Yuri Pradkin, Christopher Morales Ramos, and John Heidemann, with Christopher’s summer undergraduate research project poster.
Christopher’s project was improving the accuracy in estimating Round Trip Time (RTT) measurements from icmptrain our high-speed IPv4 prober, while minimizing the amount of traffic that was sent. In addition to improving RTT estimates, his work can lead to better geolocation estimates.
His research at ISI was jointly advised by Yuri Pradkin and John Heidemann, as part of the ISI REU program directed by Jelena Mirkovic.
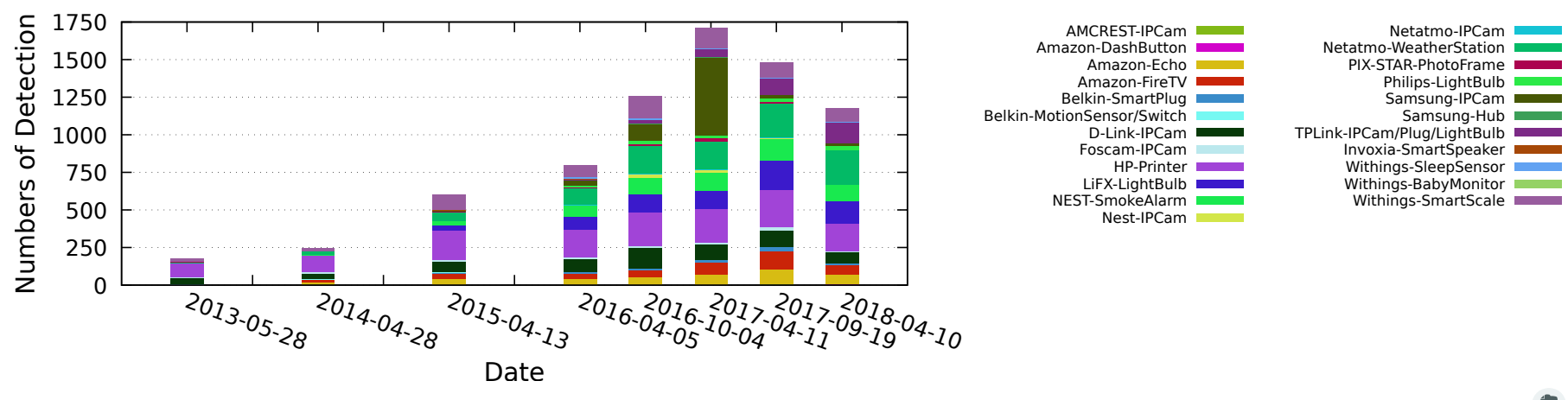
ISP-Level Deployment for 26 IoT Device Types. From Figure 2 of [Guo18c].From the abstract of our technical report:
Distributed Denial-of-Service (DDoS) attacks launched from compromised Internet-of-Things (IoT) devices have shown how vulnerable the Internet is to large-scale DDoS attacks. To understand the risks of these attacks requires learning about these IoT devices: where are they? how many are there? how are they changing? This paper describes three new methods to find IoT devices on the Internet: server IP addresses in traffic, server names in DNS queries, and manufacturer information in TLS certificates. Our primary methods (IP addresses and DNS names) use knowledge of servers run by the manufacturers of these devices. We have developed these approaches with 10 device models from 7 vendors. Our third method uses TLS certificates obtained by active scanning. We have applied our algorithms to a number of observations. Our IP-based algorithms see at least 35 IoT devices on a college campus, and 122 IoT devices in customers of a regional IXP. We apply our DNSbased algorithm to traffic from 5 root DNS servers from 2013 to 2018, finding huge growth (about 7×) in ISPlevel deployment of 26 device types. DNS also shows similar growth in IoT deployment in residential households from 2013 to 2017. Our certificate-based algorithm finds 254k IP cameras and network video recorders from 199 countries around the world.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This technical report is joint work of Hang Guo and John Heidemann from USC/ISI.
