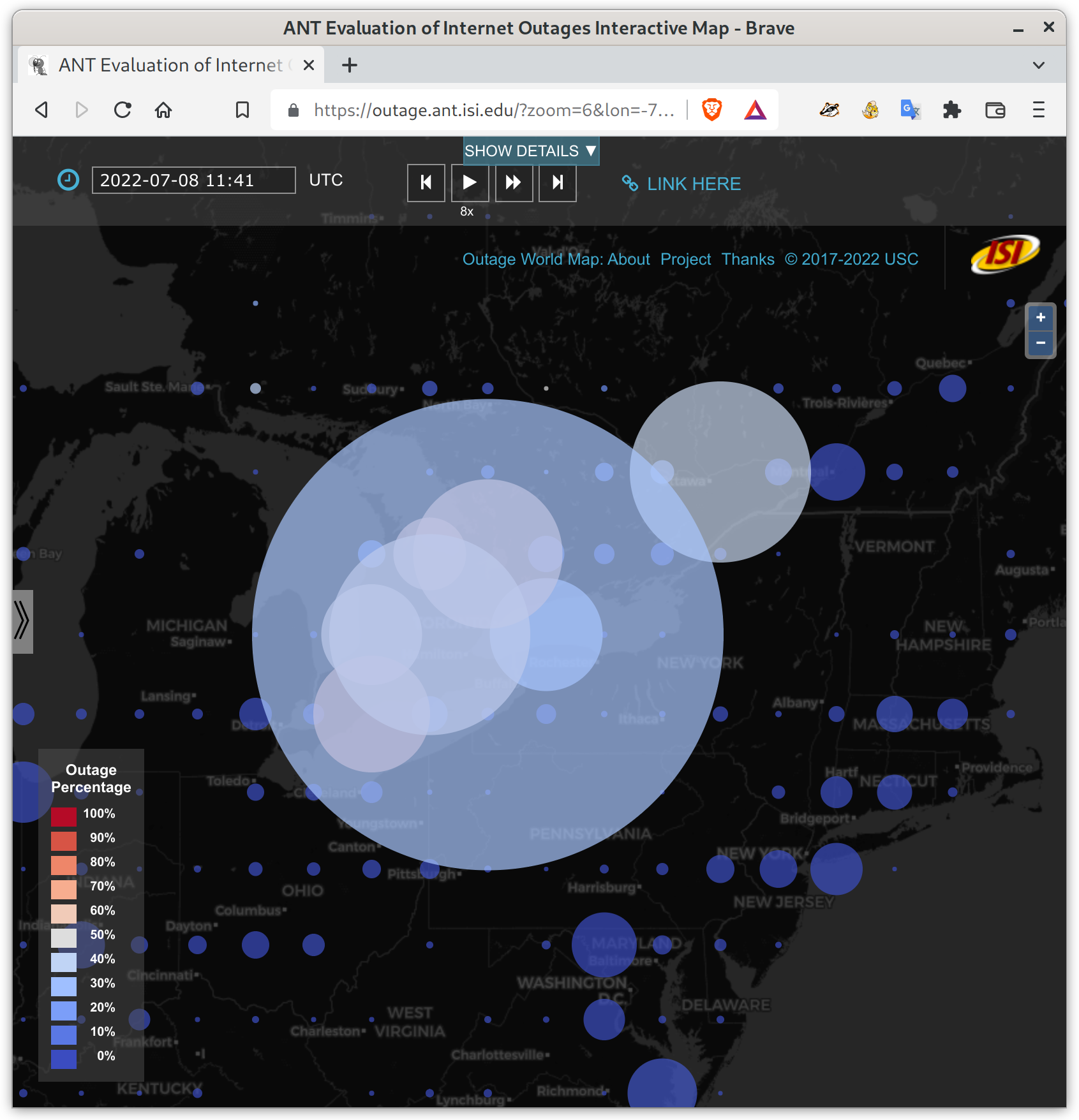
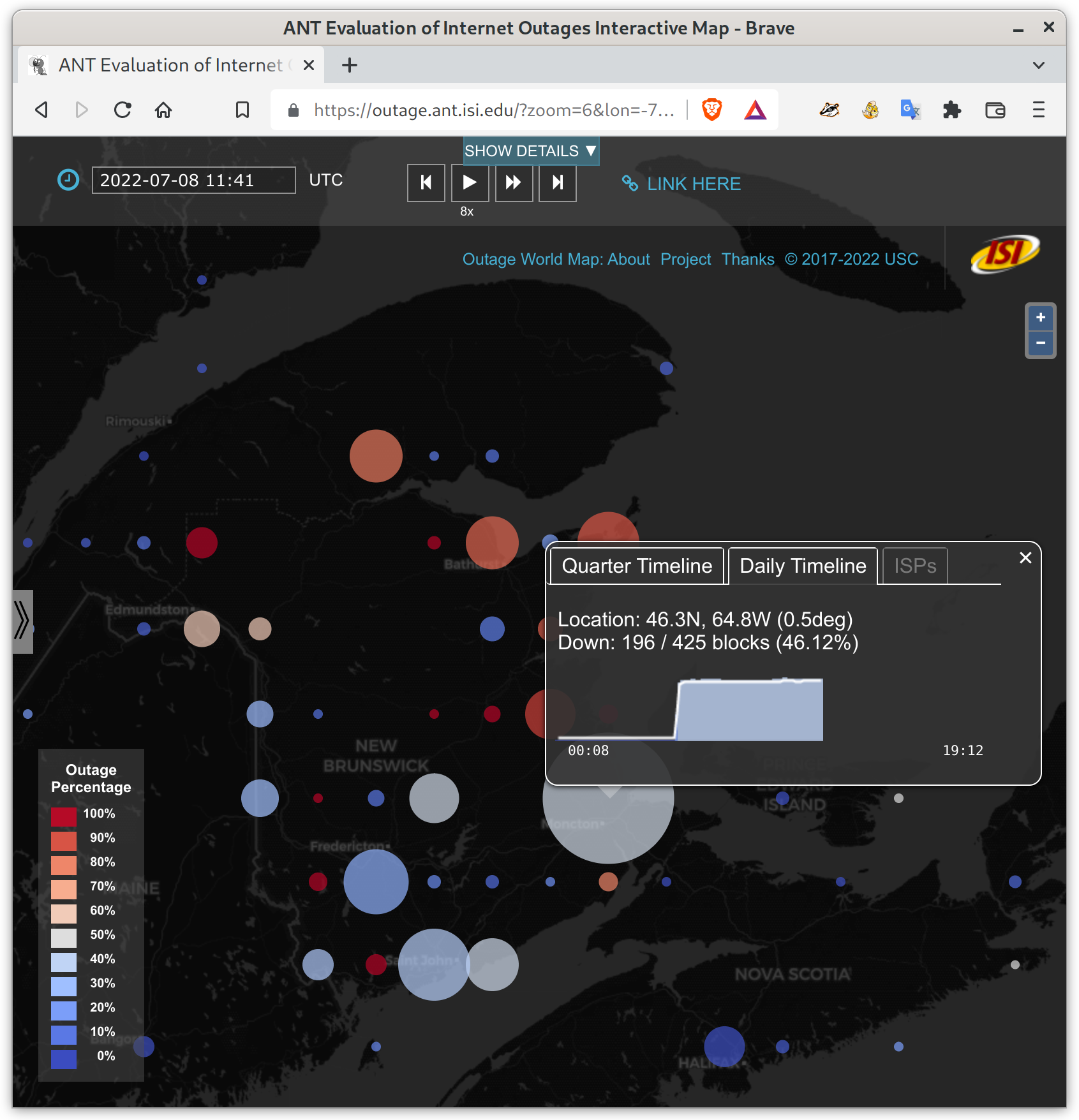
It’s big! Maybe 30% of Toronto and southern Ontario networks, plus a lot of outages in New Brunswick.
