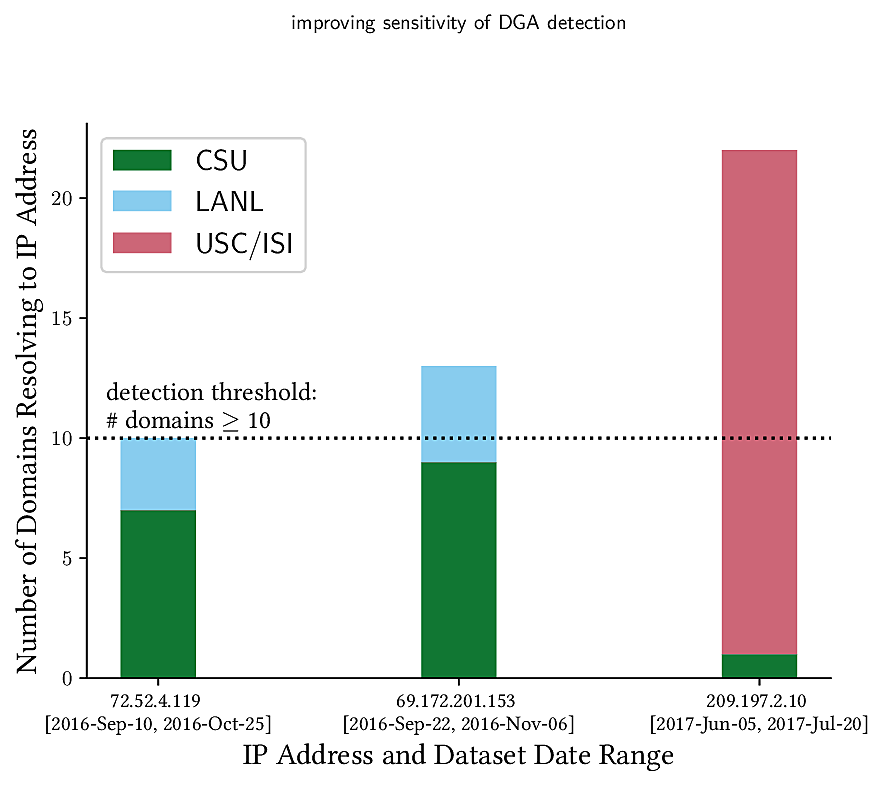
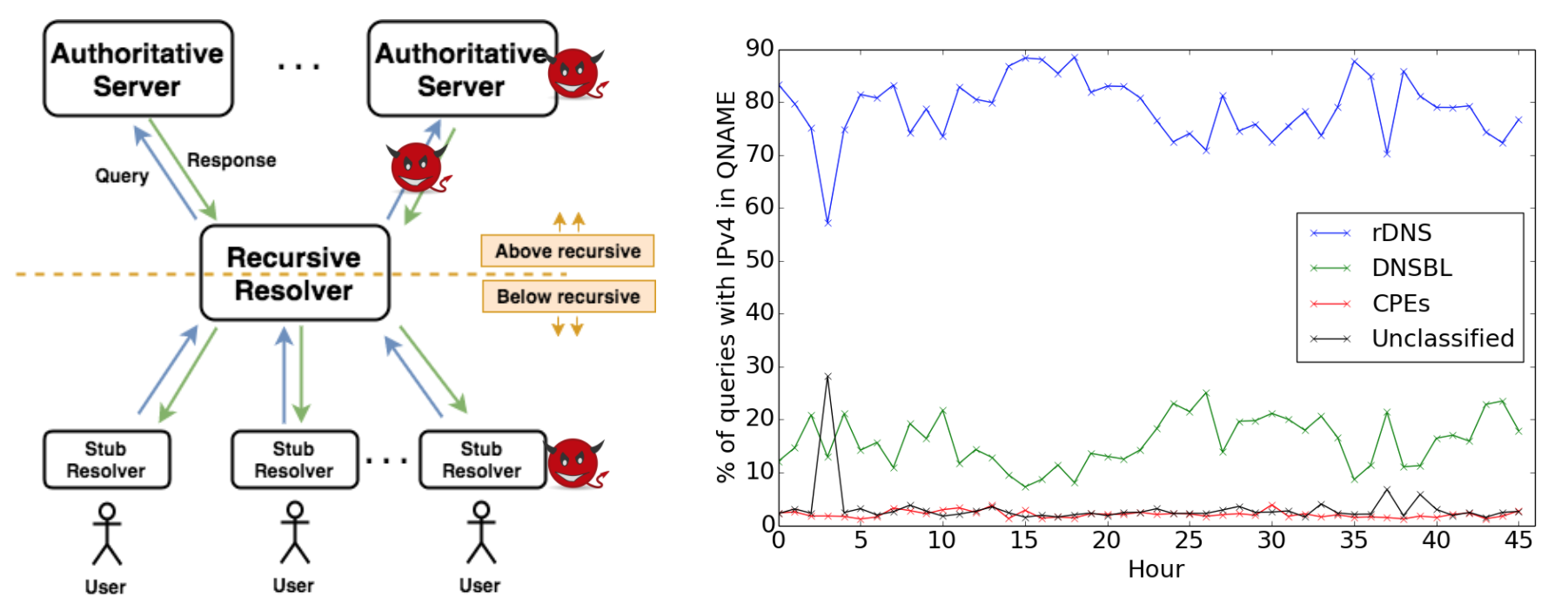
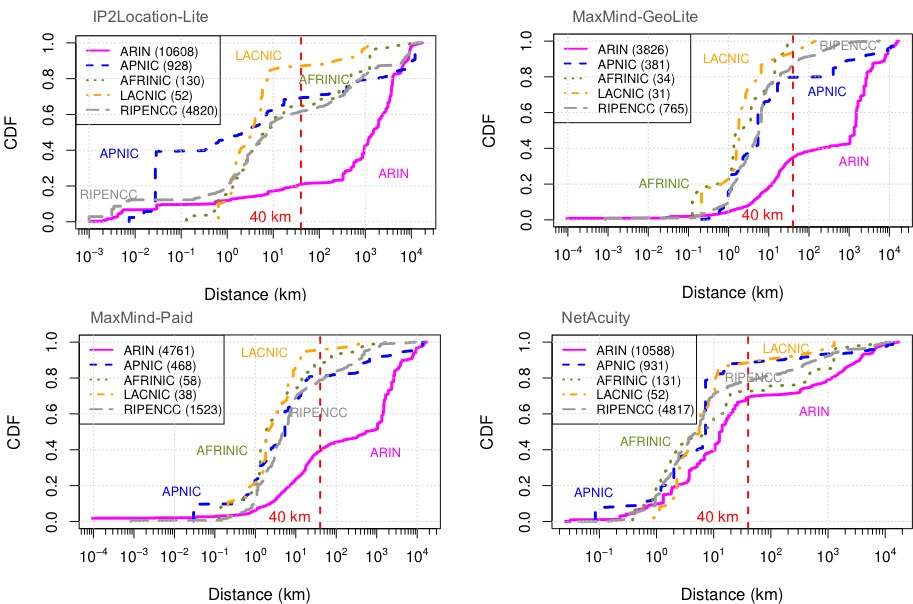
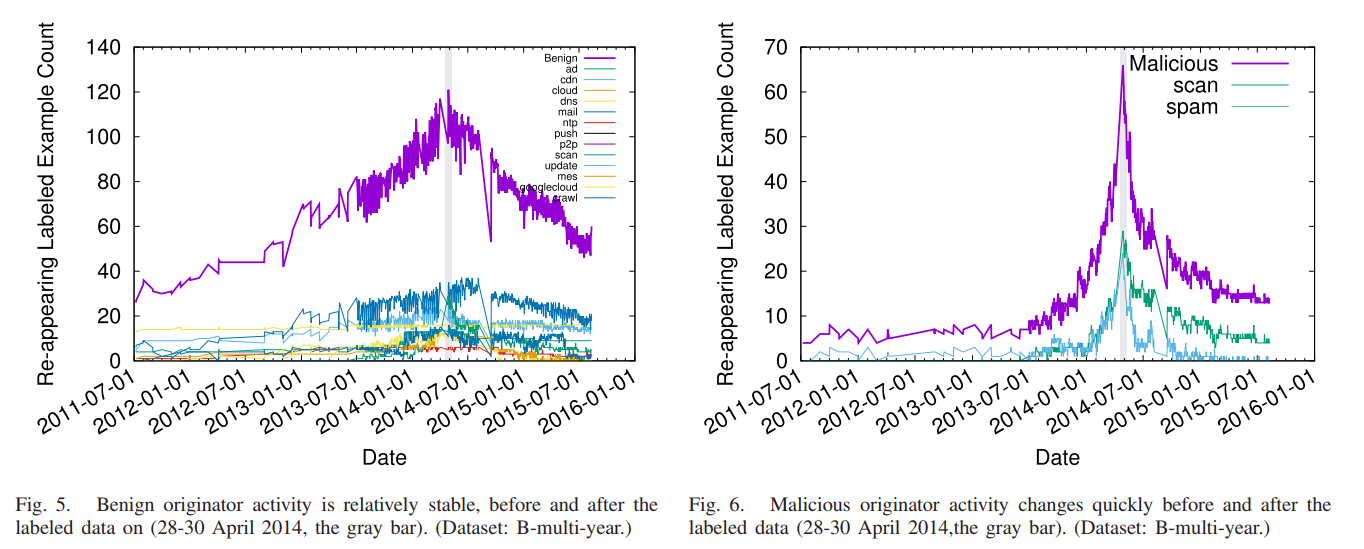
We have published a new paper LDplayer: DNS Experimentation at Scale by Liang Zhu and John Heidemann, in the ACM Internet Measurements Conference (IMC 2018) in Boston, Mass., USA.