cryptopANT is a C library for IP address anonymization using crypto-PAn algorithm, originally defined by Georgia Tech. The library supports anonymization and de-anonymization (provided you possess a secret key) of IPv4, IPv6, and MAC addresses. The software release includes sample utilities that anonymize IP addresses in text, but we expect most use of the library will be as part of other programs. The Crypto-PAn anonymization scheme was developed by Xu, Fan, Ammar, and Moon at Georgia Tech and described in“Prefix-Preserving IP Address Anonymization”, Computer Networks, Volume 46, Issue 2, 7 October 2004, Pages 253-272, Elsevier. Our library is independent (and not binary compatible) of theirs.
Despite this being the first release as a library, the code has been in use for more than 10 years in other tools. It had been part of our other software packages, such as dag_scrubber for years. By popular request, we’re finally releasing it as a separate package.
The library is packaged with an example binary (scramble_ips) that can be used to anonymize text ips.
See also the crypto-PAn page at Georgia Tech here.
IoT devices we detect in use at a campus (Table 3 from [Guo18b])From the abstract of our paper:
Recent IoT-based DDoS attacks have exposed how vulnerable the Internet can be to millions of insufficiently secured IoT devices. To understand the risks of these attacks requires
learning about these IoT devices—where are they, how many are there, how are they changing? In this paper, we propose
a new method to find IoT devices in Internet to begin to assess this threat. Our approach requires observations of flow-level network traffic and knowledge of servers run by
the manufacturers of the IoT devices. We have developed our approach with 10 device models by 7 vendors and controlled
experiments. We apply our algorithm to observations from 6 days of Internet traffic at a college campus and partial traffic
from an IXP to detect IoT devices.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This paper is joint work of Hang Guo and John Heidemann from USC/ISI.
Moura18a Figure 6a, Answers received during a DDoS attack causing 100% packet loss with pre-loaded caches.
From the abstract:
The Internet’s Domain Name System (DNS) is a frequent target of Distributed Denial-of-Service (DDoS) attacks, but such attacks have had very different outcomes—some attacks have disabled major public websites, while the external effects of other attacks have been minimal. While on one hand the DNS protocol is a relatively simple, the system has many moving parts, with multiple levels of caching and retries and replicated servers. This paper uses controlled experiments to examine how these mechanisms affect DNS resilience and latency, exploring both the client side’s DNS user experience, and server-side traffic. We find that, for about about 30% of clients, caching is not effective. However, when caches are full they allow about half of clients to ride out server outages, and caching and retries allow up to half of the clients to tolerate DDoS attacks that result in 90% query loss, and almost all clients to tolerate attacks resulting in 50% packet loss. The cost of such attacks to clients are greater median latency. For servers, retries during DDoS attacks increase normal traffic up to 8x. Our findings about caching and retries can explain why some real-world DDoS cause service outages for users while other large attacks have minimal visible effects.
John Heidemann gave the talk “Internet Outages: Reliablity and Security” at the University of Oregon Cybersecurity Day in Eugene, Oregon on April 23, 2018. Slides are available at https://www.isi.edu/~johnh/PAPERS/Heidemann18e.pdf.
Network outages as a security problem.
From the abstract:
The Internet is central to our lives, but we know astoundingly little about it. Even though many businesses and individuals depend on it, how reliable is the Internet? Do policies and practices make it better in some places than others?
Since 2006, we have been studying the public face of the Internet to answer these questions. We take regular censuses, probing the entire IPv4 Internet address space. For more than two years we have been observing Internet reliability through active probing with Trinocular outage detection, revealing the effects of the Internet due to natural disasters like Hurricanes from Sandy to Harvey and Maria, configuration errors that sometimes affect millions of customers, and political events where governments have intervened in Internet operation. This talk will describe how it is possible to observe Internet outages today and what they are beginning to say about the Internet and about the physical world.
This talk builds on research over the last decade in IPv4 censuses and outage detection and includes the work of many of my collaborators.
Data from this talk is all available; see links on the last slide.
