I would like to congratulate Dr. Calvin Ardi for defending his PhD in April 2020 and completing his doctoral dissertation “Improving Network Security through Collaborative Sharing” in June 2020.
From the abstract:
As our world continues to become more interconnected through the
Internet, cybersecurity incidents are correspondingly increasing in
number, severity, and complexity. The consequences of these attacks
include data loss, financial damages, and are steadily moving from the
digital to the physical world, impacting everything from public
infrastructure to our own homes. The existing mechanisms in
responding to cybersecurity incidents have three problems: they
promote a security monoculture, are too centralized, and are too slow.
In this thesis, we show that improving one’s network security strongly
benefits from a combination of personalized, local detection, coupled
with the controlled exchange of previously-private network information
with collaborators. We address the problem of a security monoculture
with personalized detection, introducing diversity by tailoring to the
individual’s browsing behavior, for example. We approach the problem
of too much centralization by localizing detection, emphasizing
detection techniques that can be used on the client device or local
network without reliance on external services. We counter slow
mechanisms by coupling controlled sharing of information with
collaborators to reactive techniques, enabling a more efficient
response to security events.
We prove that we can improve network security by demonstrating our
thesis with four studies and their respective research contributions
in malicious activity detection and cybersecurity data sharing. In
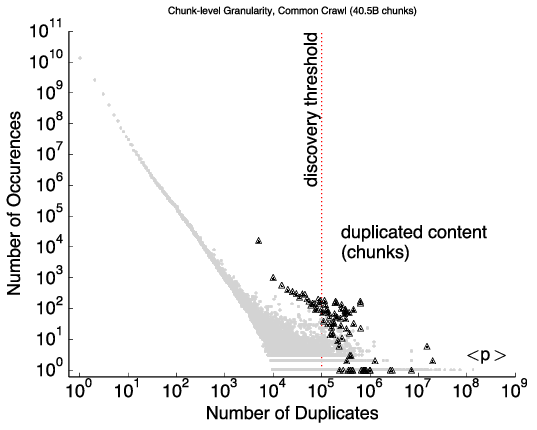
our first study, we develop Content Reuse Detection, an approach to
locally discover and detect duplication in large corpora and apply our
approach to improve network security by detecting “bad
neighborhoods” of suspicious activity on the web. Our second study
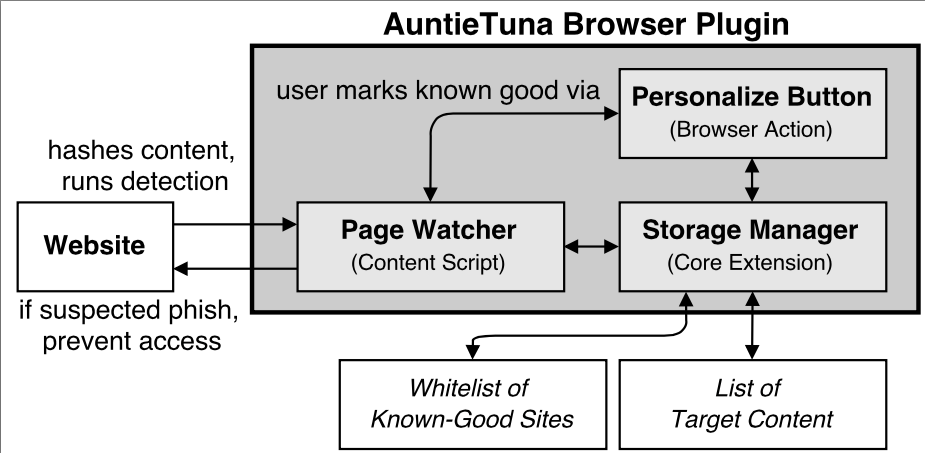
is AuntieTuna, an anti-phishing browser tool that implements personalized,
local detection of phish with user-personalization and improves
network security by reducing successful web phishing attacks. In our
third study, we develop Retro-Future, a framework for controlled information
exchange that enables organizations to control the risk-benefit
trade-off when sharing their previously-private data. Organizations
use Retro-Future to share data within and across collaborating organizations,
and improve their network security by using the shared data to
increase detection’s effectiveness in finding malicious activity.
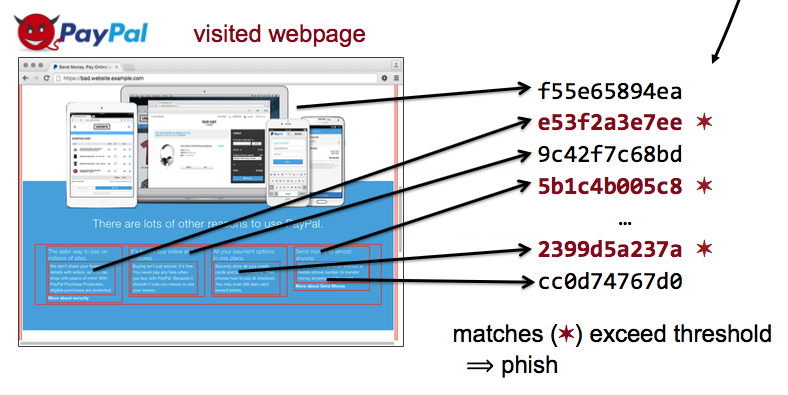
Finally, we present AuntieTuna2.0 in our fourth study, extending the proactive
detection of phishing sites in AuntieTuna with data sharing between friends.
Users exchange previously-private information with collaborators to
collectively build a defense, improving their network security and
group’s collective immunity against phishing attacks.
Calvin defended his PhD when USC was on work-from-home due to COVID-19; he is the second ANT student with a fully on-line PhD defense.