We will publish a new paper “Improving Coverage of Internet Outage Detection in Sparse Blocks” by Guillermo Baltra and John Heidemann in the Passive and Active Measurement Conference (PAM 2020) in Eugene, Oregon, USA, on March 30, 2020.
From the abstract:
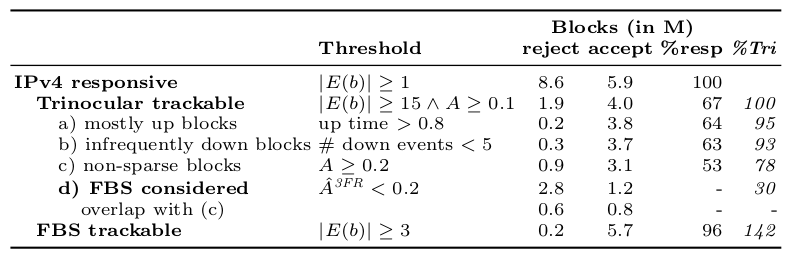
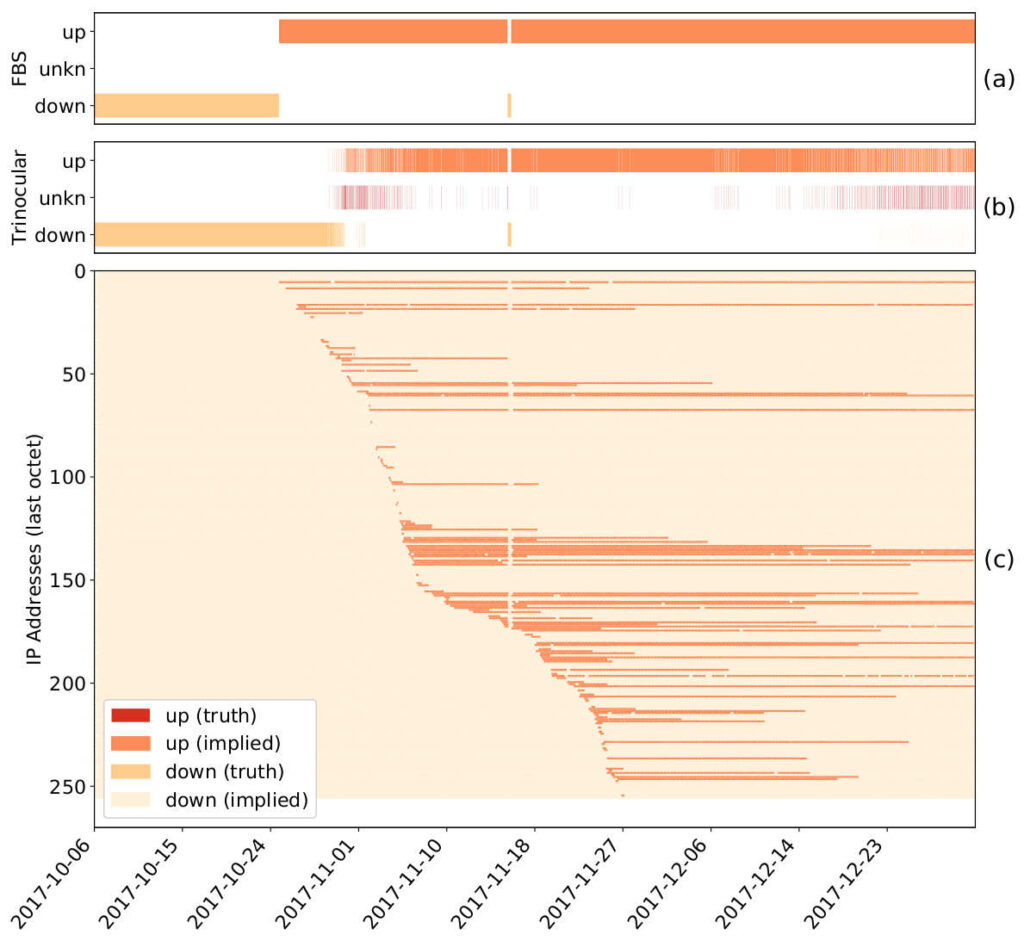
There is a growing interest in carefully observing the reliability of the Internet’s edge. Outage information can inform our understanding of Internet reliability and planning, and it can help guide operations. Active outage detection methods provide results for more than 3M blocks, and passive methods more than 2M, but both are challenged by sparse blocks where few addresses respond or send traffic. We propose a new Full Block Scanning (FBS) algorithm to improve coverage for active scanning by providing reliable results for sparse blocks by gathering more information before making a decision. FBS identifies sparse blocks and takes additional time before making decisions about their outages, thereby addressing previous concerns about false outages while preserving strict limits on probe rates. We show that FBS can improve coverage by correcting 1.2M blocks that would otherwise be too sparse to correctly report, and potentially adding 1.7M additional blocks. FBS can be applied retroactively to existing datasets to improve prior coverage and accuracy.