The paper “Measuring the Latency and Pervasiveness of TLS Certificate Revocation” will appear at Passive and Active Measurements Conference in March 2016 in Heraklion, Crete, Greece (previously available at http://www.isi.edu/~liangzhu/papers/Zhu16a.pdf)
From the abstract: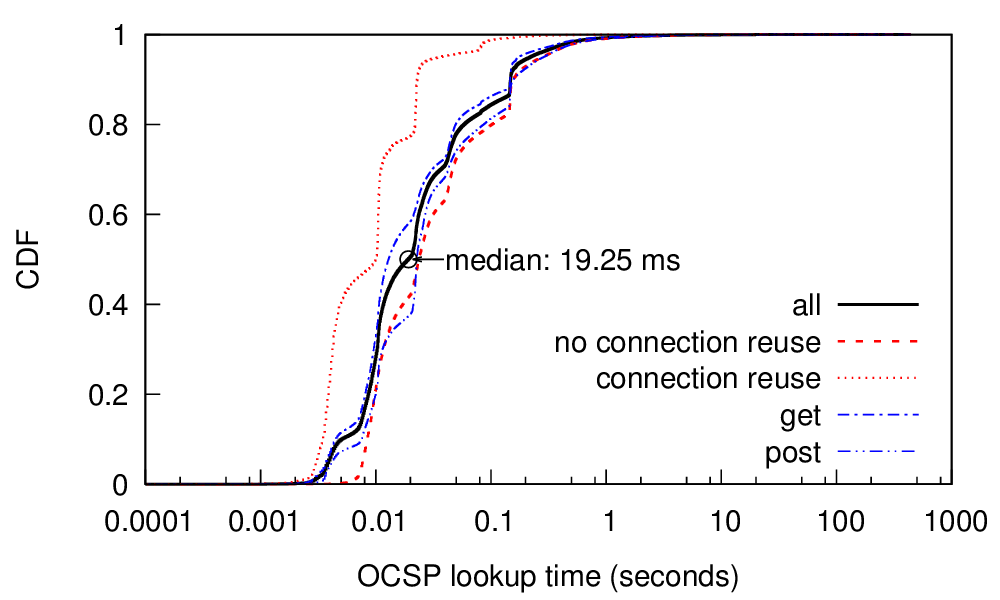
Today, Transport-Layer Security (TLS) is the bedrock of Internet security for the web and web-derived applications. TLS depends on the X.509 Public Key Infrastructure (PKI) to authenticate endpoint
identity. An essential part of a PKI is the ability to quickly revoke certificates, for example, after a key compromise. Today the Online Certificate Status Protocol (OCSP) is the most common way to quickly distribute revocation information. However, prior and current concerns about OCSP latency and privacy raise questions about its use. We examine OCSP using passive network monitoring of live traffic at the Internet uplink of a large research university and verify the results using active scans. Our measurements show that the median latency of OCSP queries is quite good: only 20 ms today, much less than the 291 ms observed in 2012. This improvement is because content delivery networks (CDNs) serve most OCSP traffic today; our measurements show 94% of queries are served by CDNs. We also show that OCSP use is ubiquitous today: it is used by all popular web browsers, as well as important non-web applications such as MS-Windows code signing.
The work in the paper is by Liang Zhu (USC/ISI), Johanna Amann (ICSI) and John Heidemann (USC/ISI). The active probe dataset in this paper is available upon request.

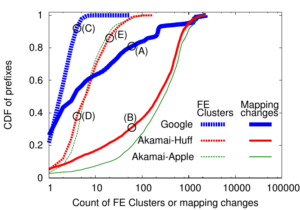 Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.
Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.