We’re happy to be hosting DINR-2016 (DNS and Internet Naming Research Directions).
The workshop program is now online; folks interested in joining us should contact the chairs.
We’re looking forward to an exciting day of many short talks!
We’re happy to be hosting DINR-2016 (DNS and Internet Naming Research Directions).
The workshop program is now online; folks interested in joining us should contact the chairs.
We’re looking forward to an exciting day of many short talks!
John Heidemann gave the talk “Anycast vs. DDoS: Evaluating Nov. 30” at DNS-OARC in Dallas, Texas, USA on October 16, 2016. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann16c.pdf.
From the abstract:
Distributed Denial-of-Service (DDoS) attacks continue to be a major threat in the Internet today. DDoS attacks overwhelm target services with requests or other “bogus” traffic, causing requests from legitimate users to be shut out. A common defense against DDoS is to replicate the service in multiple physical locations or sites. If all sites announce a common IP address, BGP will associate users around the Internet with a nearby site, defining the catchment of that site. Anycast adds resilience against DDoS both by increasing capacity to the aggregate of many sites, and allowing each catchment to contain attack traffic leaving other sites unaffected. IP anycast is widely used for commercial CDNs and essential infrastructure such as DNS, but there is little evaluation of anycast under stress.
This talk will provide a first evaluation of several anycast services under stress with public data. Our subject is the Internet’s Root Domain Name Service, made up of 13 independently designed services (“letters”, 11 with IP anycast) running at more than 500 sites. Many of these services were stressed by sustained traffic at 100x normal load on Nov. 30 and Dec. 1, 2015. We use public data for most of our analysis to examine how different services respond to the these events. In our analysis we identify two policies by operators: (1) sites may absorb attack traffic, containing the damage but reducing service to some users, or (2) they may withdraw routes to shift both legitimate and bogus traffic to other sites. We study how these deployment policies result in different levels of service to different users, during and immediately after the attacks.
We also show evidence of collateral damage on other services located near the attack targets. The work is based on analysis of DNS response from around 9000 RIPE Atlas vantage points (or “probes”), agumented by RSSAC-002 reports from 5 root letters and BGP data from BGPmon. We examine DNS performance for each Root Letter, for anycast sites inside specific letters, and for specific servers at one site.
This talk is based on the work in the paper “Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event” at appear at IMC 2016, by Giovane C. M. Moura, Ricardo de O. Schmidt, John Heidemann, Wouter B. de Vries, Moritz Müller, Lan Wei, and Christian Hesselman.
Datasets from the paper are available at https://ant.isi.edu/datasets/anycast/
John Heidemann gave the talk “Anycast Latency: How Many Sites are Enough?” at DNS-OARC in Dallas, Texas, USA on October 16, 2016. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann16b.pdf.
![]()
This talk will evaluate anycast latency. An anycast service uses multiple sites to provide high availability, capacity and redundancy, with BGP routing associating users to nearby anycast sites. Routing defines the catchment of the users that each site serves. Although prior work has studied how users associate with anycast services informally, in this paper we examine the key question how many anycast sites are needed to provide good latency, and the worst case latencies that specific deployments see. To answer this question, we must first define the optimal performance that is possible, then explore how routing, specific anycast policies, and site location affect performance. We develop a new method capable of determining optimal performance and use it to study four real-world anycast services operated by different organizations: C-, F-, K-, and L-Root, each part of the Root DNS service. We measure their performance from more than worldwide vantage points (VPs) in RIPE Atlas. (Given the VPs uneven geographic distribution, we evaluate and control for potential bias.) Key results of our study are to show that a few sites can provide performance nearly as good as many, and that geographic location and good connectivity have a far stronger effect on latency than having many nodes. We show how often users see the closest anycast site, and how strongly routing policy affects site selection.
This talk is based on the work in the technical report “Anycast Latency: How Many Sites Are Enough?” (ISI-TR-2016-708), by Ricardo de O. Schmidt, John Heidemann, and Jan Harm Kuipers.
Datasets from the paper are available at https://ant.isi.edu/datasets/anycast/
The paper “Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event” will appear at ACM Internet Measurement Conference in November 2016 in Santa Monica, California, USA. (previously available at http://www.isi.edu/~weilan/PAPER/IMC2016camera.pdf)
From the abstract:
Distributed Denial-of-Service (DDoS) attacks continue to be a major threat in the Internet today. DDoS attacks overwhelm target services with requests or other traffic, causing requests from legitimate users to be shut out. A common defense against DDoS is to replicate the service in multiple physical locations or sites. If all sites announce a common IP address, BGP will associate users around the Internet with a nearby site,defining the catchment of that site. Anycast addresses DDoS both by increasing capacity to the aggregate of many sites, and allowing each catchment to contain attack traffic leaving other sites unaffected. IP anycast is widely used for commercial CDNs and essential infrastructure such as DNS, but there is little evaluation of anycast under stress. This paper provides the first evaluation of several anycast services under stress with public data. Our subject is the Internet’s Root Domain Name Service, made up of 13 independently designed services (“letters”, 11 with IP anycast) running at more than 500 sites. Many of these services were stressed by sustained traffic at 100 times normal load on Nov.30 and Dec.1, 2015. We use public data for most of our analysis to examine how different services respond to the these events. We see how different anycast deployments respond to stress, and identify two policies: sites may absorb attack traffic, containing the damage but reducing service to some users, or they may withdraw routes to shift both good and bad traffic to other sites. We study how these deployments policies result in different levels of service to different users. We also show evidence of collateral damage on other services located near the attacks.
