We published a new paper “Bidirectional Anycast/Unicast Probing (BAUP): Optimizing CDN Anycast” by Lan Wei (University of Southern California/ ISI), Marcel Flores (Verizon Digital Media Services), Harkeerat Bedi (Verizon Digital Media Services), John Heidemann (University of Southern California/ ISI) at Network Traffic Measurement and Analysis Conference 2020.
From the abstract:
IP anycast is widely used today in Content Delivery Networks (CDNs) and for Domain Name System (DNS) to provide efficient service to clients from multiple physical points-of-presence (PoPs). Anycast depends on BGP routing to map users to PoPs, so anycast efficiency depends on both the CDN operator and the routing policies of other ISPs. Detecting and diagnosing
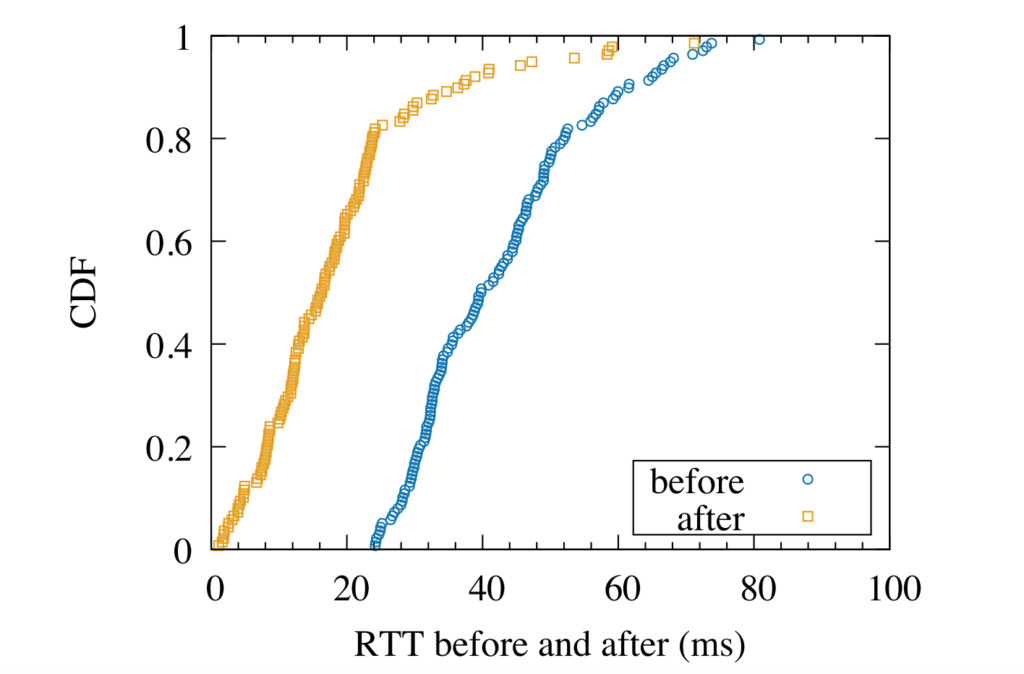
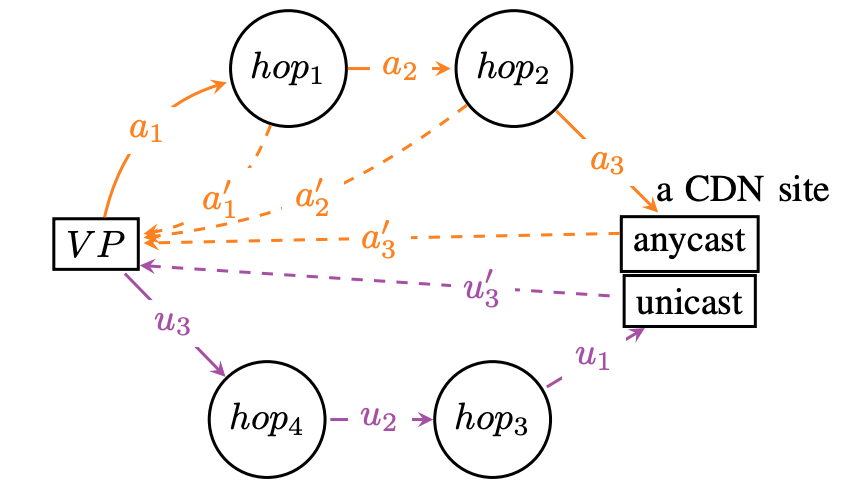
inefficiency is challenging in this distributed environment. We propose Bidirectional Anycast/Unicast Probing (BAUP), a new approach that detects anycast routing problems by comparing anycast and unicast latencies. BAUP measures latency to help us identify problems experienced by clients, triggering traceroutes to localize the cause and suggest opportunities for improvement. Evaluating BAUP on a large, commercial CDN, we show that problems happens to 1.59% of observers, and we find multiple opportunities to improve service. Prompted by our work, the CDN changed peering policy and was able to significantly reduce latency, cutting median latency in half (40 ms to 16 ms) for regions with more than 100k users.
The data from this paper is publicly available from RIPE Atlas, please see paper reference for measurement IDs.