Ontario:
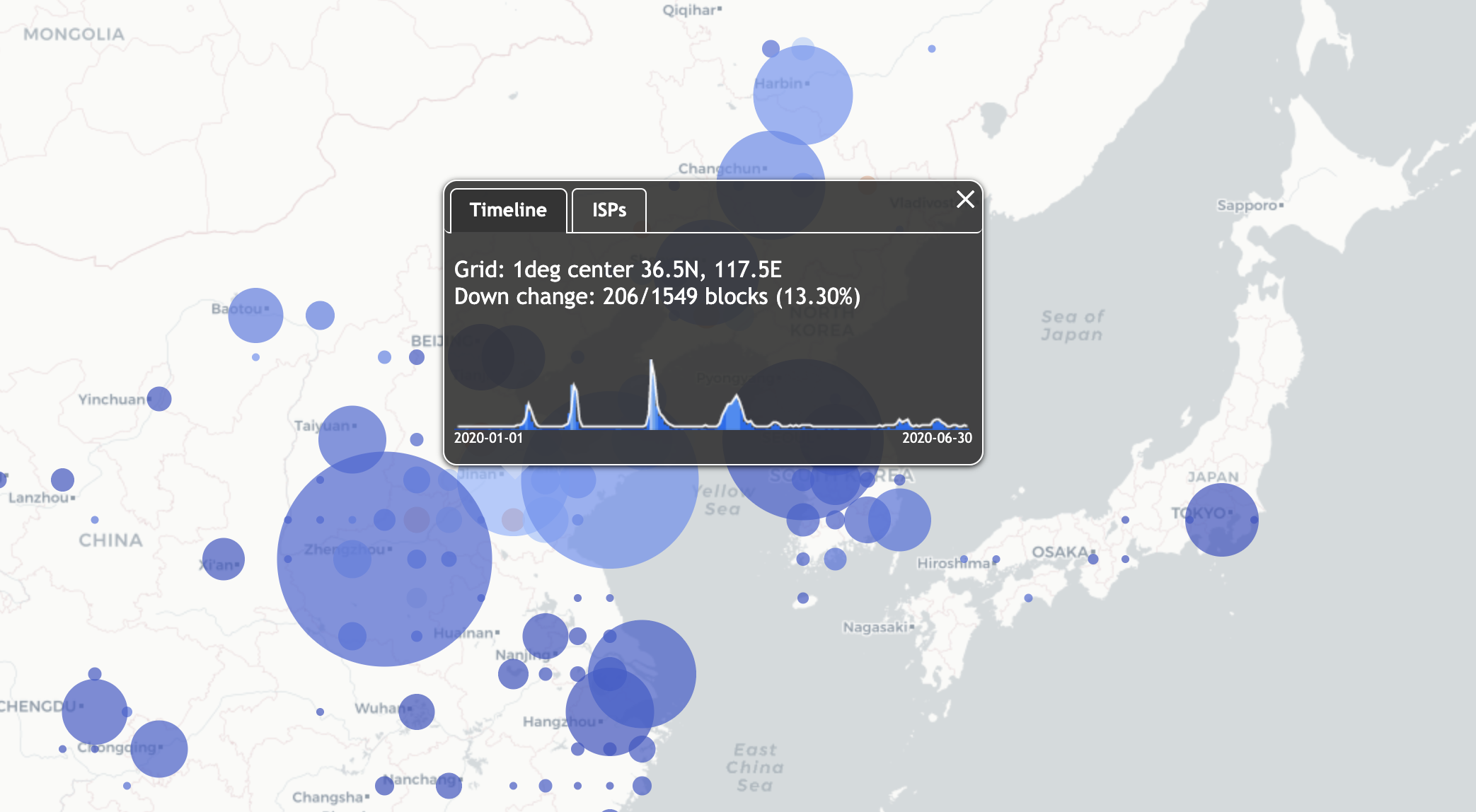
Internet outages in Ontario, Canada. The largest circle represents about 6500 /24 network blocks down near Toronto, about 30% of the /24 blocks in that area. See details on our outage website.
