We have released a new technical report: “Auditing for Bias in Ad Delivery Using Inferred Demographic Attributes”, available at https://arxiv.org/abs/2410.23394.
From the abstract:
[Imana23c, figure 3]: Detecting racial skew with BISG-based inference is less sensitive (shown by the lower test statistic Z) than either knowing true-race, or using our improved version that reflects potential inference error. More samples and larger underlying skew make the range of confusion smaller, but do not eliminate it.
Auditing social-media algorithms has become a focus of public-interest research and policymaking to ensure their fairness across demographic groups such as race, age, and gender in consequential domains such as the presentation of employment opportunities. However, such demographic attributes are often unavailable to auditors and platforms. When demographics data is unavailable, auditors commonly infer them from other available information. In this work, we study the effects of inference error on auditing for bias in one prominent application: black-box audit of ad delivery using paired ads. We show that inference error, if not accounted for, causes auditing to falsely miss skew that exists. We then propose a way to mitigate the inference error when evaluating skew in ad delivery algorithms. Our method works by adjusting for expected error due to demographic inference, and it makes skew detection more sensitive when attributes must be inferred. Because inference is increasingly used for auditing, our results provide an important addition to the auditing toolbox to promote correct audits of ad delivery algorithms for bias. While the impact of attribute inference on accuracy has been studied in other domains, our work is the first to consider it for black-box evaluation of ad delivery bias, when only aggregate data is available to the auditor.
This technical report is joint work of Basilial Imana and Aleksandra Korolova (both of Princeton) and John Heidemann (USC/ISI). This work was supported by the NSF via CNS-1956435, CNS-2344925, and CNS-2319409 (the InternetMap project).
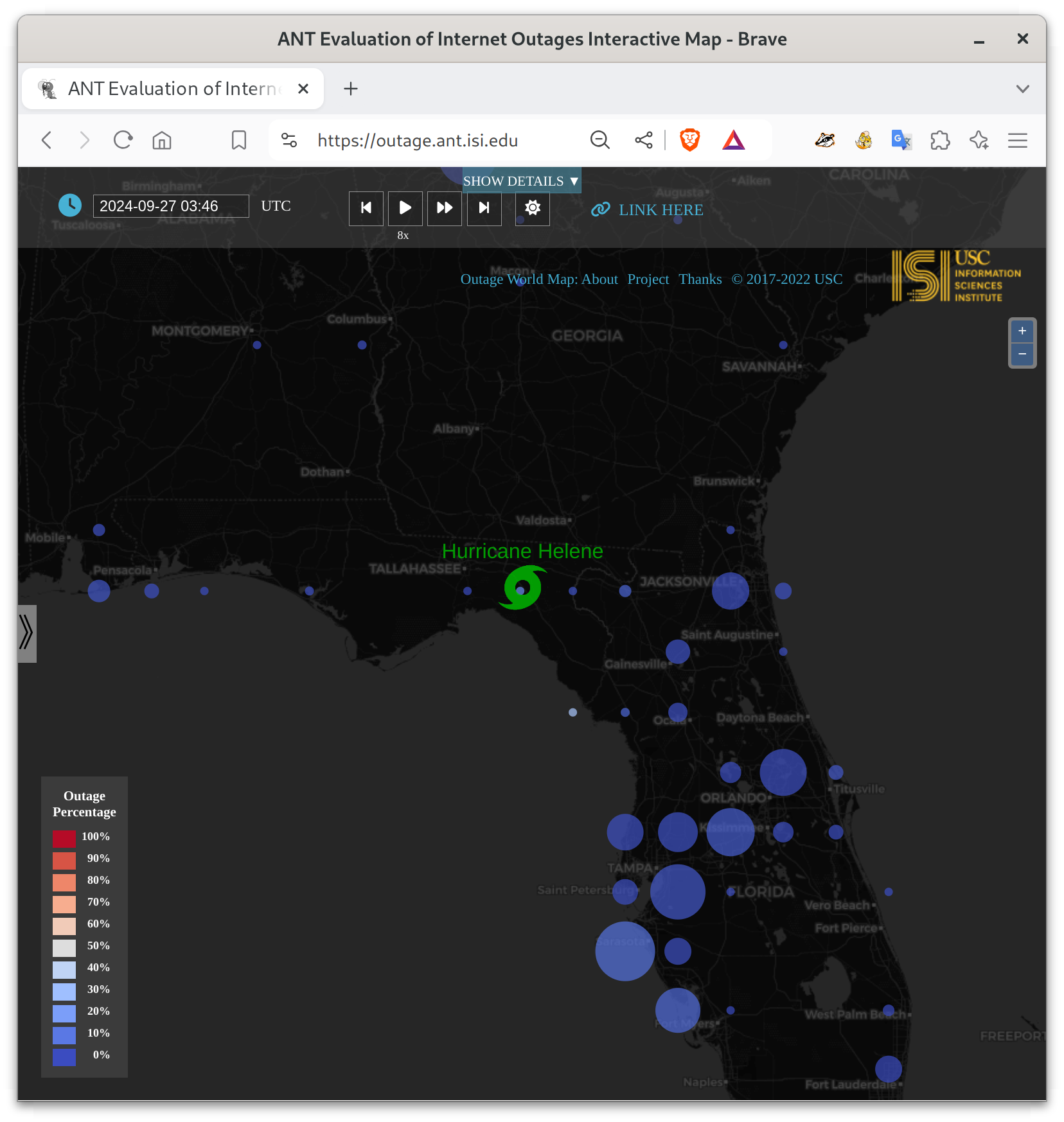
Hurricane Helene made landfall in the U.S. at 11:10pm EDT Sept. 26 (2024-09-27t03:10Z) near Tallahassee, Florida, and we’ve been watching it in the Trinocular Internet Outage system.