This visualization was initially seeded by a Michael Keston research grant here at ISI, and the outage measurement techniques and ongoing data collection has been developed with the support of DHS (the LANDER-2007, LACREND, LACANIC, and Retro-future Bridge and Outages projects).
We have published a new conference “Detecting ICMP Rate Limiting in the Internet” in PAM 2018 (the Passive and Active Measurement Conference) in Berlin, Germany.
Figure 4 from [Guo18a] Confirming a block is rate limited with additional probingFigure 4 from [Guo18a] confirming a bock is rate limited, comparing experimental results with models of rate-limited and non-rate-limited behavior.From the abstract of our conference paper:
Comparing model and experimental effects of rate limiting (Figure 4 from [Guo18a] )
ICMP active probing is the center of many network measurements. Rate limiting to ICMP traffic, if undetected, could distort measurements and create false conclusions. To settle this concern, we look systematically for ICMP rate limiting in the Internet. We create FADER, a new algorithm that can identify rate limiting from user-side traces with minimal new measurement traffic. We validate the accuracy of FADER with many different network configurations in testbed experiments and show that it almost always detects rate limiting. With this confidence, we apply our algorithm to a random sample of the whole Internet, showing that rate limiting exists but that for slow probing rates, rate-limiting is very rare. For our random sample of 40,493 /24 blocks (about 2% of the responsive space), we confirm 6 blocks (0.02%!) see rate limiting at 0.39 packets/s per block. We look at higher rates in public datasets and suggest that fall-off in responses as rates approach 1 packet/s per /24 block is consistent with rate limiting. We also show that even very slow probing (0.0001 packet/s) can encounter rate limiting of NACKs that are concentrated at a single router near the prober.
