We have published a new paper “IP-Based IoT Device Detection” in the Second ACM Workshop on Internet-of-Things Security and Privacy (IoTS&P 2018) in Budapest, Hungary, co-located with SIGCOMM 2018.

Recent IoT-based DDoS attacks have exposed how vulnerable the Internet can be to millions of insufficiently secured IoT devices. To understand the risks of these attacks requires
learning about these IoT devices—where are they, how many are there, how are they changing? In this paper, we propose
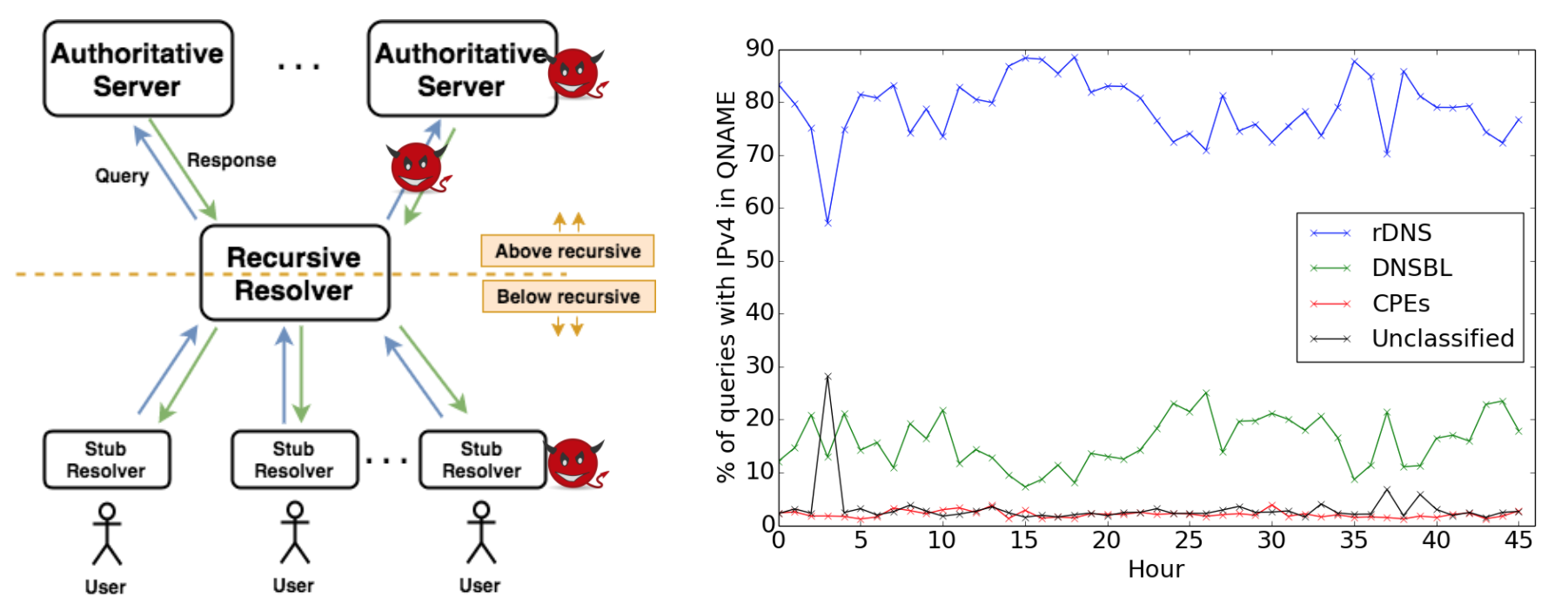
a new method to find IoT devices in Internet to begin to assess this threat. Our approach requires observations of flow-level network traffic and knowledge of servers run by
the manufacturers of the IoT devices. We have developed our approach with 10 device models by 7 vendors and controlled
experiments. We apply our algorithm to observations from 6 days of Internet traffic at a college campus and partial traffic
from an IXP to detect IoT devices.
We make operational traffic we captured from 10 IoT devices we own public at https://ant.isi.edu/datasets/iot/. We also use operational traffic of 21 IoT devices shared by University of New South Wales at http://149.171.189.1/.
This paper is joint work of Hang Guo and John Heidemann from USC/ISI.