Flordia Internet infrasructure appears to have done quite well, with relatively few Internet outages. Here is the view 4.5 hours after landfall, at 3:40am EDT Sept. 27 (2024-09-27t07:40Z), when the eye was already over southern Georgia:
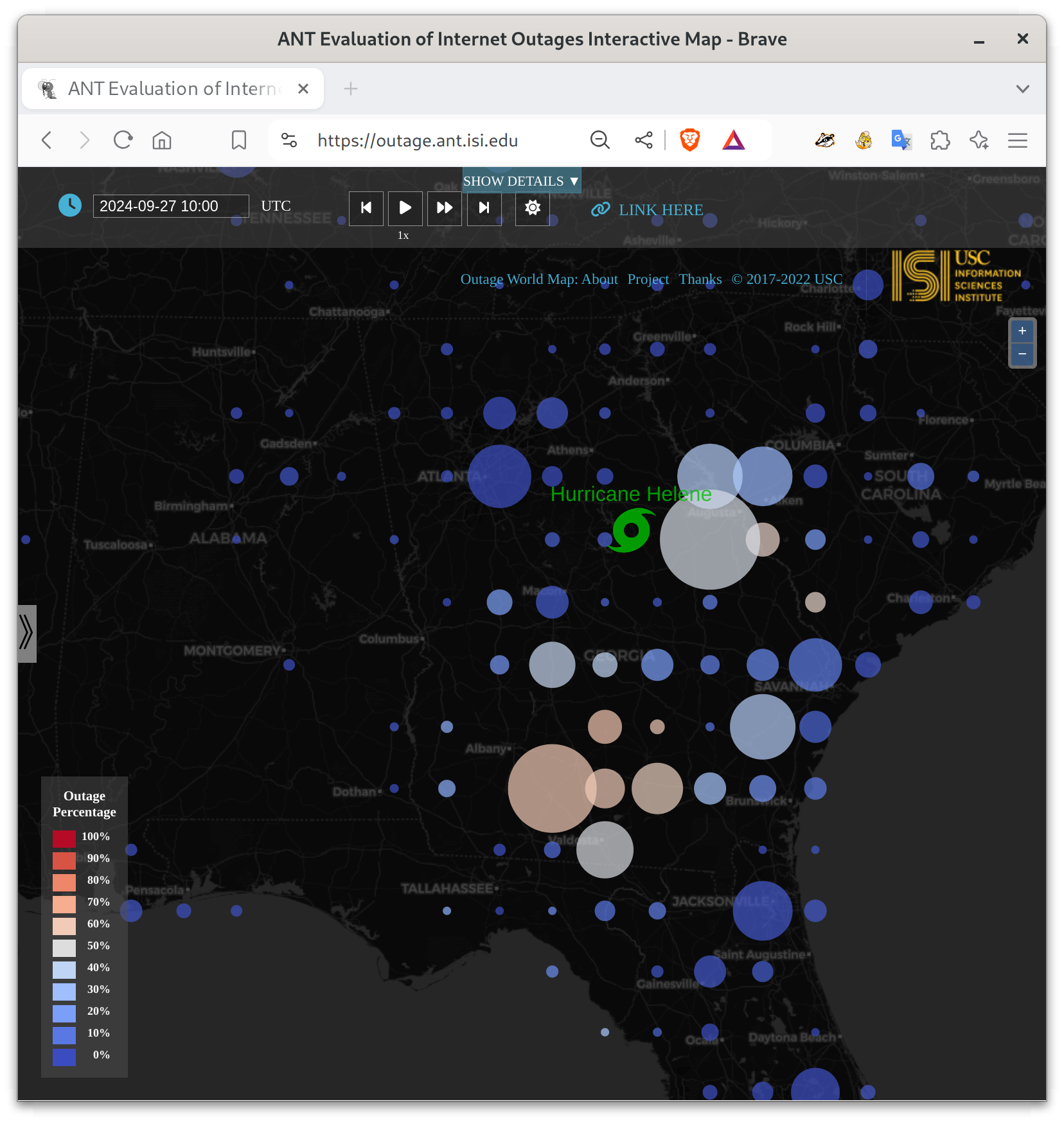
However, storm damange resulted in many outages across Georgia at daybreak. Here is 11 hours after landfall, at 6am EDT Sept 27 (2024-09-27t10:00):
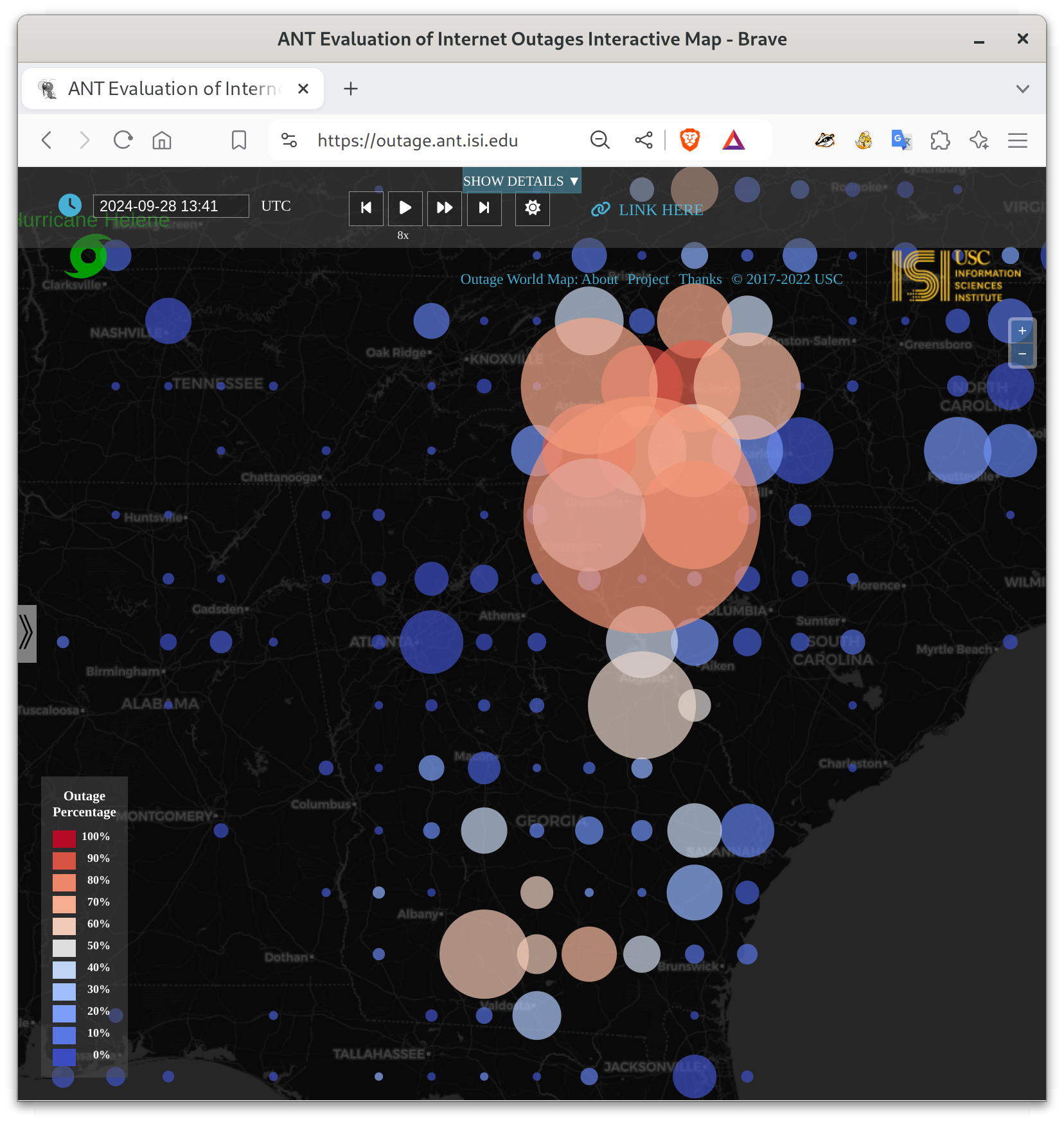
Fortunately the Internet infrastructure in Georgia was quick to recover, suggesting most Internet outages were power loss. We wish the best for those in Kentucky, and for those with physical storm damage and coping with flooding.