This IMC paper is joint work of Giovane C. M. Moura, Moritz Müller, Cristian Hesselman (SIDN Labs), Ricardo de O. Schmidt, Wouter B. de Vries (U. Twente), John Heidemann, Lan Wei (USC/ISI). Datasets in this paper are derived from RIPE Atlas and are available at http://traces.simpleweb.org/ and at https://ant.isi.edu/datasets/anycast/.
We have released version 1.3 of dnsanon_rssac on 2016-06-13, a tool that processes DNS data seen in packet captures (typcally pcap format) to generate RSSAC-002 statistics reports.
Our tool is at https://ant.isi.edu/software/dnsanon_rssac/index.html, with a description at
https://ant.isi.edu/software/dnsanon_rssac/README.html . Our tool builds on dnsanon.
The main goal of our implementation is that partial processing can be done independently and then merged. Merging works both for files captured at different times of the day, or at different anycast sites.
Our software stack has run at B-Root since February 2016, and since May 2016 in production use.
To our knowledge, this tool is the first to implement the RSSAC-002v3 specification.
We have released a new technical report “Do You See Me Now? Sparsity in Passive Observations of Address Liveness (extended)”, ISI-TR-2016-710, available at http://www.isi.edu/~johnh/PAPERS/Mirkovic16a.pdf
From the abstract:
Full allocation of IPv4 addresses has prompted interest in measuring address liveness, first with active probing, and recently with the addition of passive observation. While prior work has shown dramatic increases in coverage, this paper explores what factors affect contributions of passive observers to visibility. While all passive monitors are sparse, seeing only a part of the Internet, we seek to understand how different types of sparsity impact observation quality: the interests of external hosts and the hosts within the observed network, the temporal limitations on the observation duration, and coverage challenges to observe all traffic for a given target or a given vantage point. We study sparsity with inverted analysis, a new approach where we use passive monitors at four sites to infer what monitors would see at all sites exchanging traffic with those four. We show that visibility provided by monitors is heavy-tailed—interest sparsity means popular monitors see a great deal, while 99% see very little. We find that traffic is bipartite, with visibility much stronger between client-networks and server-networks than within each group. Finally, we find that popular monitors are robust to temporal and coverage sparsity, but they greatly reduce power of monitors that start with low visibility.
This technical report is joint work of Jelena Mirkovic, Genevieve Bartlett, John Heidemann, Hao Shi, and Xiyue Deng, all of USC/ISI.
We have released a new technical report “Anycast vs. DDoS: Evaluating the November 2015 Root DNS Event”, ISI-TR-2016-709, available at http://www.isi.edu/~johnh/PAPERS/Moura16a.pdf
From the abstract:
![[Moura16a] Figure 3](https://ant.isi.edu/blog/wp-content/uploads/2016/05/plot-letter-reachability-mp-scaledA.png)
Distributed Denial-of-Service (DDoS) attacks continue to be a major threat in the Internet today. DDoS attacks overwhelm target services with requests or other traffic, causing requests from legitimate users to be shut out. A common defense against DDoS is to replicate the service in multiple physical locations or sites. If all sites announce a common IP address, BGP will associate users around the Internet with a nearby site,defining the catchment of that site. Anycast addresses DDoS both by increasing capacity to the aggregate of many sites, and allowing each catchment to contain attack traffic leaving other sites unaffected. IP anycast is widely used for commercial CDNs and essential infrastructure such as DNS, but there is little evaluation of anycast under stress. This paper provides the first evaluation of several anycast services under stress with public data. Our subject is the Internet’s Root Domain Name Service, made up of 13 independently designed services (“letters”, 11 with IP anycast) running at more than 500 sites. Many of these services were stressed by sustained traffic at 100 times normal load on Nov.30 and Dec.1, 2015. We use public data for most of our analysis to examine how different services respond to the these events. We see how different anycast deployments respond to stress, and identify two policies: sites may absorb attack traffic, containing the damage but reducing service to some users, or they may withdraw routes to shift both good and bad traffic to other sites. We study how these deployments policies result in different levels of service to different users. We also show evidence of collateral damage on other services located near the attacks.
