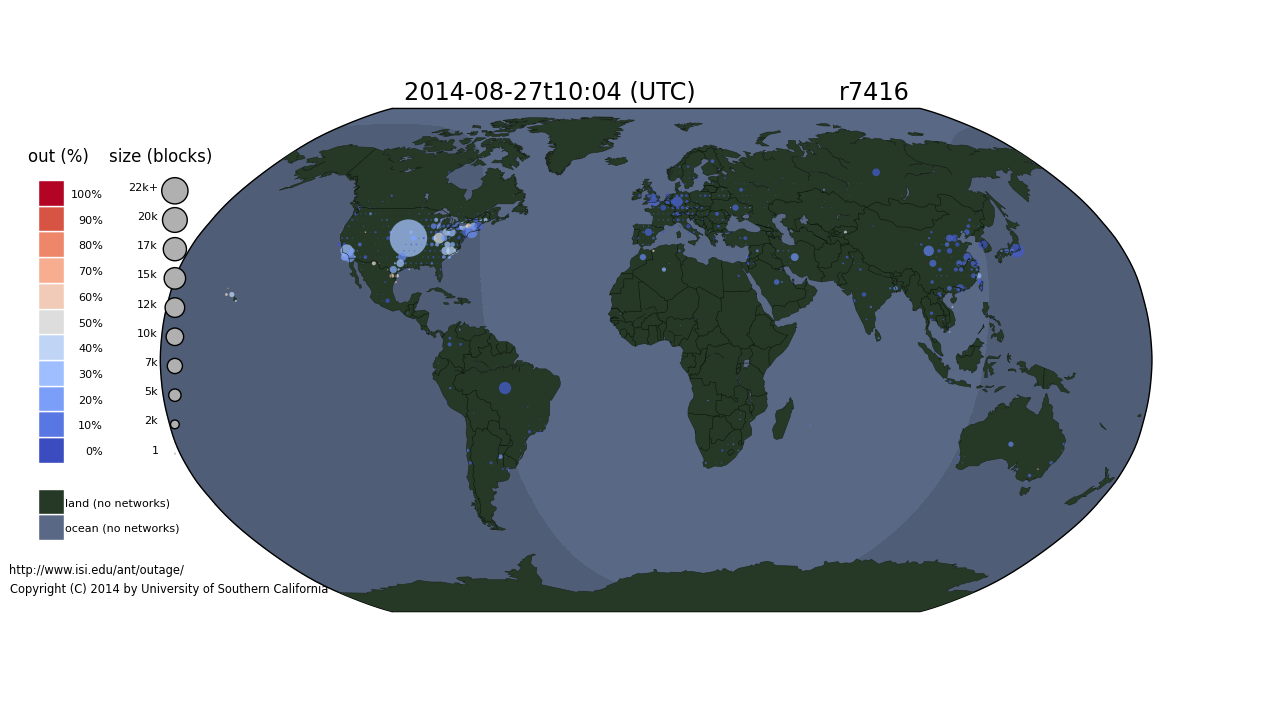
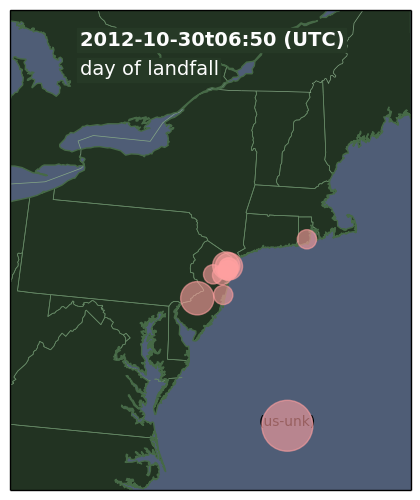
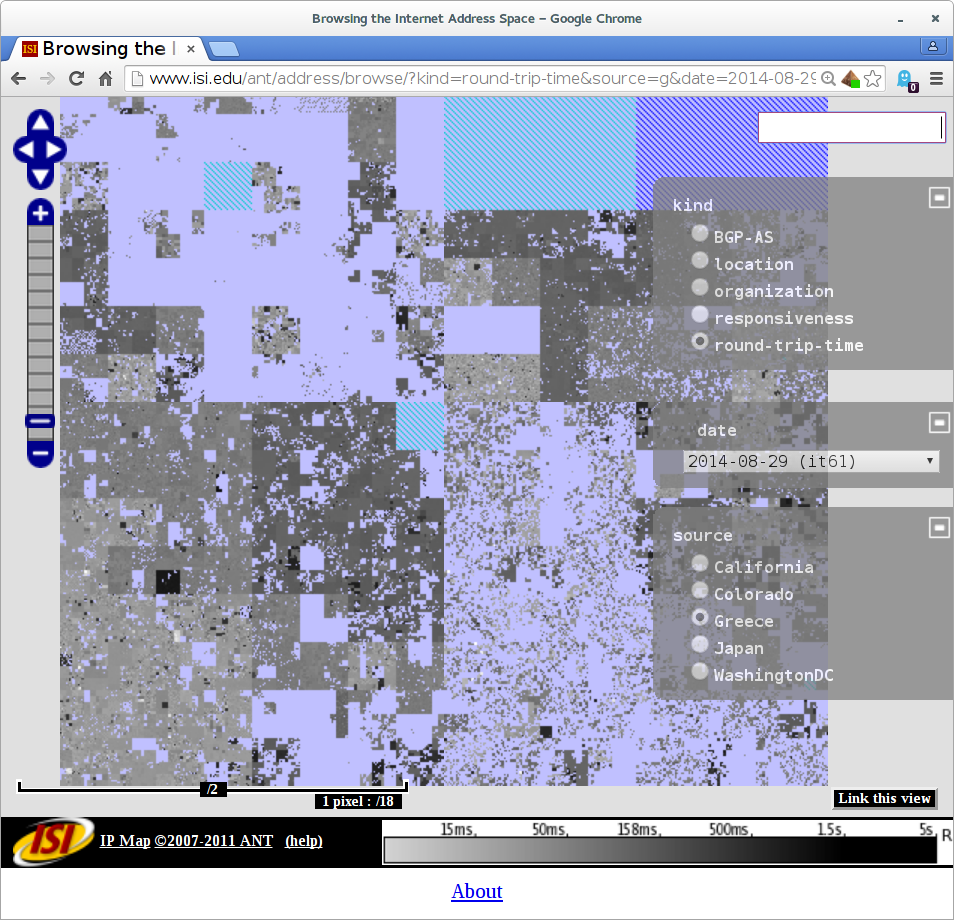
I would like to congratulate Dr. Xun Fan for defending his PhD in May 2015 and completing his doctoral dissertation “Enabling Efficient Service Enumeration Through Smart Selection of Measurements” in July 2015.