There was a huge Internet outage on June 19, 2024. It affected millions of people, interfering with their ability to travel, interact with friends and family, and with businesses to communicate with their customers and place orders. It cost the global economy millions of dollars.
And it had nothing to do with CrowdStrike.
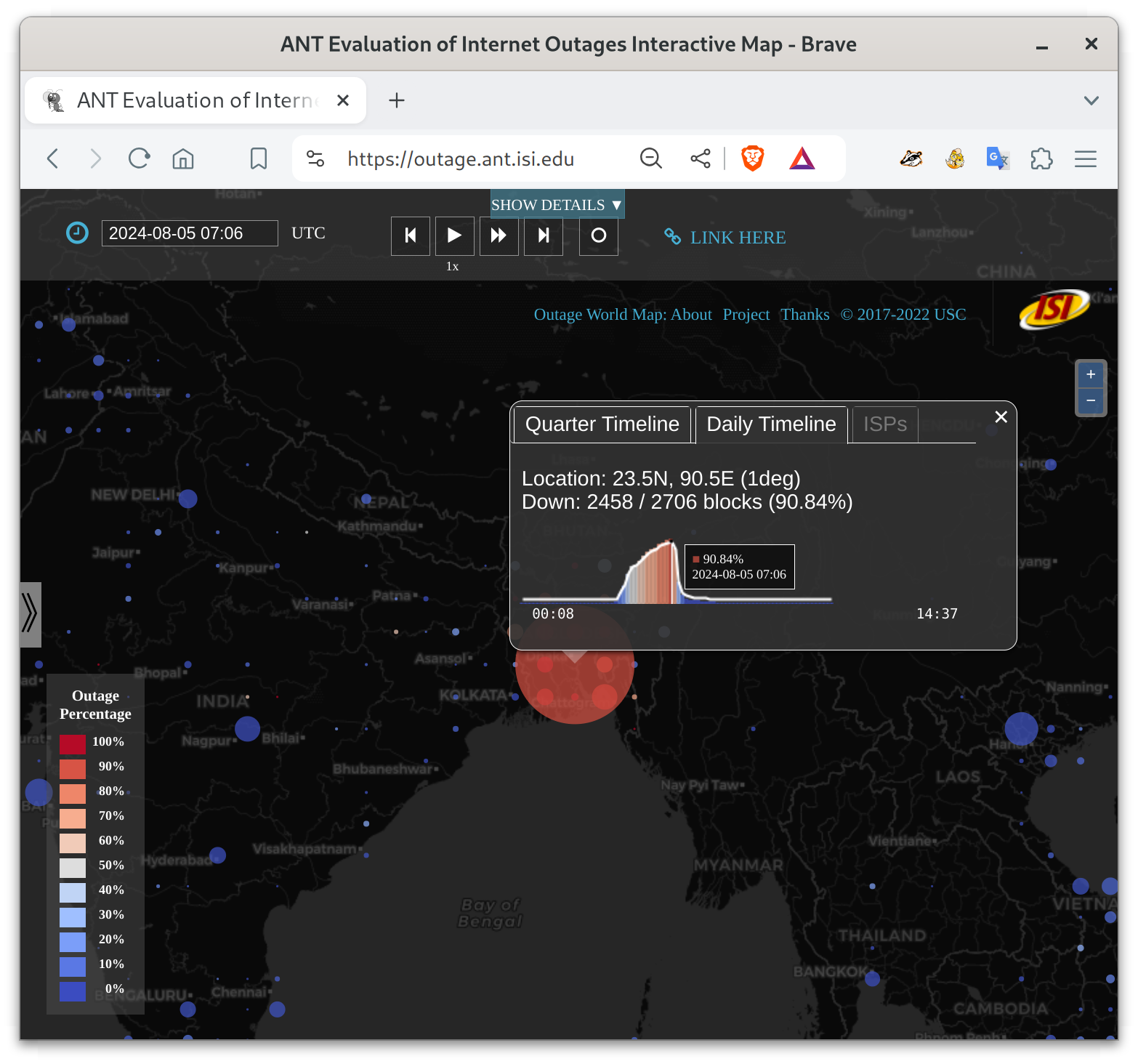
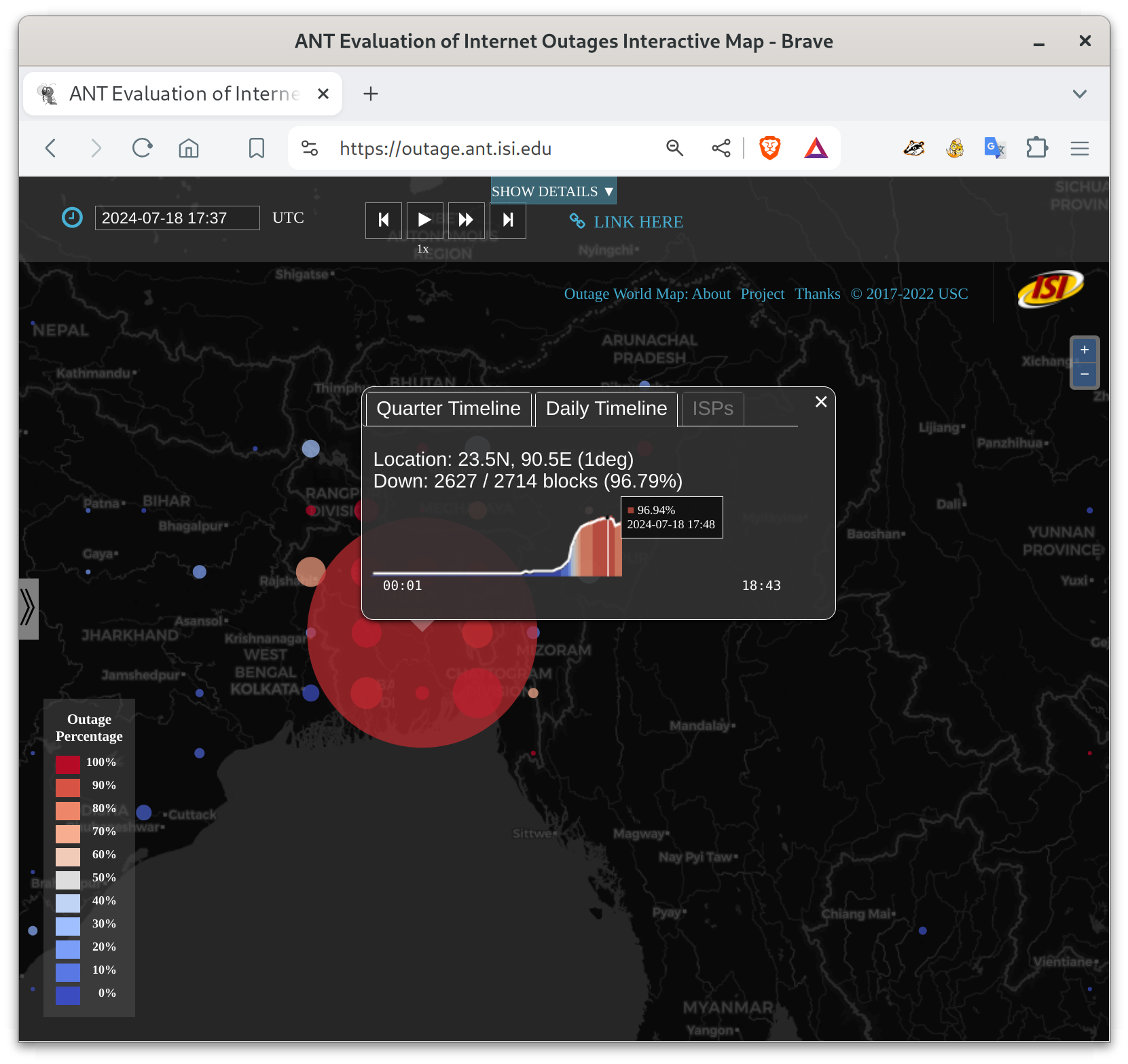
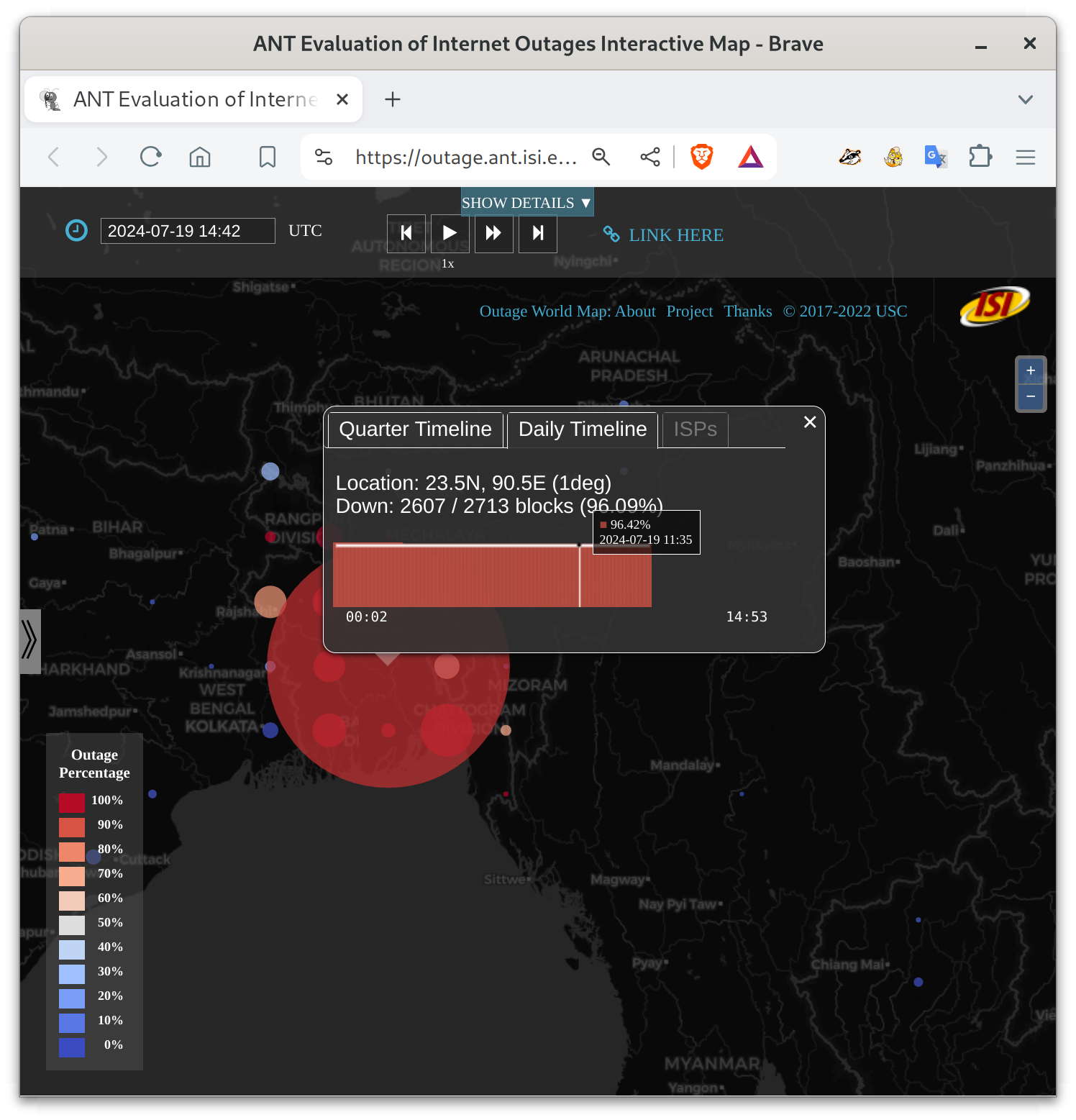
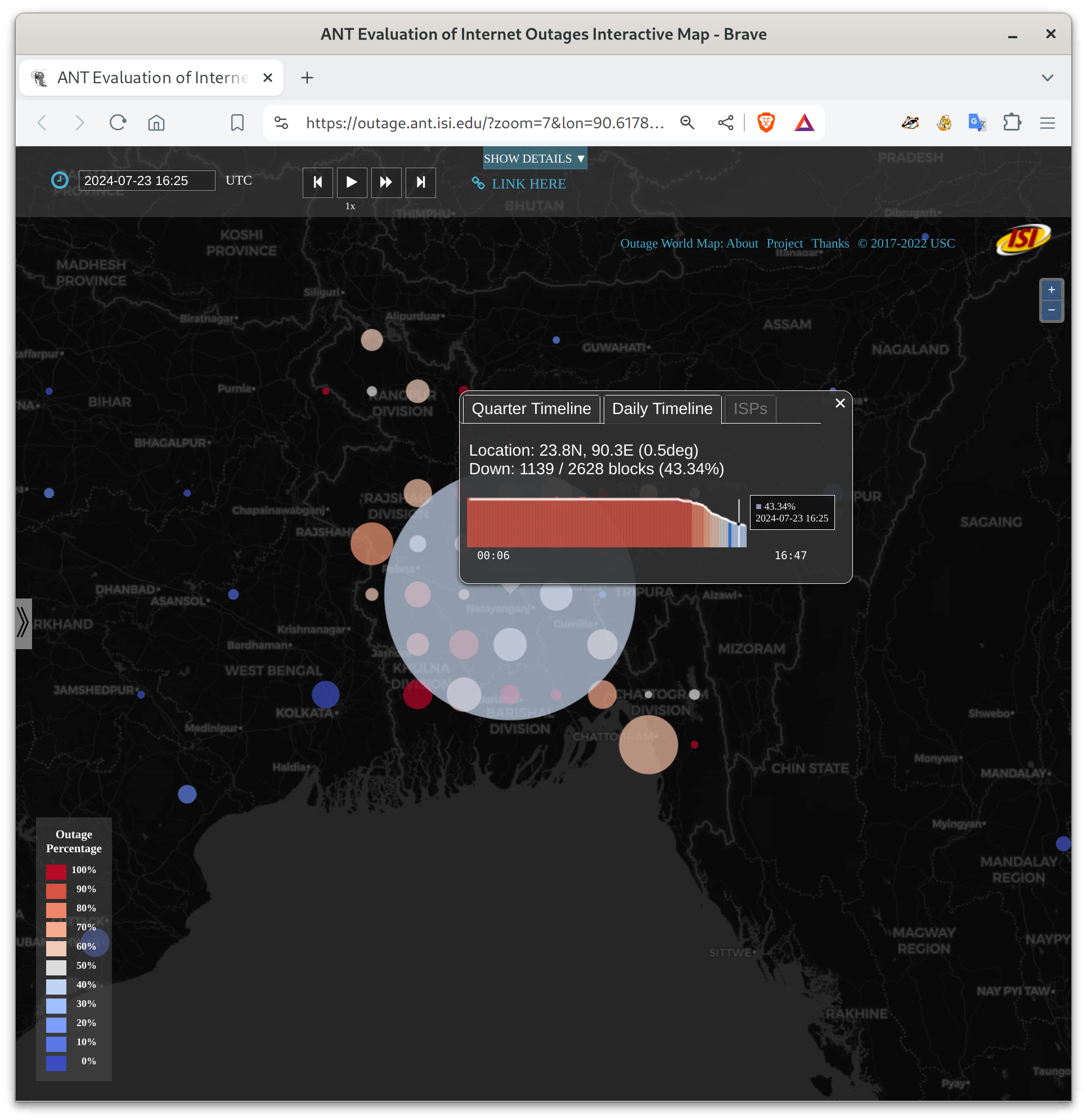
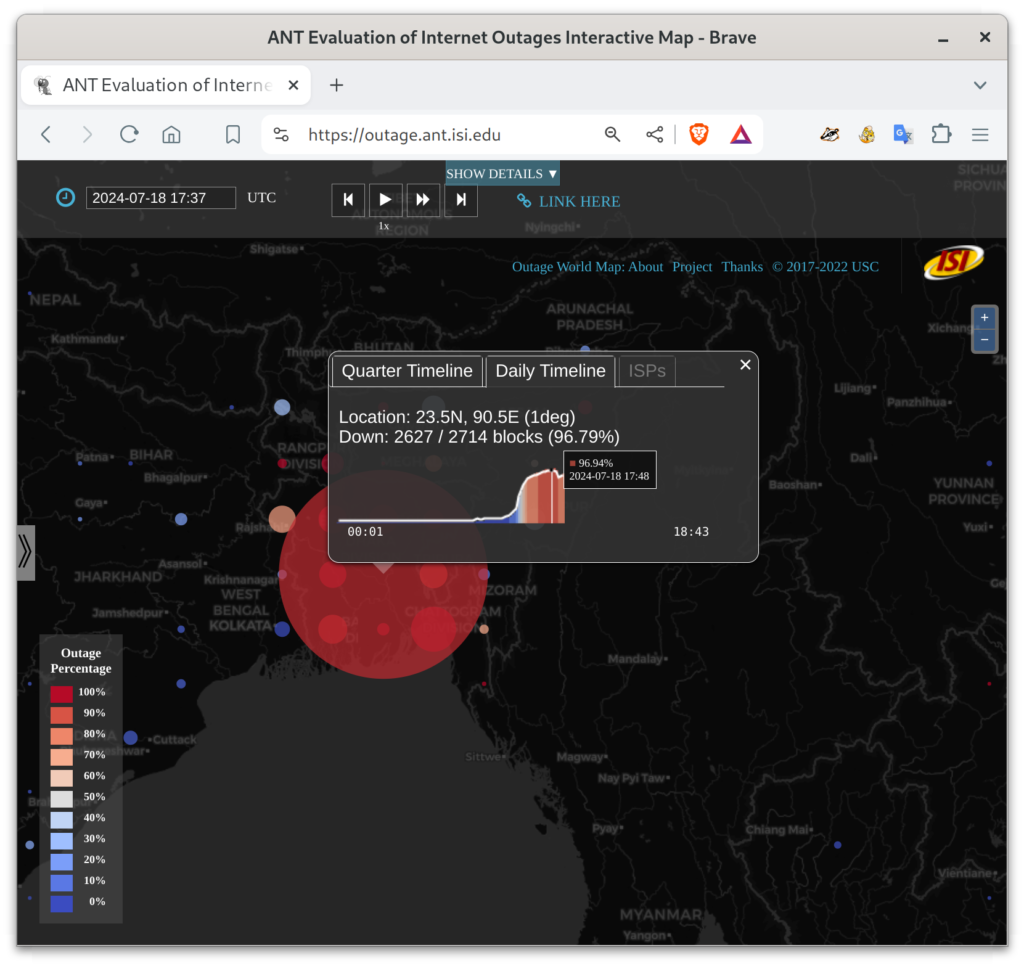
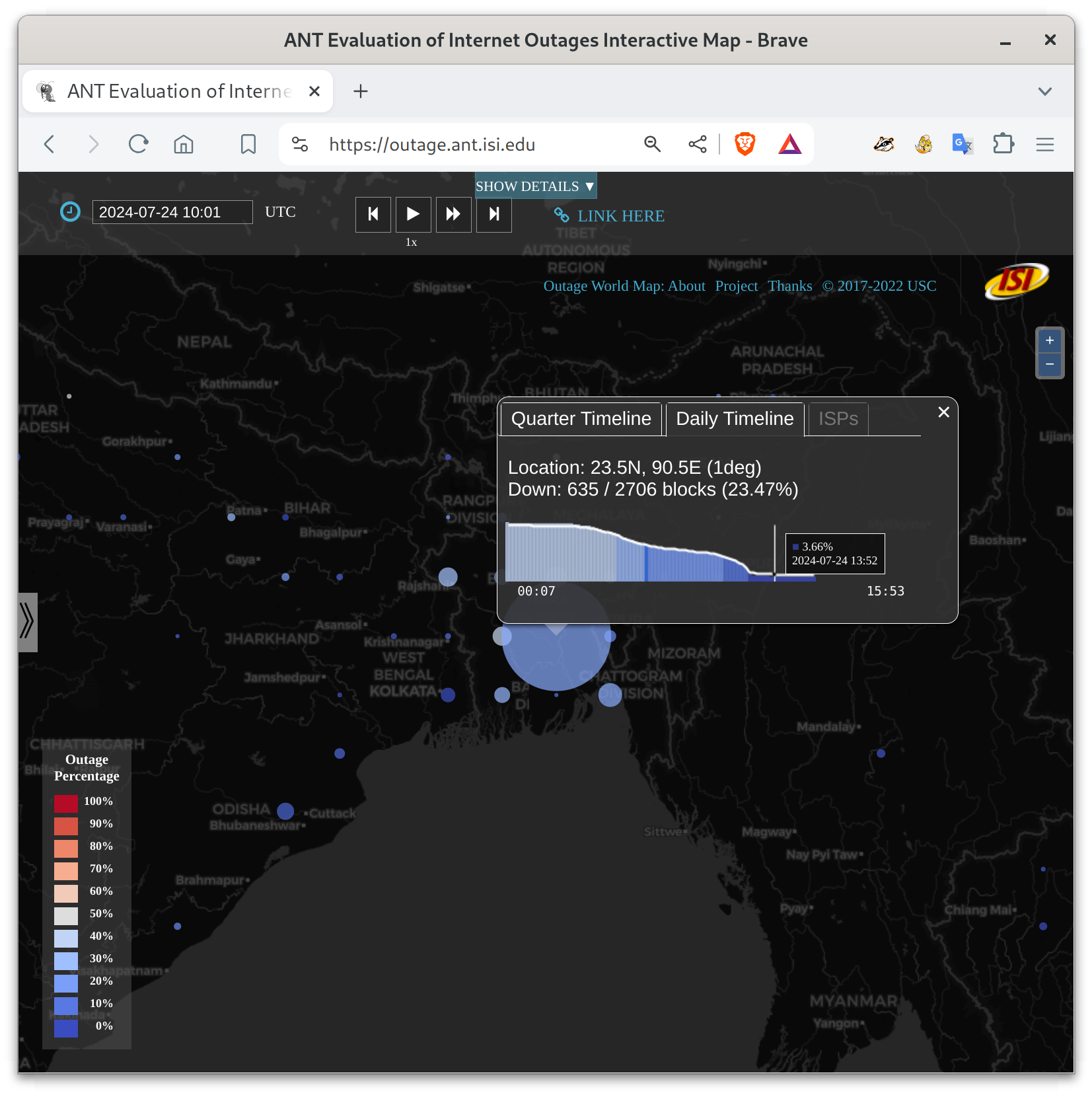
I’m talking about the the 5-day near-total shutdown of the Internet in Bangladesh, from 2024-07-18t15:00Z (9pm July 18 local time in Bangladesh) until about 2024-07-23t13:00Z (7pm July 23 local time). For most of that period, pretty much all Bangladeshi networks were down. People could not communicate with each other. Here are the start, middle, recovery pictures from our blog entry:
These figures show Bangladesh, with circles whose size indicates the number of networks that are out in each part of the country. Circle color indicates the percentage of networks that are out–red is near 100% networks unreachable. My research group measures Internet outages, and you can look at what happened in our website. Red basically never happens for big countries, at least since the 2011 Egyptian revolution.