This technical report is joint work of Giovane C. M. Moura, Moritz Müller, Cristian Hesselman(SIDN Labs), Ricardo de O. Schmidt, Wouter B. de Vries (U. Twente), John Heidemann, Lan Wei (USC/ISI). Datasets in this paper are derived from RIPE Atlas and are available at http://traces.simpleweb.org/ and at https://ant.isi.edu/datasets/.
The Internet RFC-7858, “Specification for DNS over Transport Layer Security (TLS)”, was just released by the ITEF as a Standards Track document.
From the abstract:
This document describes the use of Transport Layer Security (TLS) to provide privacy for DNS. Encryption provided by TLS eliminates opportunities for eavesdropping and on-path tampering with DNS queries in the network, such as discussed in RFC 7626. In addition, this document specifies two usage profiles for DNS over TLS and provides advice on performance considerations to minimize overhead from using TCP and TLS with DNS.
This document focuses on securing stub-to-recursive traffic, as per
the charter of the DPRIVE Working Group. It does not prevent future applications of the protocol to recursive-to-authoritative traffic.
This RFC is joint work of Zhi Hu, Liang Zhu, John Heidemann, Allison Mankin, Duane Wessels, and Paul Hoffman, of USC/ISI, Verisign, ICANN, and independent (at different times). This RFC is one result of our prior paper “Connection-Oriented DNS to Improve Privacy and Security”, but also represents the input of the DPRIVE IETF working group (Warren Kumari and Tim Wicinski, chairs), where it is one of a set of RFCs designed to improve DNS privacy.
On to deployments!
We have released a new technical report “Anycast Latency: How Many Sites Are Enough?”, ISI-TR-2016-708, available at http://www.isi.edu/%7ejohnh/PAPERS/Schmidt16a.pdf.
![[Schmidt16a] figure 4: distribution of measured latency (solid lines) to optimal possible latency (dashed lines) for 4 Root DNS anycast deployments.](https://ant.isi.edu/blog/wp-content/uploads/2016/05/plot-cdf-optimal.png)
Anycast is widely used today to provide important services including naming and content, with DNS and Content Delivery Networks (CDNs). An anycast service uses multiple sites to provide high availability, capacity and redundancy, with BGP routing associating users to nearby anycast sites. Routing defines the catchment of the users that each site serves. Although prior work has studied how users associate with anycast services informally, in this paper we examine the key question how many anycast sites are needed to provide good latency, and the worst case latencies that specific deployments see. To answer this question, we must first define the optimal performance that is possible, then explore how routing, specific anycast policies, and site location affect performance. We develop a new method capable of determining optimal performance and use it to study four real-world anycast services operated by different organizations: C-, F-, K-, and L-Root, each part of the Root DNS service. We measure their performance from more than worldwide vantage points (VPs) in RIPE Atlas. (Given the VPs uneven geographic distribution, we evaluate and control for potential bias.) Key results of our study are to show that a few sites can provide performance nearly as good as many, and that geographic location and good connectivity have a far stronger effect on latency than having many nodes. We show how often users see the closest anycast site, and how strongly routing policy affects site selection.
This technical report is joint work of Ricardo de O. Schmidt and Jan Harm Kuipers (U. Twente) and John Heidemann (USC/ISI). Datasets in this paper are derived from RIPE Atlas and are available at http://traces.simpleweb.org/.
The paper “Assessing Co-Locality of IP Blocks” appeared in the 19th IEEE Global Internet Symposium on April 11, 2016 in San Francisco, CA, USA and is available at (http://www.cs.colostate.edu/~manafgh/publications/Assessing-Co-Locality-of-IP-Block-GI2016.pdf). The datasets are available at (https://ant.isi.edu/datasets/geolocation/).