New Brunswick:
Internet outages in New Brunswick, Canada. The largest circle here represents 196 /24 network blocks down near Moncton, more than 45% of the /24 blocks there. The red circles are areas where most or all network blocks are currently out. See details on our outage website.
An update: Newfoundland also sees a lot of outages. Quebec looks in pretty good shape, though.
And it’s lasting a long time. It looks like it started at 5am Eastern time (2022-07-08t09:00Z), it it has lasted 9.5 hours so far!
We wish Rogers personnel and our Canadian neighbors the best.
Update at 2022-07-09t06:15Z (2:15am Eastern time): Toronto is doing much better, with “only” 10% of blocks unreachable (22808 of 21.5k in the 43.8N,79.3W 0.5 grid cell). New Brunswick and Newfoundland still look the same, with outages in about 50% of blocks.
Update at 2022-07-09t21:10Z (5:10pm Eastern time): It looks like many Rogers networks recovered at 2022-07-09t05:15Z (1:15am Eastern time). This includes all of New Brunswick and Newfoundland and most of Ontario. Trinocular has about a one-hour delay while it computes results, so I did not see this result when I checked in the prior update–I needed to wait 15 minutes more.
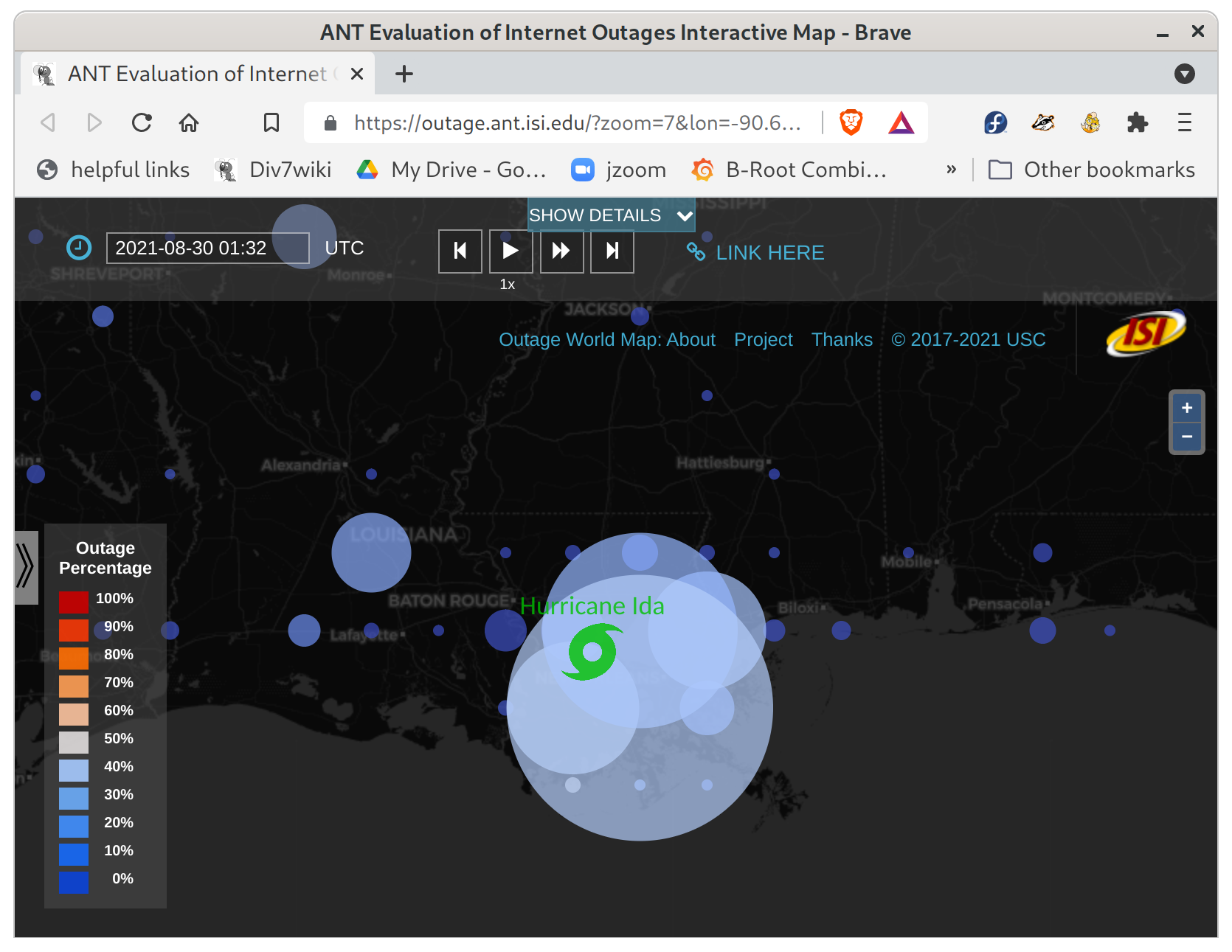
We recently added timeline support to our Outage World map–clicking on an outage bubble pops up a window with a sparkline (a small graph) showing maximum outages on each data for the current quarter, and clicking on the “daily timeline” tab shows outages for the current 24 hours. These graphs help provide context for how long an outage lasts, and if there were other outages the same quarter.
On March 29, 2022 the paper “Old but Gold: Prospecting TCP to Engineer and Live Monitor DNS Anycast” by Giovane C. M. Moura, John Heidemann, Wes Hardaker, Pithayuth Charnsethikul, Jeroen Bulten, João M. Ceron, and Cristian Hesselman appeared that the 2022 Passive and Active Measurement Conference. We’re happy that it was awarded Best Paper for this year’s conference!
From the abstract:
Google latency for .nl before (left red area) and after (middle green area) DNS polarization was corrected. Polarization was detected with ENTRADA using the work from this paper.
