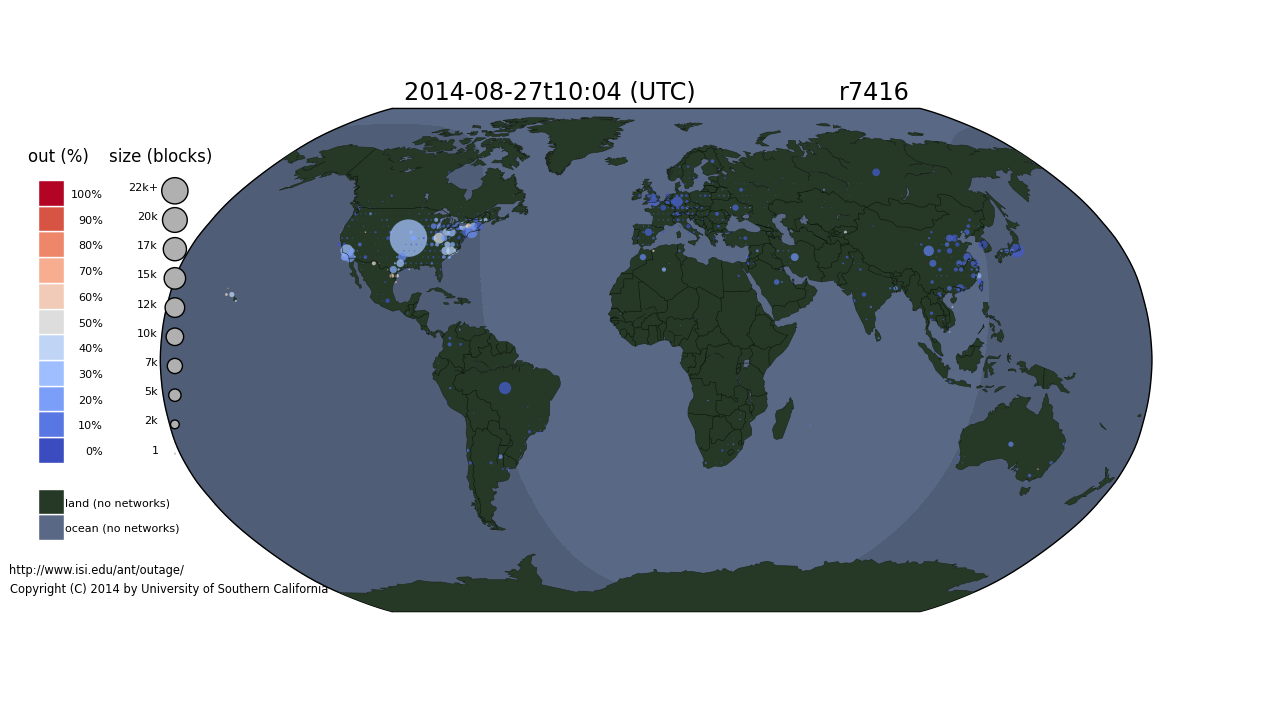
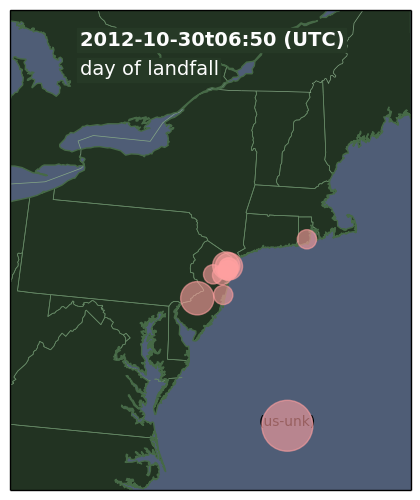
We released a new technical report “Poster: Lightweight Content-based Phishing Detection”, ISI-TR-698, available at http://www.isi.edu/publications/trpublic/files/tr-698.pdf.
The poster abstract and poster (included as part of the technical report) appeared at the poster session at the 36th IEEE Symposium on Security and Privacy in May 2015 in San Jose, CA, USA.
We have released an alpha version of our extension and source code here: http://www.isi.edu/ant/software/phish/.
We would greatly appreciate any help and feedback in testing our plugin!
