PCMag released a news story on January 3, 2018 about our measuring Internet outages, including discussion about the 2017 hurricanes like Irma, and our new worldwide outage browser.
We are happy to announce a new website at https://ant.isi.edu/outage/world/ that supports our Internet outage data collected from Trinocular. (Update 2025: the website is now https://outage.ant.isi.edu/ )
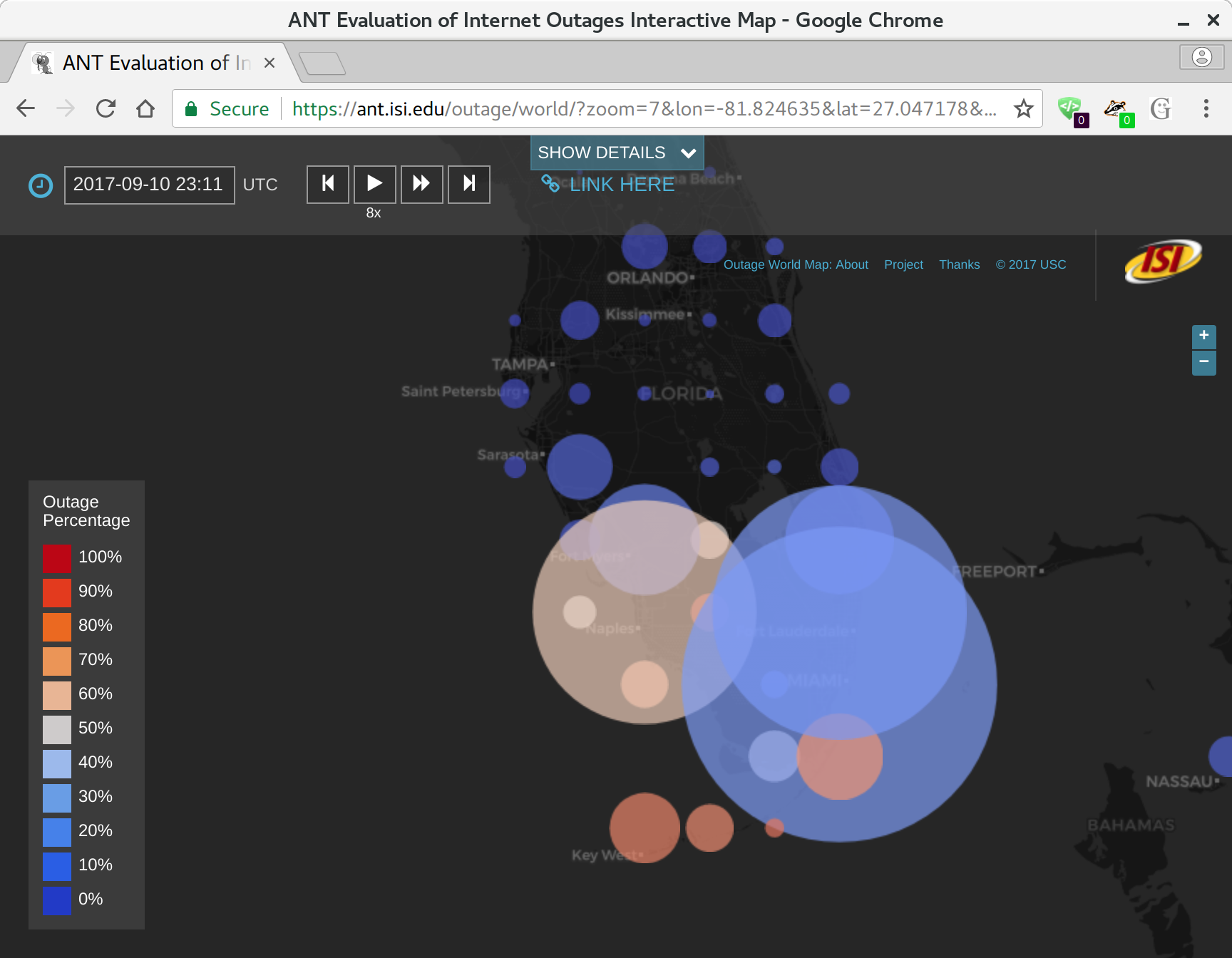
Our website supports browsing more than two years of outage data, organized by geography and time. The map is a google-maps-style world map, with circle on it at even intervals (every 0.5 to 2 degrees of latitude and longitude, depending on the zoom level). Circle sizes show how many /24 network blocks are out in that location, while circle colors show the percentage of outages, from blue (only a few percent) to red (approaching 100%).