From the abstract:
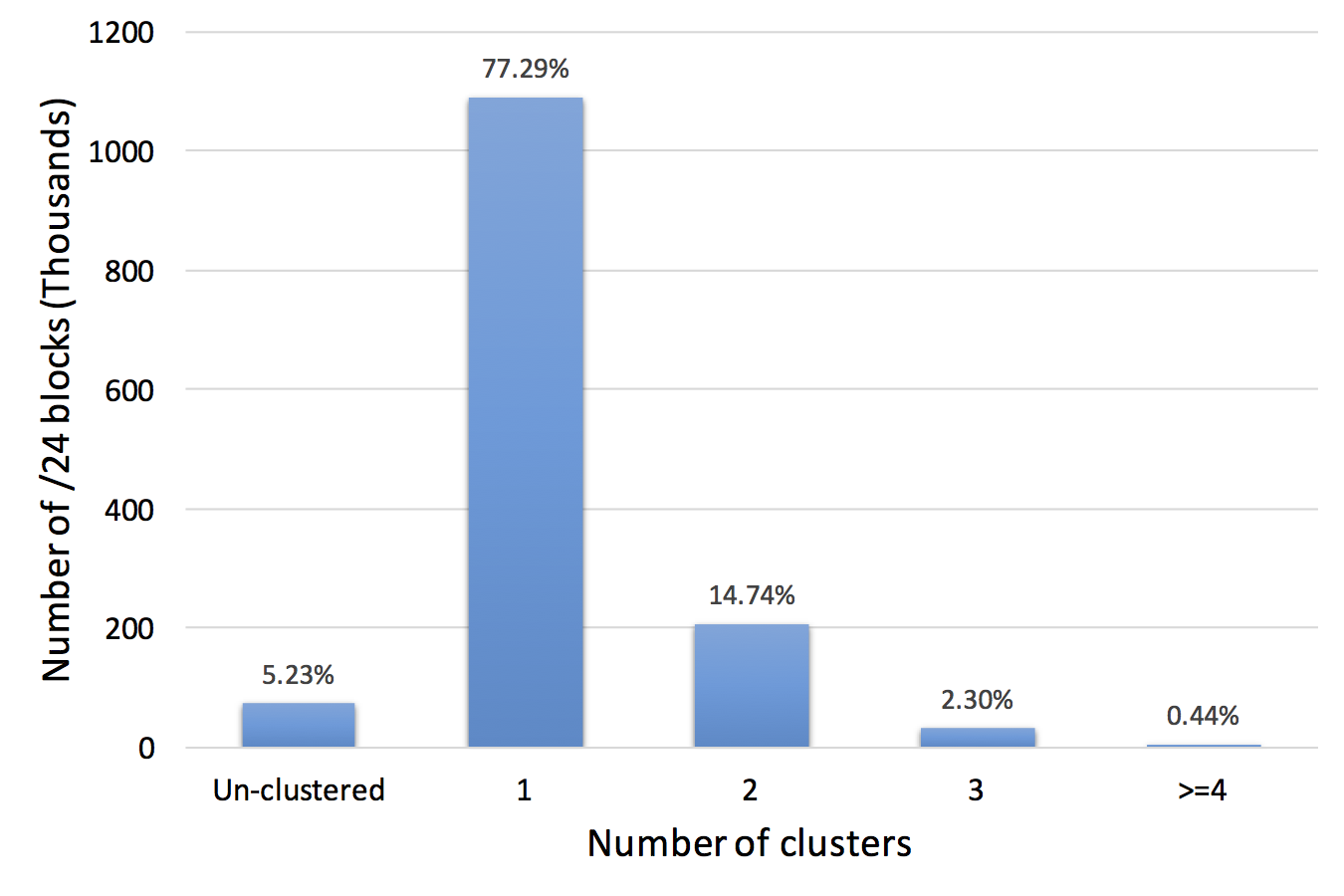 Many IP Geolocation services and applications assume that all IP addresses within the same /24 IPv4 prefix (a /24 block) reside in close physical proximity. For blocks that contain addresses in very different locations (such as blocks identifying network backbones), this assumption can result in a large geolocation error. In this paper we evaluate the co-location assumption. We first develop and validate a hierarchical clustering method to find clusters of IP addresses with similar observed delay measurements within /24 blocks. We validate our methodology against two ground-truth datasets, confirming that 93% of the identified multi-cluster blocks are true positives with multiple physical locations and an upper bound for false positives of only about 5.4%. We then apply our methodology to a large dataset of 1.41M /24 blocks extracted from a delay-measurement study of the entire responsive IPv4 address space. We find that about 247K (17%) out of 1.41M blocks are not co-located, thus quantifying the error in the /24 block co-location assumption.
Many IP Geolocation services and applications assume that all IP addresses within the same /24 IPv4 prefix (a /24 block) reside in close physical proximity. For blocks that contain addresses in very different locations (such as blocks identifying network backbones), this assumption can result in a large geolocation error. In this paper we evaluate the co-location assumption. We first develop and validate a hierarchical clustering method to find clusters of IP addresses with similar observed delay measurements within /24 blocks. We validate our methodology against two ground-truth datasets, confirming that 93% of the identified multi-cluster blocks are true positives with multiple physical locations and an upper bound for false positives of only about 5.4%. We then apply our methodology to a large dataset of 1.41M /24 blocks extracted from a delay-measurement study of the entire responsive IPv4 address space. We find that about 247K (17%) out of 1.41M blocks are not co-located, thus quantifying the error in the /24 block co-location assumption.
The work in this paper is by Manaf Gharaibeh, Han Zhang, Christos Papadopoulos (Colorado State University) and John Heidemann (USC/ISI).