We will publish a new paper “Identifying Important Internet Outages” by Ryan Bogutz, Yuri Pradkin, and John Heidemann, in the Sixth National Symposium for NSF REU Research in Data Science, Systems, and Security in Los Angeles, California, USA, on December 12, 2019.
From the abstract:
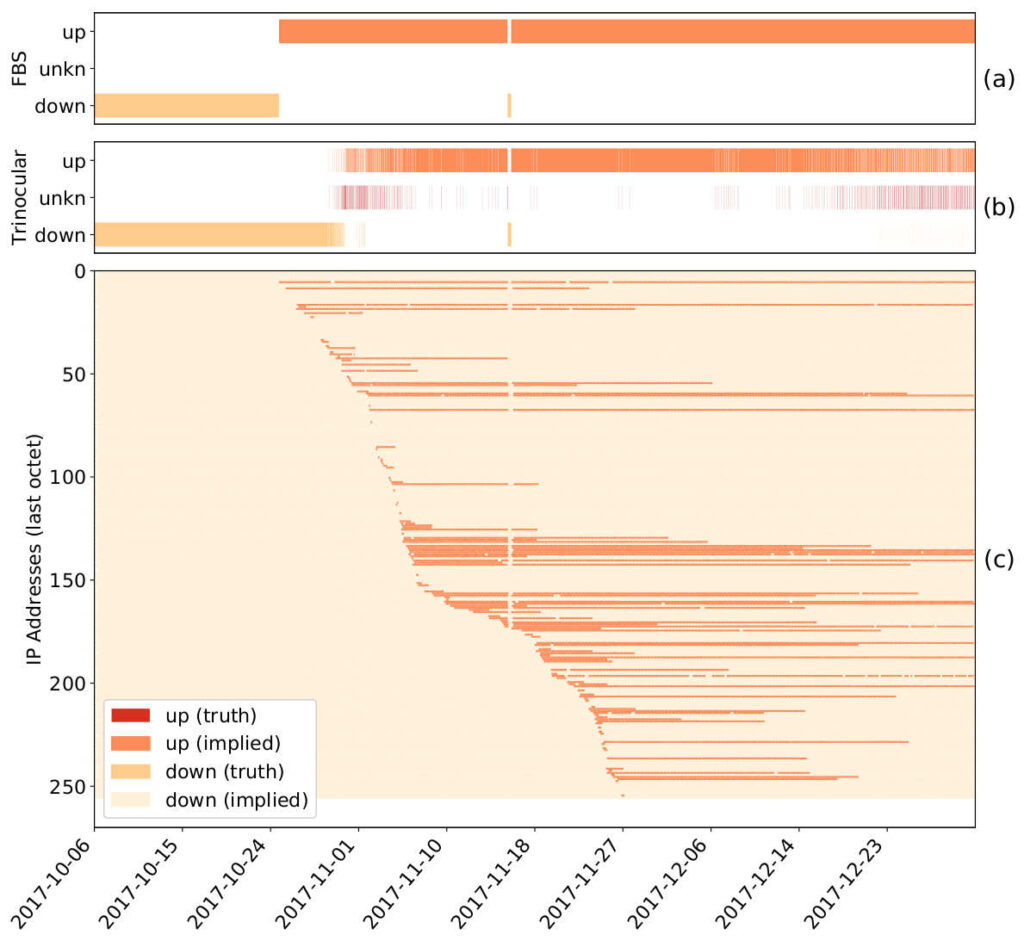
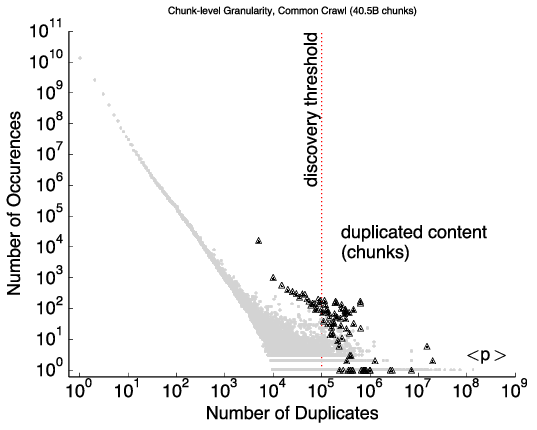
Today, outage detection systems can track outages across the whole IPv4 Internet—millions of networks. However, it becomes difficult to find meaningful, interesting events in this huge dataset, since three months of data can easily include 660M observations and thousands of outage events. We propose an outage reporting system that sifts through this data to find the most interesting events. We explore multiple metrics to evaluate interesting”, reflecting the size and severity of outages. We show that defining interest as the product of size by severity works well, avoiding degenerate cases like complete outages affecting a few people, and apparently large outages that affect only a small fraction of people in an area. We have integrated outage reporting into our existing public website (https://outage.ant.isi.edu) with the goal of making near-real-time outage information accessible to the general public. Such data can help answer questions like “what are the most significant outages today?”, did Florida have major problems in an ongoing hurricane?”, and
“are there power outages in Venezuela?”.
The data from this paper is available publicly and in our website. The technical report ISI-TR-735 includes some additional data.