Bangladesh had civil unrest, protests, and riots due to an unpopular employment law (as reported by many organizations, including the New York Times). The government chose to shut down their Internet (as reported by AP, and others). They restored services on July 24, but I am told they are still blocking several social media services.
What does this have to do with CloudStrike?
Well, nothing. But you may have heard that CloudStrike had a software-update that went wrong, also on July 19. It also interfered with millions of people’s ability to travel, interact with friends and family, and with businesses to communicate with their customers and place orders, as it crashed millions of computers running Microsoft Windows and left them difficult to recover.
But the CloudStrike software glitch was not an Internet outage.
Yes, millions of computers failed. But the Internet was never affected by the failure of CloudStrike computers. Anyone could use the Internet just fine last week, provided they were using services that did not depend on Microsoft Windows. And lots of the computers that failed (like flight status kiosks in airports) were not on the public Internet.
CloudStrike was a massive software failure, but not an Internet outage.
I mention this because I heard multiple media sources discuss the CloudStrike-caused Internet outage. Most prominent was this article by Barath Raghavan and Bruce Schneier on Lawfare (and then reposted on Schneier’s blog), that starts “Friday’s massive internet outage, caused by a mid-sized tech company called CrowdStrike, disrupted major airlines, hospitals, and banks.” They point to “brittleness of infrastructure” as a risk. The article is true, except for the word “Internet”. The New York times called it a “tech outage“, and us in the field should be as careful about our terms.
By analogy, when two Boeing 373 MAX airliners crashed in 2019 and 2020, we did not call out the “massive air traffic control crash”, we correctly pointed at aircraft failures, and eventually at software and design problems in that specific aircraft.
We should not call all computer failures an Internet outage, when the problem is not about network communication. To improve our computing world, we must identify problems correctly.
Because when a nation of 170 million people goes offline, that’s a big deal, too. And that’s not fixable by rebooting.
We have released a new technical report: “Reasoning about Internet Connectivity”, available at https://arxiv.org/abs/2407.14427.
From the abstract:
Innovation in the Internet requires a global Internet core to enable communication between users in ISPs and services in the cloud. Today, this Internet core is challenged by partial reachability: political pressure threatens fragmentation by nationality, architectural changes such as carrier-grade NAT make connectivity conditional, and operational problems and commercial disputes make reachability incomplete for months. We assert that partial reachability is a fundamental part of the Internet core. While some systems paper over partial reachability, this paper is the first to provide a conceptual definition of the Internet core so we can reason about reachability from first principles. Following the Internet design, our definition is guided by reachability, not authority. Its corollaries are peninsulas: persistent regions of partial connectivity; and islands: when networks are partitioned from the Internet core. We show that the concept of peninsulas and islands can improve existing measurement systems. In one example, they show that RIPE’s DNSmon suffers misconfiguration and persistent network problems that are important, but risk obscuring operationally important connectivity changes because they are 5x to 9.7x larger. Our evaluation also informs policy questions, showing no single country or organization can unilaterally control the Internet core.