DNS latency is a concern for many service operators: CDNs exist to reduce service latency to end-users but must rely on global DNS for reachability and load-balancing. Today, DNS latency is monitored by active probing from distributed platforms like RIPE Atlas, with Verfploeter, or with commercial services. While Atlas coverage is wide, its 10k sites see only a fraction of the Internet. In this paper we show that passive observation of TCP handshakes can measure live DNS latency, continuously, providing good coverage of current clients of the service. Estimating RTT from TCP is an old idea, but its application to DNS has not previously been studied carefully. We show that there is sufficient TCP DNS traffic today to provide good operational coverage (particularly of IPv6), and very good temporal coverage (better than existing approaches), enabling near-real time evaluation of DNS latency from real clients. We also show that DNS servers can optionally solicit TCP to broaden coverage. We quantify coverage and show that estimates of DNS latency from TCP is consistent with UDP latency. Our approach finds previously unknown, real problems: DNS polarization is a new problem where a hypergiant sends global traffic to one anycast site rather than taking advantage of the global anycast deployment. Correcting polarization in Google DNS cut its latency from 100ms to 10ms; and from Microsoft Azure cut latency from 90ms to 20ms. We also show other instances of routing problems that add 100-200ms latency. Finally, real-time use of our approach for a European country-level domain has helped detect and correct a BGP routing misconfiguration that detoured European traffic to Australia. We have integrated our approach into several open source tools: Entrada, our open source data warehouse for DNS, a monitoring tool (ANTS), which has been operational for the last 2 years on a country-level top-level domain, and a DNS anonymization tool in use at a root server since March 2021.
This paper was made in part through DHS HSARPA Cyber Security Division via contract number HSHQDC-17-R-B0004-TTA.02-0006-I (PAADDOS) and by NWO, NSF CNS-1925737 (DIINER), and the Conconrdia Project, an European Union’s Horizon 2020 Research and Innovation program under Grant Agreement No 830927.
