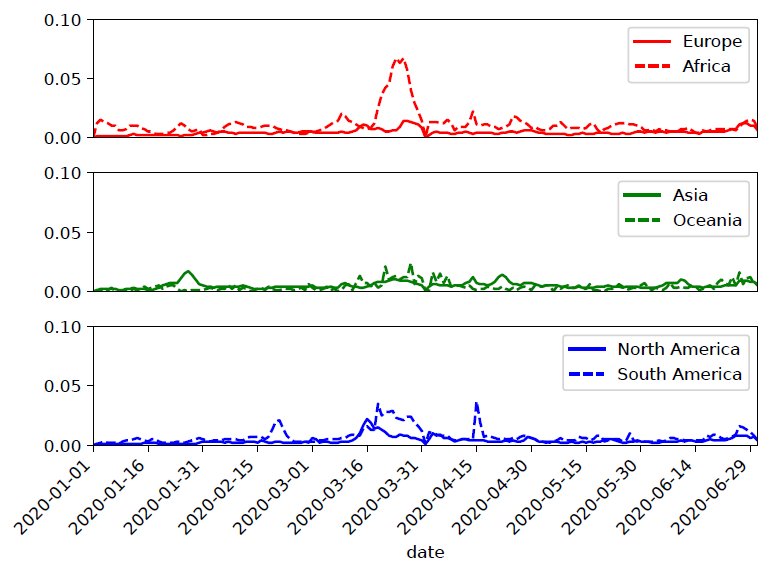
The human-activity changes for 2020h1 by continent. It shows the global count of downward trends in changes for each continent over six months. Although aggregated, we see several trends. First, the large percentage of changes in Asia around 2020-01-20 (at (i)) might correspond to the Spring Festival, celebrated widely in many Asian countries and regions. Most of the rest of the world showed significant changes around 2020-03-20 (at (ii) and (iii)), corresponding to initial Covid pandemic control measures.
This paper is a joint work of Xiao Song from USC, Guillermo Baltra from USC, and John Heidemann from USC/ISI. Datasets from this paper can be found at https://ant.isi.edu/datasets/ip_accumulation. This work was supported by NSF (MINCEQ, NSF 2028279; EIEIO CNS-2007106; and InternetMap (CSN-2212480).