This technical report is joint work of Guillermo Baltra, Tarang Saluja, Yuri Pradkin, John Heidemann done at USC/ISI. This work was supported by the NSF via the EIEIO and InternetMap projects.
The AP reports “A statement from the country’s Telecommunication Regulatory Commission said they were unable to ensure service after their data center was attacked Thursday by demonstrators, who set fire to some equipment. The Associated Press was not able to independently verify this.” However, the near-complete outage observed by Trinocular (as seen in the figures above) seems inconsistent with problems at a single datacenter.
Update July 19, 22:28Z:ISOC Pulse has a post about this outage, and reports that “In a press event on 18 July, Bangladesh minister for posts, telecommunications, and information technology, Zunaid Ahmed Palak confirmed that the government had ordered the shutdown. “
To add about the root cause, the Deccan Heraldpublished an article from Reuters quoting Zunaid Ahmed Palak, junior information technology minister, as saying to reporters: “Mobile internet has been temporarily suspended due to various rumors and the unstable situation created…. on social media” on July 18. Today, Reuters quoted Palak as saying that “broadband internet would be restored by Tuesday night but [he] did not comment on mobile internet”. This statement is consistent with the country-wide outage we observed, and the prior statement suggests the outage was a request of the government.
Update July 24, 13:00Z (19:00 in Bangladesh): It looks like nearly all Bangladeshi networks are now back online.
Update July 25:The July 25 episode of The Briefing, an Australian news podcast, discussed the Bangladeshi outage and its impact, interviewing us about what we saw.
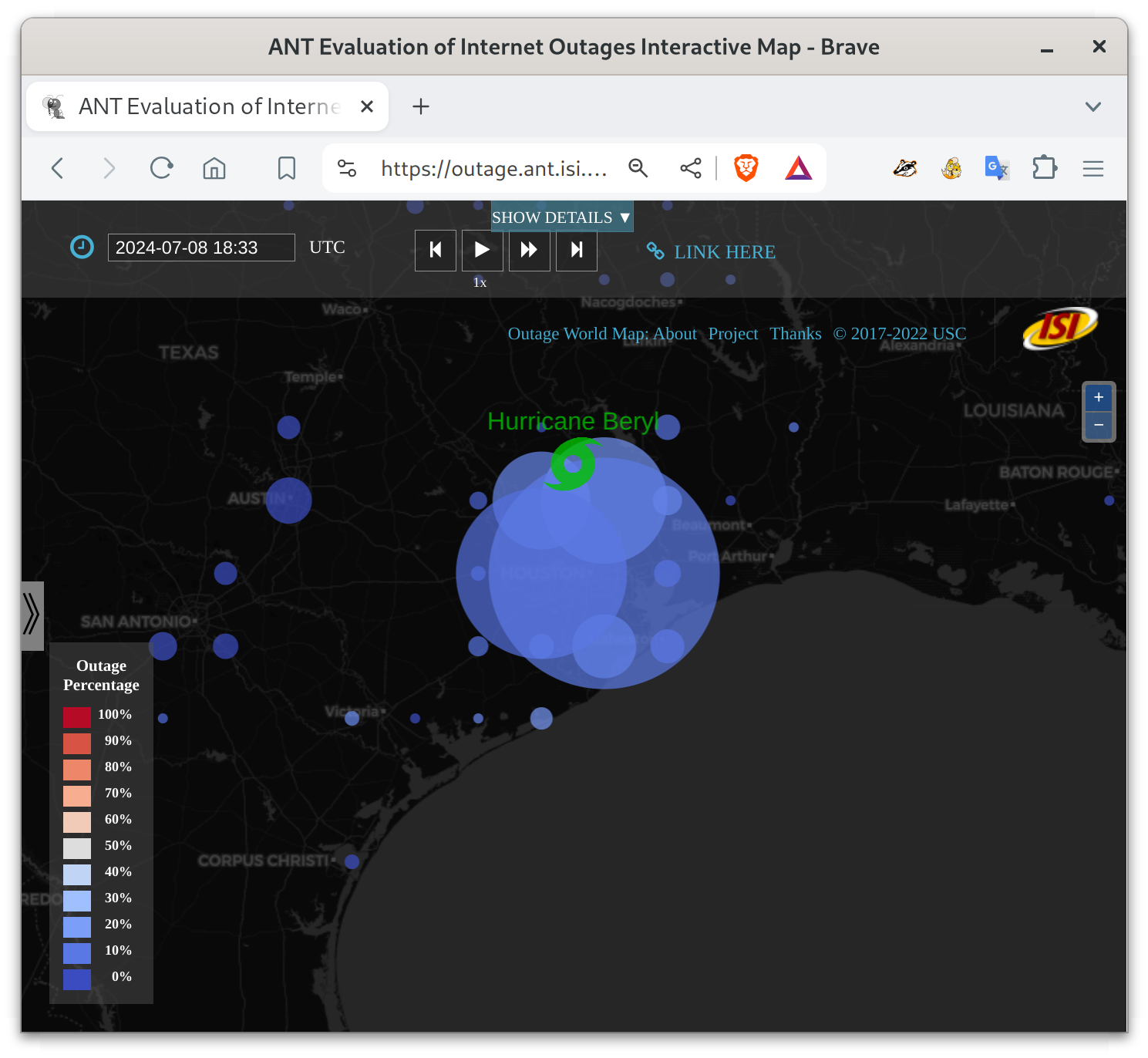
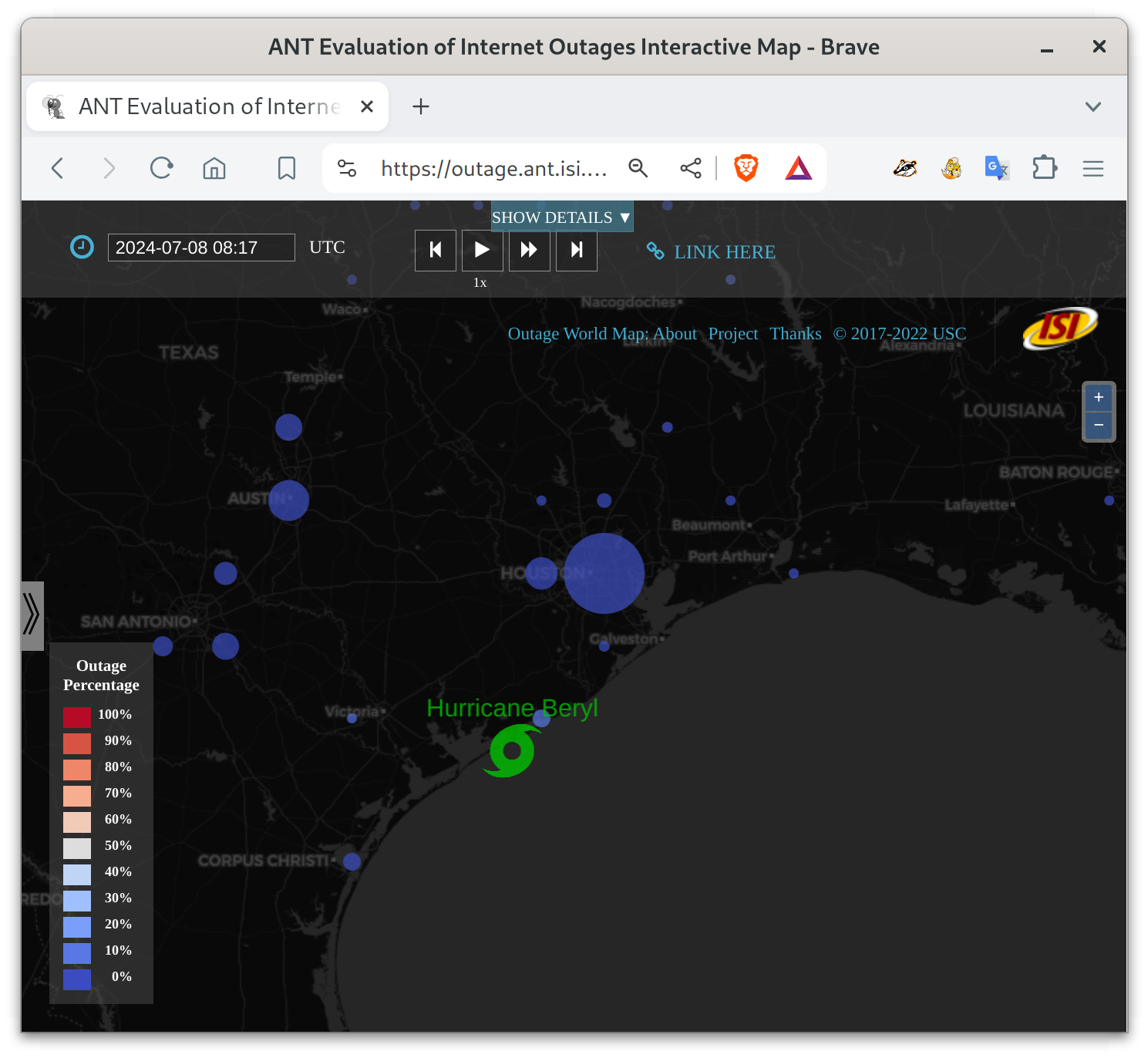
Hurricane Beryl made landfall in Texas around 2024-07-08 at 3:17am local time (CDT) (8:17 UTC). We see a fair number of Internet outages in the Huston area, presumably as people lost power due to flooding.
Compared to our view of Hurricane Harvey in 2017 in our blog and web, Beryl looks much less severe–we see fewer areas where most Internet acccess is out (as shown by red circles).
I would like to congratulate Dr. ASM Rizvi for defending his PhD at the University of Southern California in June 2024 and completing his doctoral dissertation “Mitigating Attacks that Disrupt Online Services Without Changing Existing Protocols”.
From the dissertation abstract:
Service disruption is undesirable in today’s Internet connectivity due to its impacts on enterprise profits, reputation, and user satisfaction. We describe service disruption as any targeted interruptions caused by malicious parties in the regular user-to-service interactions and functionalities that affect service performance and user experience. In this thesis, we propose new methods that tackle service disruptive attacks using measurement without changing existing Internet protocols. Although our methods do not guarantee defense against all the attack types, our example defense systems prove that our methods generally work to handle diverse attacks. To validate our thesis, we demonstrate defense systems against three disruptive attack types. First, we