Erica Stutz completed her summer undergraduate research internship at ISI this summer, working with John Heidemann, Yuri Pradkin, and Xiao Song on her project “Visualizing COVID-19 Work-from-Home”.
In this project, Erica developed a new Covid-19 Work-From-Home website combinng Xiao WFH data with our existing outage website, and adding new interactive drill-down methods to display additional information to the user.
Visulizing Covid-19 work-from-home: here we look at China, Korea, and Japan and pop-up information about Laiwu, China. The popup shows WFH behavior for that location for the first 6 months of 2020.
We hope Erica’s new website makes it easier to evaluate COVID-19 WFH changes, and we look forward to continue to work with Erica on this topic.
Erica worked virtually at USC/ISI in summer 2021 as part of the (ISI Research Experiences for Undergraduates. We thank Jelena Mirkovic (PI) for coordinating the second year of this great program, and NSF for support through award #2051101.
At the end of June we had an ANT research group lunch to celebrate four (!) recent PhD defenses in 2020 and 2021: Hang Guo, Calvin Ardi, Lan Wei, and Abdul Qadeer. Although not everyone could be there (Hang has already moved for his new job), and the ANT lab includes a number of people outside of L.A. who could not make it, us students, staff, and family in L.A. had a great time at Vista del Mar Park near the beach!
A big thanks to Basileal Imana and ASM Rizvi for coordinating delivery of Ethiopian food for lunch.
We are also very thankful that vaccine availability in the U.S. is widespread and we were able to get together face-to-face after a year of Covid limitations. I’m happy that we’ve been able to do good work throughout the pandemic with remote collaboration tools and occasional on-site access, but it was nice to see old friends face-to-face again and share a meal. We hope the fall’s in-person classes at USC go well.
We published a new paper “Anycast in Context: A Tale of Two Systems” by Thomas Koch, Ke Li, Calvin Ardi*, Ethan Katz-Bassett, Matt Calder**, and John Heidemann* (of Columbia, where not otherwise indicated, *USC/ISI, and **Microsoft and Columbia) at ACM SIGCOMM 2021.
From the abstract:
Anycast is used to serve content including web pages and DNS, and anycast deployments are growing. However, prior work examining root DNS suggests anycast deployments incur significant inflation, with users often routed to suboptimal sites. We reassess anycast performance, first extending prior analysis on inflation in the root DNS. We show that inflation is very common in root DNS, affecting more than 95% of users. However, we then show root DNS latency hardly matters to users because caching is so effective. These findings lead us to question: is inflation inherent to anycast, or can inflation be limited when it matters? To answer this question, we consider Microsoft’s anycast CDN serving latency-sensitive content. Here, latency matters orders of magnitude more than for root DNS. Perhaps because of this need, only 35% of CDN users experience any inflation, and the amount they experience is smaller than for root DNS. We show that CDN anycast latency has little inflation due to extensive peering and engineering. These results suggest prior claims of anycast inefficiency reflect experiments on a single application rather than anycast’s technical potential, and they demonstrate the importance of context when measuring system performance.
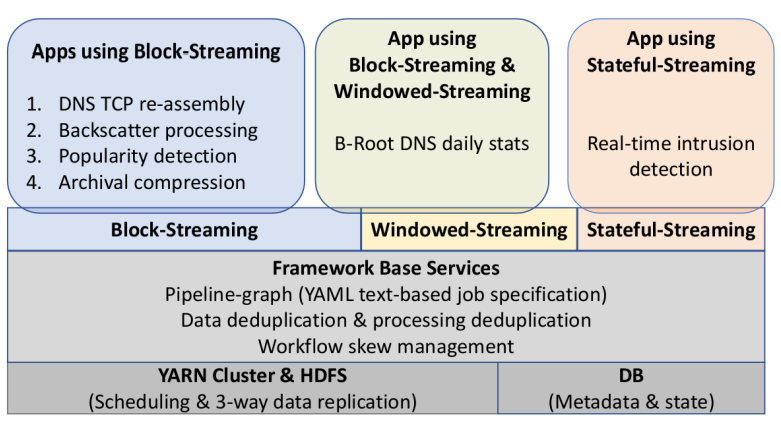
We show that one framework can efficiently support multiple abstractions. We provide three abstractions of Block, Windowed, and Stateful streaming and demonstrate that many application classes can be developed with ease, correctness, and low processing latency.