From the abstract:
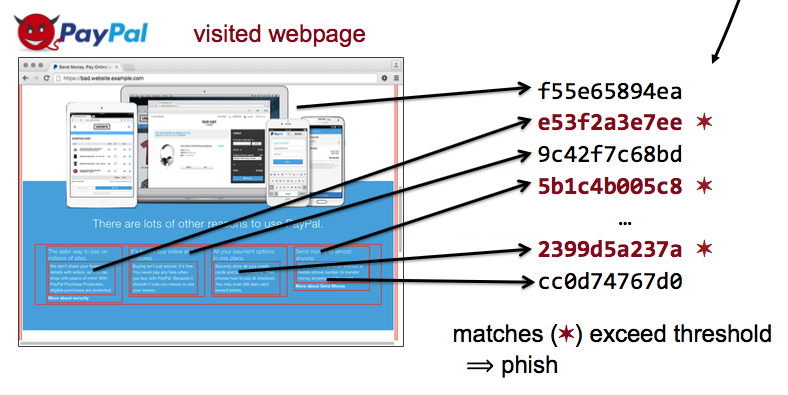
Increasing use of Internet banking and shopping by a broad spectrum of users results in greater potential profits from phishing attacks via websites that masquerade as legitimate sites to trick users into sharing passwords or financial information. Most browsers today detect potential phishing with URL blacklists; while effective at stopping previously known threats, blacklists must react to new threats as they are discovered, leaving users vulnerable for a period of time. Alternatively, whitelists can be used to identify “known-good” websites so that off-list sites (to include possible phish) can never be accessed, but are too limited for many users. Our goal is proactive detection of phishing websites with neither the delay of blacklist identification nor the strict constraints of whitelists. Our approach is to list known phishing targets, index the content at their correct sites, and then look for this content to appear at incorrect sites. Our insight is that cryptographic hashing of page contents allows for efficient bulk identification of content reuse at phishing sites. Our contribution is a system to detect phish by comparing hashes of visited websites to the hashes of the original, known good, legitimate website. We implement our approach as a browser extension in Google Chrome and show that our algorithms detect a majority of phish, even with minimal countermeasures to page obfuscation. A small number of alpha users have been using the extension without issues for several weeks, and we will be releasing our extension and source code upon publication.
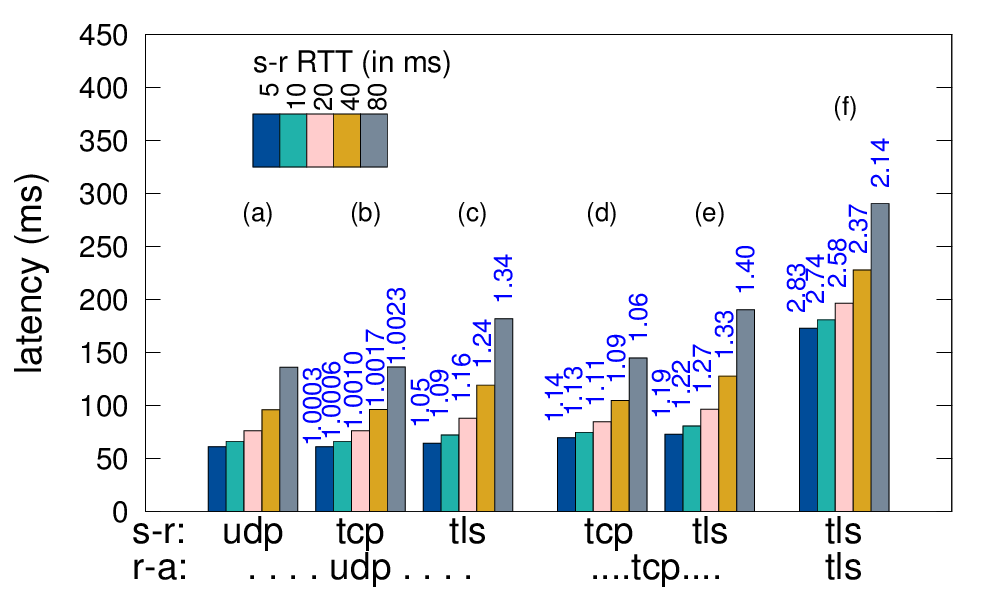
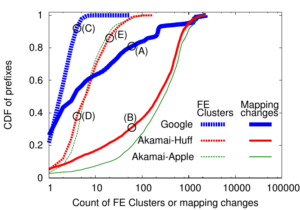 Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.
Large web services employ CDNs to improve user performance. CDNs improve performance by serving users from nearby FrontEnd (FE) Clusters. They also spread users across FE Clusters when one is overloaded or unavailable and others have unused capacity. Our paper is the first to study the dynamics of the user-to-FE Cluster mapping for Google and Akamai from a large range of client prefixes. We measure how 32,000 prefixes associate with FE Clusters in their CDNs every 15 minutes for more than a month. We study geographic and latency effects of mapping changes, showing that 50–70% of prefixes switch between FE Clusters that are very distant from each other (more than 1,000 km), and that these shifts sometimes (28–40% of the time) result in large latency shifts (100 ms or more). Most prefixes see large latencies only briefly, but a few (2–5%) see high latency much of the time. We also find that many prefixes are directed to several countries over the course of a month, complicating questions of jurisdiction.