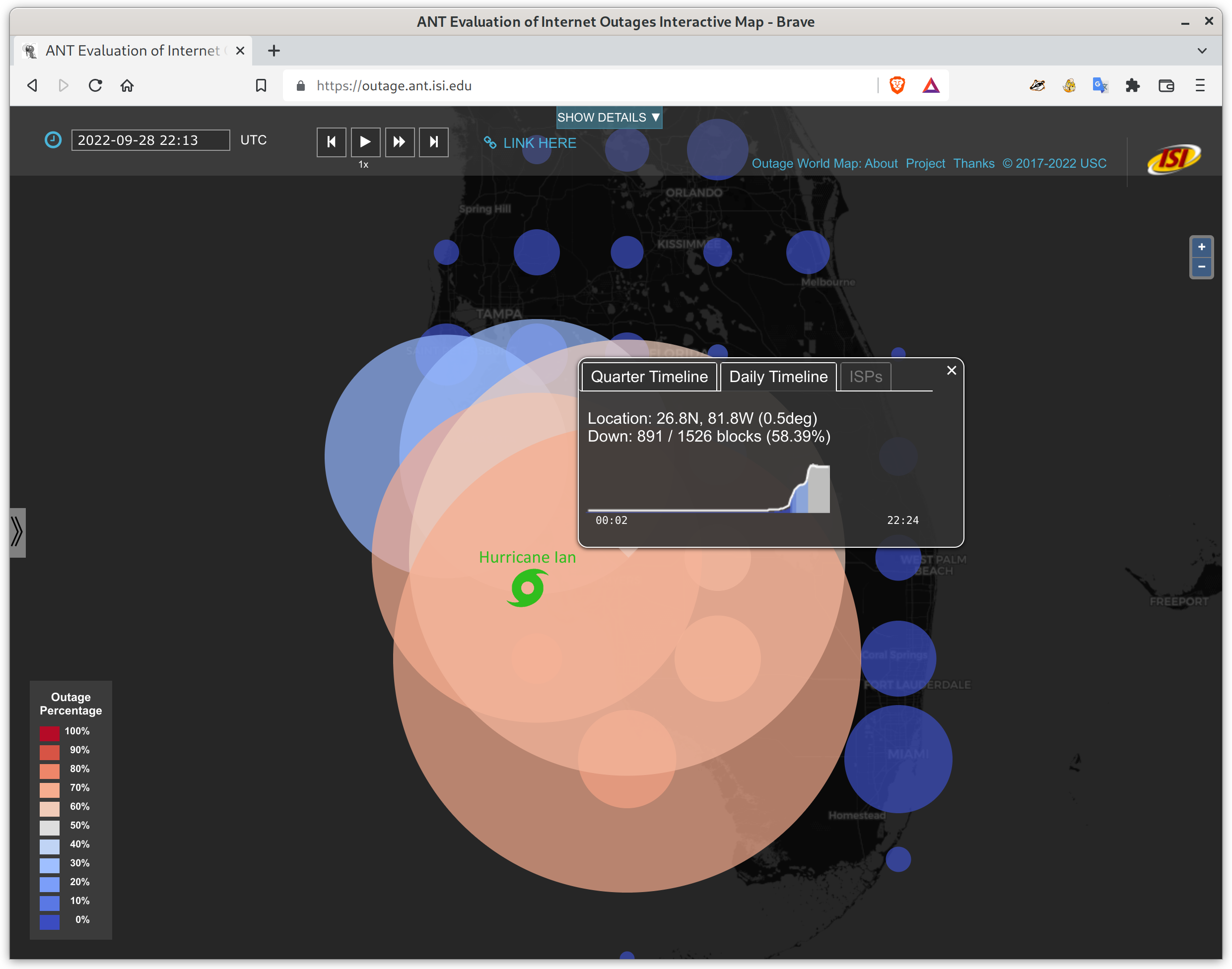
I would like to congratulate Dr. Basileal Imana for defending his PhD at the University of Southern California in August 2023 and completing his doctoral dissertation “Methods for Auditing Social Media Algorithms in the Public Interest”.

From the abstract:
Social-media platforms are entering a new era of increasing scrutiny by public interest groups and regulators. One reason for the increased scrutiny is platform-induced bias in how they deliver ads for life opportunities. Certain ad domains are legally protected against discrimination, and even when not, some domains have societal interest in equitable ad delivery. Platforms use relevance-estimator algorithms to optimize the delivery of ads. Such algorithms are proprietary and therefore opaque to outside evaluation, and early evidence suggests these algorithms may be biased or discriminatory. In response to such risks, the U.S. and the E.U. have proposed policies to allow researchers to audit platforms while protecting users’ privacy and platforms’ proprietary information. Currently, no technical solution exists for implementing such audits with rigorous privacy protections and without putting significant constraints on researchers. In this work, our thesis is that relevance-estimator algorithms bias the delivery of opportunity ads, but new auditing methods can detect that bias while preserving privacy.
We support our thesis statement through three studies. In the first study, we propose a black-box method for measuring gender bias in the delivery of job ads with a novel control for differences in job qualification, as well as other confounding factors that influence ad delivery. Controlling for qualification is necessary since qualification is a legally acceptable factor to target ads with, and we must separate it from bias introduced by platforms’ algorithms. We apply our method to Meta and LinkedIn, and demonstrate that Meta’s relevance estimators result in discriminatory delivery of job ads by gender. In our second study, we design a black-box methodology that is the first to propose a means to draw out potential racial bias in the delivery of education ads. Our method employs a pair of ads that are seemingly identical education opportunities but one is of inferior quality tied with a historical societal disparity that ad delivery algorithms may propagate. We apply our method to Meta and demonstrate their relevance estimators racially bias the delivery of education ads. In addition, we observe that the lack of access to demographic attributes is a growing challenge for auditing bias in ad delivery. Motivated by this challenge, we make progress towards enabling use of inferred race in black-box audits by analyzing how inference error can lead to incorrect measurement of skew in ad delivery. Going beyond the domain-specific and black-box methods we used in our first two studies, our final study proposes a novel platform-supported framework to allow researchers to audit relevance estimators that is generalizable to studying various categories of ads, demographic attributes and target platforms. The framework allows auditors to get privileged query-access to platforms’ relevance estimators to audit for bias in the algorithms while preserving the privacy interests of users and platforms. Overall, our first two studies show relevance-estimator algorithms bias the delivery of job and education ads, and thus motivate making these algorithms the target of platform-supported auditing in our third study. Our work demonstrates a platform-supported means to audit these algorithms is the key to increasing public oversight over ad platforms while rigorously protecting privacy.
Basi’s PhD work was co-advised by Aleksandra Korolova and John Heidemann, and supported by grants from the Rose Foundation and the NSF (CNS-1755992, CNS-1916153, CNS-1943584, CNS-1956435, and CNS-1925737.) Please see his individual publications for what data is available from his research.