From the abstract of our paper:
Large websites and distributed systems employ sophisticated analytics to evaluate successes to celebrate and problems to be addressed. As analytics grow, different teams often require different frameworks, with dozens of packages supporting with streaming and batch processing, SQL and no-SQL. Bringing multiple frameworks to bear on a large, changing dataset often create challenges where data transitions—these impedance mismatches can create brittle glue logic and performance problems that consume developer time. We propose Plumb, a meta-framework that can bridge three different abstractions to meet the needs of a large class of applications in a common workflow. Large-block streaming (Block-Streaming) is suitable for single-pass applications that care about the temporal and spatial locality. Windowed-Streaming allows applications to process a group of data and many reductions. Stateful-Streaming enables applications to keep a long-term state and always-on behavior. We show that it is possible to bridge abstractions, with a common, high-level workflow specification, while the system transitions data batch processing and block- and record-level streaming as required. The challenge in bridging abstractions is to minimize latency while allowing applications to select between sequential and parallel operation, while handling out-of-order data delivery, component failures, and providing clear semantics in the face of missing data. We demonstrate these abstractions evaluating a 10-stage workflow of DNS analytics that has been in production use with Plumb for 2 years, comparing to a brittle hand-built system that has run for more than 3 years.
This conference paper is joint work of Abdul Qadeer and John Heidemann from USC/ISI.
WOMBIR 2021 was the NSF-sponsored Workshop on Overcoming Measurement Barriers to Internet Research. This workshop was hold in two sessions over several days in January and April 2021, chaired by k.c. claffy, David Clark, Fabian Bustamente, John Heidemann, and Mattijs Monjker. The final report includes contributions from Aaron Schulman and Ellen Zegura as well as all the workshop participants.
From the abstract:
In January and April 2021 we held the Workshop on Overcoming Measurement Barriers to Internet Research (WOMBIR) with the goal of understanding challenges in network and security data set collection and sharing. Most workshop attendees provided white papers describing their perspectives, and many participated in short-talks and discussion in two virtual workshops over five days. That discussion produced consensus around several points. First, many aspects of the Internet are characterized by decreasing visibility of important network properties, which is in tension with the Internet’s role as critical infrastructure. We discussed three specific research areas that illustrate this tension: security, Internet access; and mobile networking. We discussed visibility challenges at all layers of the networking stack, and the challenge of gathering data and validating inferences. Important data sets require longitudinal (long-term, ongoing) data collection and sharing, support for which is more challenging for Internet research than other fields. We discussed why a combination of technical and policy methods are necessary to safeguard privacy when using or sharing measurement data. Workshop participant proposed several opportunities to accelerate progress, some of which require coordination across government, industry, and academia.
Since 2014 the ANT lab at USC has been observing the visible IPv4 Internet (currently 5 million networks measured every 11 minutes) to detect network outages. This talk explores how we use this large-scale, active measurement to estimate Internet reliability and understand the effects of real-world events such as hurricanes. We have recently developed new algorithms to identify Covid-19-related Work-from-Home and other Internet shutdowns in this data. Our Internet outage work is joint work of John Heidemann, Lin Quan, Yuri Pradkin, Guillermo Baltra, Xiao Song, and Asma Enayet with contributions from Ryan Bogutz, Dominik Staros, Abdulla Alwabel, and Aqib Nisar.
This project is joint work of a number of people listed in the abstract above, and is supported by NSF 2028279 (MINCEQ) and CNS-2007106 (EIEIO). All data from this paper is available at no cost to researchers.