mitigate Distributed Denial-of-Service (DDoS) attacks that target an online service. Second, we handle brute-force password attacks that target the users of a service. Third, we detect malicious routing detours to secure the path from the users to the server. We provide the first public description of DDoS defenses based on anycast and filtering for the network operators. Then, we show the first moving target defense utilizing IPv6 to defeat password attacks. We also demonstrate how regular observation of latency helps cellular users, carriers, and national agencies to find malicious routing detours. As a supplemental outcome, we show the effectiveness of measurements in finding performance issues and ways to improve using existing protocols. These examples show that our idea applies to different network parts, even if we may not mitigate all the attack types.
Rizvi’s PhD work was supported by the U.S. Department of Homeland Security’s HSARPA Cyber Security Division (HSHQDC-17-R-B0004-TTA.02-0006-I, PAADDOS) in a joint project with the Netherlands Organisation for scientific research (4019020199), the U.S. National Science Foundation (grant NSF OAC-1739034, DDIDD; CNS-2319409, PIMAWAT; CRI-8115780, CLASSNET; CNS-1925737, DIINER ) and U.S. DARPA (HR001120C0157, SABRES), and Akamai.
Experiments showing educational ads for for-profit schools are disproportionately shown to Blacks at statistically significant levels. (from [Imana24a], figure 4).
Digital ads on social-media platforms play an important role in shaping access to economic opportunities. Our work proposes and implements a new third-party auditing method that can evaluate racial bias in the delivery of ads for education opportunities. Third-party auditing is important because it allows external parties to demonstrate presence or absence of bias in social-media algorithms. Education is a domain with legal protections against discrimination and concerns of racial-targeting, but bias induced by ad delivery algorithms has not been previously explored in this domain. Prior audits demonstrated discrimination in platforms’ delivery of ads to users for housing and employment ads. These audit findings supported legal action that prompted Meta to change their ad-delivery algorithms to reduce bias, but only in the domains of housing, employment, and credit. In this work, we propose a new methodology that allows us to measure racial discrimination in a platform’s ad delivery algorithms for education ads. We apply our method to Meta using ads for real schools and observe the results of delivery. We find evidence of racial discrimination in Meta’s algorithmic delivery of ads for education opportunities, posing legal and ethical concerns. Our results extend evidence of algorithmic discrimination to the education domain, showing that current bias mitigation mechanisms are narrow in scope, and suggesting a broader role for third-party auditing of social media in areas where ensuring non-discrimination is important.
This paper is a joint work of Basileal Imana and Aleksandra Korolova from Princeton University, and John Heidemann from USC/ISI. We thank the NSF for supporting this work (CNS-1956435, CNS- 1916153, CNS-2333448, CNS-1943584, CNS-2344925, CNS-2319409, and CNS-1925737).