Datasets we used in this paper are all public. ISI Internet Census and Survey data (including it71w, it70w, it56j, it57j and it58j census and survey) are available at https://ant.isi.edu/datasets/index.html. ZMap 50-second experiments data are from their WOOT 14 paper and can be obtained from ZMap authors upon request.
This conference report is joint work of Hang Guo and John Heidemann from USC/ISI.
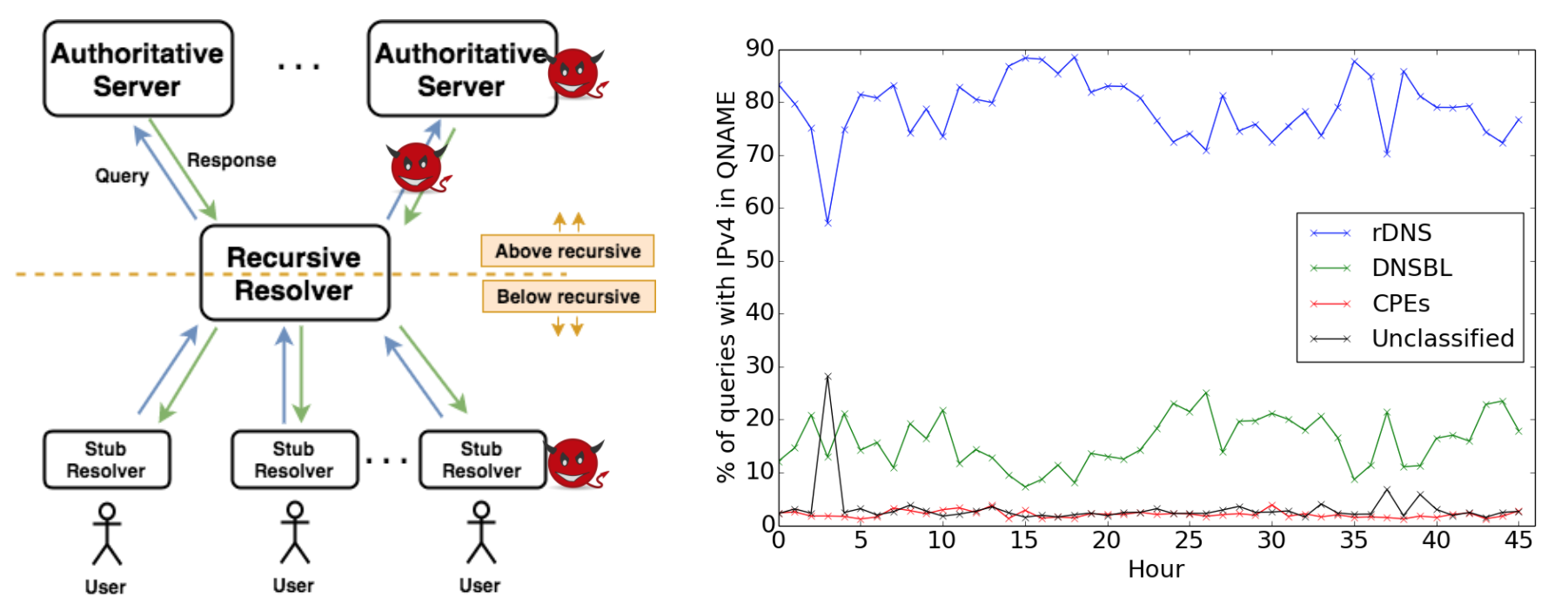
Threat model for enumerating leaks above the recursive (left). Percentage of four categories of queries containing IPv4 addresses in their QNAMEs. (right)
As with any information system consisting of data derived from people’s actions, DNS data is vulnerable to privacy risks. In DNS, users make queries through recursive resolvers to authoritative servers. Data collected below (or in) the recursive resolver directly exposes users, so most prior DNS data sharing focuses on queries above the recursive resolver. Data collected above a recursive resolver has largely been seen as posing a minimal privacy risk since recursive resolvers typically aggregate traffic for many users, thereby hiding their identity and mixing their traffic. Although this assumption is widely made, to our knowledge it has not been verified. In this paper we re-examine this assumption for DNS traffic above the recursive resolver. First, we show that two kinds of information appear in query names above the recursive resolver: IP addresses and sensitive domain names, such as those pertaining to health, politics, or personal or lifestyle information. Second, we examine how often these classes of potentially sensitive names appear in Root DNS traffic, using 48 hours of B-Root data from April 2017.
This is a joint work by Basileal Imana (USC), Aleksandra Korolova (USC) and John Heidemann (USC/ISI).
The DITL dataset (ITL_B_Root-20170411) used in this work is available from DHS IMPACT, the ANT project, and through DNS-OARC.