We hope that this website makes our outage data more accessible to researchers and the public.
The raw data underlying this website is available on request, see our outage dataset webpage.
The research is funded by the Department of Homeland Security (DHS) Cyber Security Division (through the LACREND and Retro-Future Bridge and Outages projects) and Michael Keston, a real estate entrepreneur and philanthropist (through the Michael Keston Endowment). Michael Keston helped support this the initial version of this website, and DHS has supported our outage data collection and algorithm development.
The website was developed by Dominik Staros, ISI web developer and owner of Imagine Web Consulting, based on data collected by ISI researcher Yuri Pradkin. It builds on prior work by Pradkin, Heidemann and USC’s Lin Quan in ISI’s Analysis of Network Traffic Lab.
ISI has featured our new website on the ISI news page.
Categories
new project LACANIC
We are happy to announce a new project, LACANIC, the Los Angeles/Colorado Application and Network Information Community.
The LACANIC project’s goal is to develop datasets to improve Internet security and readability. We distribute these datasets through the DHS IMPACT program.
As part of this work we:
- provide regular data collection to collect long-term, longitudinal data
- curate datasets for special events
- build websites and portals to help make data accessible to casual users
- develop new measurement approaches
We provide several types of datasets:
- anonymized packet headers and network flow data, often to document events like distributed denial-of-service (DDoS) attacks and regular traffic
- Internet censuses and surveys for IPv4 to document address usage
- Internet hitlists and histories, derived from IPv4 censuses, to support other topology studies
- application data, like DNS and Internet-of-Things mapping, to document regular traffic and DDoS events
- and we are developing other datasets
LACANIC allows us to continue some of the data collection we were doing as part of the LACREND project, as well as develop new methods and ways of sharing the data.
LACANIC is a joint effort of the ANT Lab involving USC/ISI (PI: John Heidemann) and Colorado State University (PI: Christos Papadopoulos).
We thank DHS’s Cyber Security Division for their continued support!
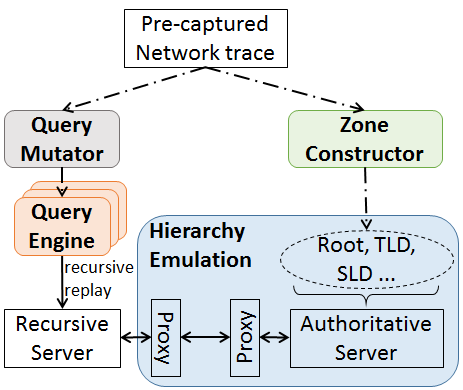
We released a new technical report “LDplayer: DNS Experimentation at Scale”, ISI-TR-722, available at https://www.isi.edu/publications/trpublic/pdfs/ISI-TR-722.pdf.
 From the abstract:
From the abstract:
DNS has evolved over the last 20 years, improving in security and privacy and broadening the kinds of applications it supports. However, this evolution has been slowed by the large installed base with a wide range of implementations that are slow to change. Changes need to be carefully planned, and their impact is difficult to model due to DNS optimizations, caching, and distributed operation. We suggest that experimentation at scale is needed to evaluate changes and speed DNS evolution. This paper presents LDplayer, a configurable, general-purpose DNS testbed that enables DNS experiments to scale in several dimensions: many zones, multiple levels of DNS hierarchy, high query rates, and diverse query sources. LDplayer provides high fidelity experiments while meeting these requirements through its distributed DNS query replay system, methods to rebuild the relevant DNS hierarchy from traces, and efficient emulation of this hierarchy of limited hardware. We show that a single DNS server can correctly emulate multiple independent levels of the DNS hierarchy while providing correct responses as if they were independent. We validate that our system can replay a DNS root traffic with tiny error (+/- 8ms quartiles in query timing and +/- 0.1% difference in query rate). We show that our system can replay queries at 87k queries/s, more than twice of a normal DNS Root traffic rate, maxing out one CPU core used by our customized DNS traffic generator. LDplayer’s trace replay has the unique ability to evaluate important design questions with confidence that we capture the interplay of caching, timeouts, and resource constraints. As an example, we can demonstrate the memory requirements of a DNS root server with all traffic running over TCP, and we identified performance discontinuities in latency as a function of client RTT.