From the abstract:
The Internet is becoming more and more important in our daily lives. Both the government and industry invest in the growth of the Internet, bringing more users to the world of networks. As the Internet grows, researchers and operators need to track and understand the behavior of global Internet services to achieve smooth operation. Active measurements are often used to study behavior of large Internet service, and efficient service enumeration is required. For example, studies of Internet topology may need active probing to all visible network prefixes; monitoring large replicated service requires periodical enumeration of all service replicas. To achieve efficient service enumeration, it is important to select probing sources and destinations wisely. However, there are challenges for making smart selection of probing sources and destinations. Prior methods to select probing destinations are either inefficient or hard to maintain. Enumerating replicas of large Internet services often requires many widely distributed probing sources. Current measurement platforms don’t have enough probing sources to approach complete enumeration of large services.
This dissertation makes the thesis statement that smart selection of probing sources and destinations enables efficient enumeration of global Internet services to track and understand their behavior. We present three studies to demonstrate this thesis statement. First, we propose new automated approach to generate a list of destination IP addresses that enables efficient enumeration of Internet edge links. Second, we show that using large number of widely distributed open resolvers enables efficient enumeration of anycast nodes which helps study abnormal behavior of anycast DNS services. In our last study, we efficiently enumerate Front-End (FE) Clusters of Content Delivery Networks (CDNs) and use the efficient enumeration to track and understand the dynamics of user-to-FE Cluster mapping of large CDNs. We achieve the efficient enumeration of CDN FE Clusters by selecting probing sources from a large set of open resolvers. Our selected probing sources have smaller number of open resolvers but provide same coverage on CDN FE Cluster as the larger set.
In addition to our direct results, our work has also been used by several published studies to track and understand the behavior of Internet and large network services. These studies not only support our thesis as additional examples but also suggest this thesis can further benefit many other studies that need efficient service enumeration to track and understand behavior of global Internet services.
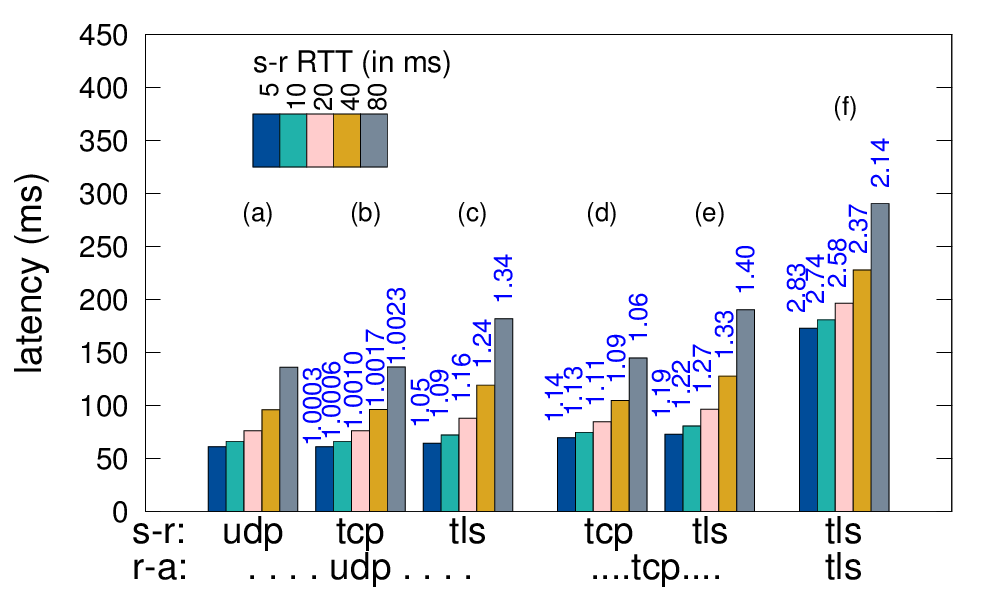
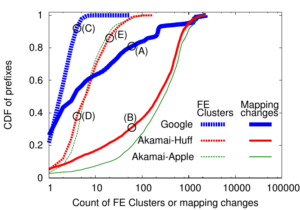 Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.
Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.