From the abstract:
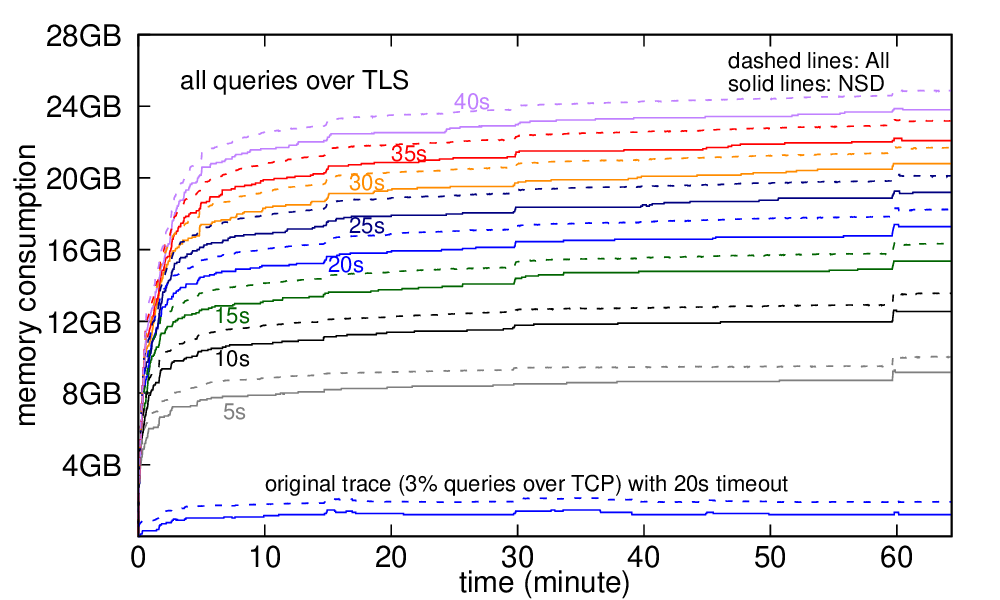
DNS has evolved over the last 20 years, improving in security and privacy and broadening the kinds of applications it supports. However, this evolution has been slowed by the large installed base and the wide range of implementations. The impact of changes is difficult to model due to complex interactions between DNS optimizations, caching, and distributed operation. We suggest that experimentation at scale is needed to evaluate changes and facilitate DNS evolution. This paper presents LDplayer, a configurable, general-purpose DNS experimental framework that enables DNS experiments to scale in several dimensions: many zones, multiple levels of DNS hierarchy, high query rates, and diverse query sources. LDplayer provides high fidelity experiments while meeting these requirements through its distributed DNS query replay system, methods to rebuild the relevant DNS hierarchy from traces, and efficient emulation of this hierarchy on minimal hardware. We show that a single DNS server can correctly emulate multiple independent levels of the DNS hierarchy while providing correct responses as if they were independent. We validate that our system can replay a DNS root traffic with tiny error (± 8 ms quartiles in query timing and ± 0.1% difference in query rate). We show that our system can replay queries at 87k queries/s while using only one CPU, more than twice of a normal DNS Root traffic rate. LDplayer’s trace replay has the unique ability to evaluate important design questions with confidence that we capture the interplay of caching, timeouts, and resource constraints. As an example, we demonstrate the memory requirements of a DNS root server with all traffic running over TCP and TLS, and identify performance discontinuities in latency as a function of client RTT.