Software developed in this paper is available at https://ant.isi.edu/software/ldplayer/.
The paper “A Look at Router Geolocation in Public and Commercial Databases” has appeared in the 2017 Internet Measurement Conference (IMC) on November 1-3, 2017 in London, United Kingdom.
From the abstract:
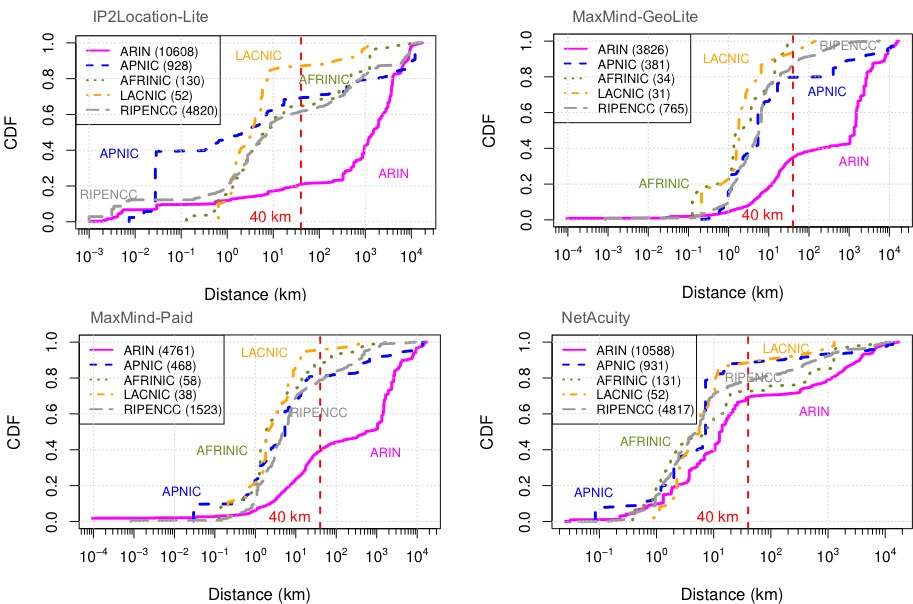
Internet measurement research frequently needs to map infrastructure components, such as routers, to their physical locations. Although public and commercial geolocation services are often used for this purpose, their accuracy when applied to network infrastructure has not been sufficiently assessed. Prior work focused on evaluating the overall accuracy of geolocation databases, which is dominated by their performance on end-user IP addresses. In this work, we evaluate the reliability of router geolocation in databases. We use a dataset of about 1.64M router interface IP addresses extracted from the CAIDA Ark dataset to examine the country- and city-level coverage and consistency of popular public and commercial geolocation databases. We also create and provide a ground-truth dataset of 16,586 router interface IP addresses and their city-level locations, and use it to evaluate the databases’ accuracy with a regional breakdown analysis. Our results show that the databases are not reliable for geolocating routers and that there is room to improve their country- and city-level accuracy. Based on our results, we present a set of recommendations to researchers concerning the use of geolocation databases to geolocate routers.
The work in this paper was joint work by Manaf Gharaibeh, Anant Shah, Han Zhang, Christos Papadopoulos (Colorado State University), Brad Huffaker (CAIDA / UC San Diego), and Roya Ensafi (University of Michigan). The findings of this work are highlighted in an APNIC blog post “Should we trust the geolocation databases to geolocate routers?”. The ground truth datasets used in the paper are available via IMPACT.