We released a new technical report “Back Out: End-to-end Inference of Common Points-of-Failure in the Internet (extended)”, ISI-TR-724, available at https://www.isi.edu/~johnh/PAPERS/Heidemann18b.pdf.
From the abstract:
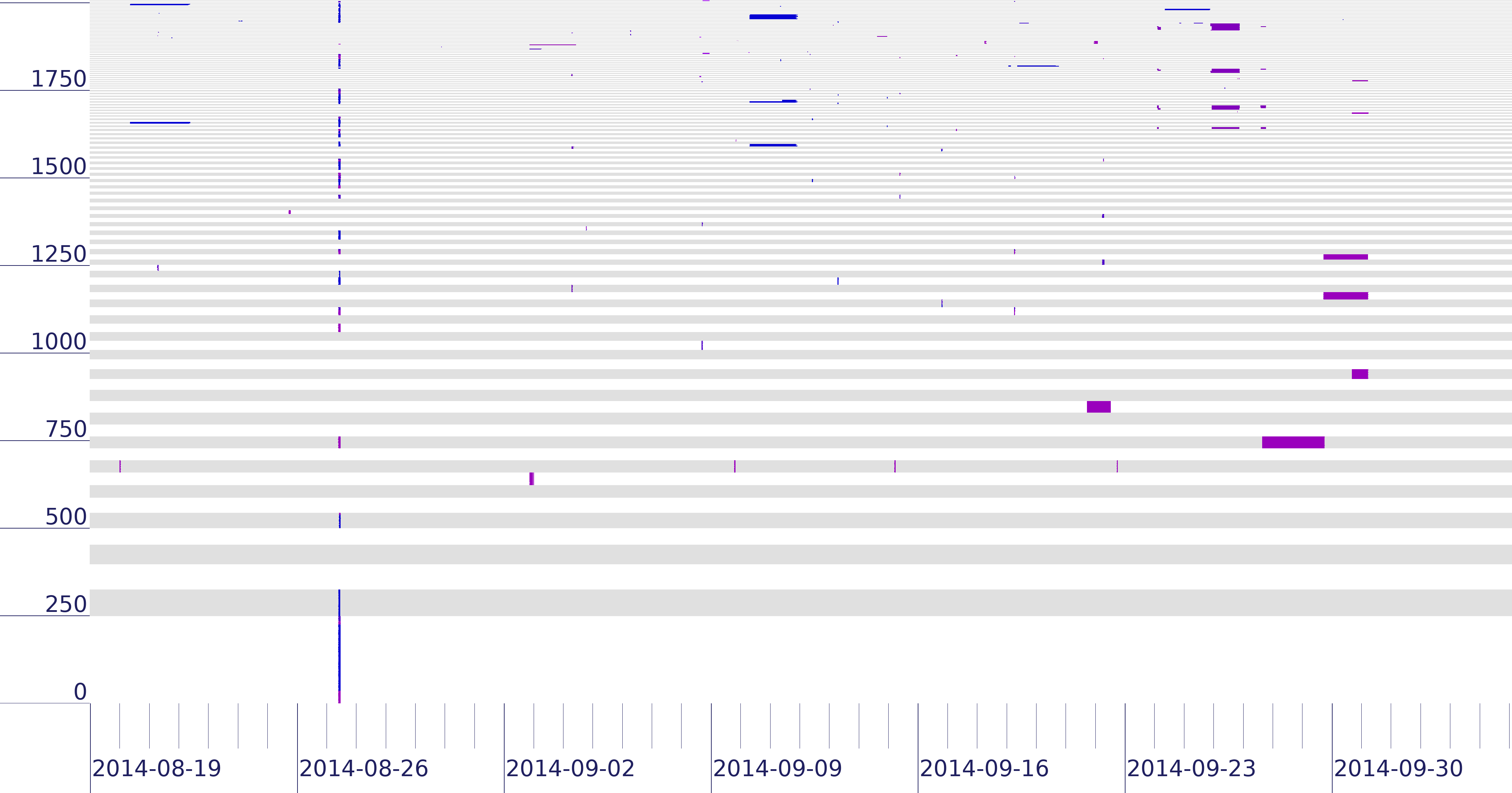
Clustering (from our event clustering algorithm) of 2014q3 outages from 172/8, showing 7 weeks including the 2014-08-27 Time Warner outage.
Internet reliability has many potential weaknesses: fiber rights-of-way at the physical layer, exchange-point congestion from DDOS at the network layer, settlement disputes between organizations at the financial layer, and government intervention the political layer. This paper shows that we can discover common points-of-failure at any of these layers by observing correlated failures. We use end-to-end observations from data-plane-level connectivity of edge hosts in the Internet. We identify correlations in connectivity: networks that usually fail and recover at the same time suggest common point-of-failure. We define two new algorithms to meet these goals. First, we define a computationally-efficient algorithm to create a linear ordering of blocks to make correlated failures apparent to a human analyst. Second, we develop an event-based clustering algorithm that directly networks with correlated failures, suggesting common points-of-failure. Our algorithms scale to real-world datasets of millions of networks and observations: linear ordering is O(n log n) time and event-based clustering parallelizes with Map/Reduce. We demonstrate them on three months of outages for 4 million /24 network prefixes, showing high recall (0.83 to 0.98) and precision (0.72 to 1.0) for blocks that respond. We also show that our algorithms generalize to identify correlations in anycast catchments and routing.
Datasets from this paper are available at no cost and are listed at https://ant.isi.edu/datasets/outage/, and we expect to release the software for this paper in the coming months (contact us if you are interested).