Categories
new talk “LocalRoot: Serve Yourself”
Wes Hardaker gave a talk on his LocalRoot project, allowing recursive resolver operators to keep an up to date cached copy of the root zone data available at all times. The talk was held in Abu Dhabi on November 1, 2017 at the ICANN annual general meeting during the DNSSEC Workshop. Slides and recorded video are available at on the ICANN event page.
Wes Hardaker gave the talk “Verfploeter: Broad and Load-Aware Anycast Mapping” at DNS-OARC in San Jose, California, USA on September 29, 2017. Slides are available at on the event page.
From the abstract:
IP anycast provides DNS operators and CDNs with automatic fail-over and reduced latency by breaking the Internet into catchments,each served by a different anycast site. Unfortunately, understanding and predicting changes to catchments as sites are added or removed has been challenging. Current tools such as RIPE Atlas or commercial equivalents map from thousands of vantage points (VPs),but their coverage can be inconsistent around the globe. This paper proposes Verfploeter, a new method that maps anycast catchments using active probing. Verfploeter provides around 3.8M virtual VPs, 430 times the 9k physical VPs in RIPE Atlas,providing coverage of the vast majority of networks around the globe. We then add load information from prior service logs to provide calibrated predictions of anycast changes. Verfploeter has been used to evaluate the new anycast for B-Root, and we also report its use of a nine-site anycast testbed. We show that the greater coverage made possible by Verfploeter’s active probing is necessary to see routing differences in regions that have sparse coverage from RIPE Atlas, like South America and China.
A video of the talk is available On YouTube.
The paper “Detecting Malicious Activity With DNS Backscatter Over Time ” appears in EEE/ACM Transactions on Networking ( Volume: 25, Issue: 5, Oct. 2017 ).
From the abstract:
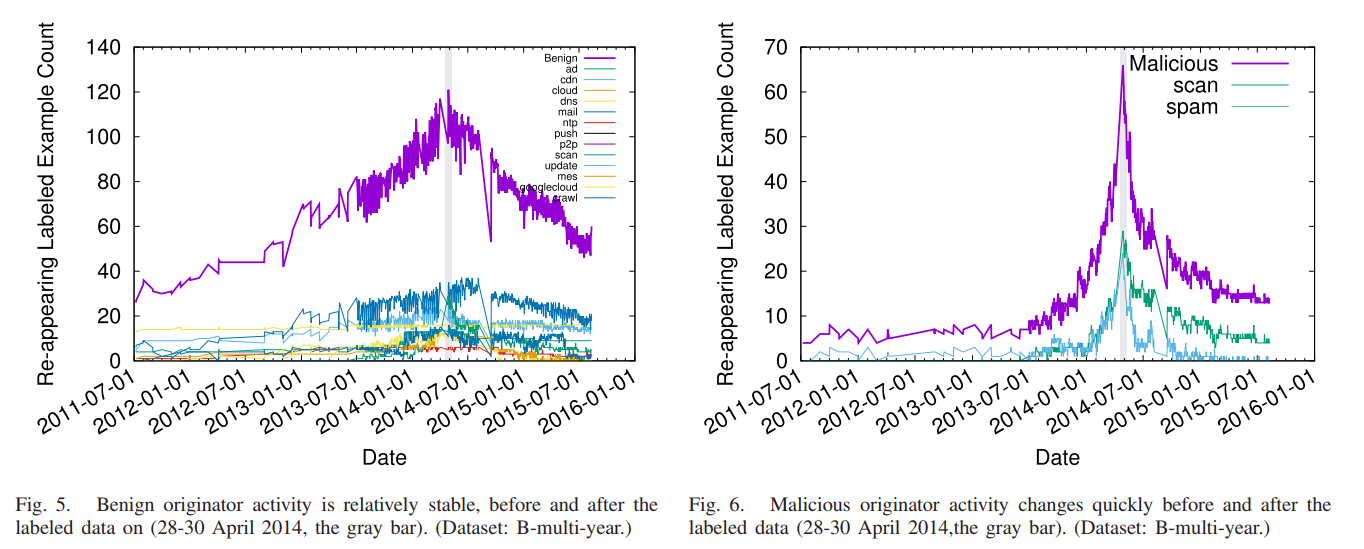
Network-wide activity is when one computer (the originator) touches many others (the targets). Motives for activity may be benign (mailing lists, CDNs, and research scanning), malicious (spammers and scanners for security vulnerabilities), or perhaps indeterminate (ad trackers). Knowledge of malicious activity may help anticipate attacks, and understanding benign activity may set a baseline or characterize growth. This paper identifies DNS backscatter as a new source of information about network-wide activity. Backscatter is the reverse DNS queries caused when targets or middleboxes automatically look up the domain name of the originator. Queries are visible to the authoritative DNS servers that handle reverse DNS. While the fraction of backscatter they see depends on the server’s location in the DNS hierarchy, we show that activity that touches many targets appear even in sampled observations. We use information about the queriers to classify originator activity using machine learning. Our algorithm has reasonable accuracy and precision (70–80%) as shown by data from three different organizations operating DNS servers at the root or country-level. Using this technique we examine nine months of activity from one authority to identify trends in scanning, identifying bursts corresponding to Heartbleed and broad and continuous scanning of ssh.
This paper furthers our understanding of evolution of malicious network activities from an earlier work that:
(1) Why our machine-learning based classifier (that relies on manually collected labeled data) does not port across physical sites and over time.
(2) Secondly paper recommends how to sustain good learning score over time and provides expected life-time of labeled data.
An excerpt from section III-E (Training Over Time):
Classification (§ III-D) is based on training, yet training accuracy is affected by the evolution of activity—specific examples come and go, and the behavior in each class evolves. Change happens for all classes, but the problem is particularly acute for malicious classes (such as spam) where the adversarial nature of the action forces rapid evolution (see § V).
Some datasets used in this paper can be found here:
The paper “Recursives in the Wild: Engineering Authoritative DNS Servers” will appear in the 2017 Internet Measurement Conference (IMC) on November 1-3, 2017 in London, United Kingdom.
![]()
In In Internet Domain Name System (DNS), services operate authoritative name servers that individuals query through recursive resolvers. Operators strive to provide reliability by operating multiple name servers (NS), each on a separate IP address, and by using IP anycast to allow NSes to provide service from many physical locations. To meet their goals of minimizing latency and balancing load across NSes and anycast, operators need to know how recursive resolvers select an NS, and how that interacts with their NS deployments. Prior work has shown some recursives search for low latency, while others pick an NS at random or round robin, but did not examine how prevalent each choice was. This paper provides the first analysis of how recursives select between name servers in the wild, and from that we provide guidance to operators how to engineer their name servers to reach their goals. We conclude that all NSes need to be equally strong and therefore we recommend to deploy IP anycast at every single authoritative.
All datasets used in this paper (but one) are available at https://ant.isi.edu/datasets/dns/index.html#recursives .
The paper “Broad and Load-aware Anycast Mapping with Verfploeter” will appear in the 2017 Internet Measurement Conference (IMC) on November 1-3, 2017 in London, United Kingdom.
From the abstract:
IP anycast provides DNS operators and CDNs with automatic failover and reduced latency by breaking the Internet into catchments, each served by a different anycast site. Unfortunately, understanding and predicting changes to catchments as anycast sites are added or removed has been challenging. Current tools such as RIPE Atlas or commercial equivalents map from thousands of vantage points (VPs), but their coverage can be inconsistent around the globe. This paper proposes Verfploeter, a new method that maps anycast catchments using active probing. Verfploeter provides around 3.8M passive VPs, 430x the 9k physical VPs in RIPE Atlas, providing coverage of the vast majority of networks around the globe. We then add load information from prior service logs to provide calibrated predictions of anycast changes. Verfploeter has been used to evaluate the new anycast deployment for B-Root, and we also report its use of a nine-site anycast testbed. We show that the greater coverage made possible by Verfploeter’s active probing is necessary to see routing differences in regions that have sparse coverage from RIPE Atlas, like South America and China.
The work in this paper was joint work by Wouter B. de Vries, Ricardo de O. Schmidt (Univ. of Twente), Wes Hardaker, John Heidemann (USC/ISI), Pieter-Tjerk de Boer and Aiko Pras (Univ. of Twente). The datasets used in the paper are available at https://ant.isi.edu/datasets/anycast/index.html#verfploeter.