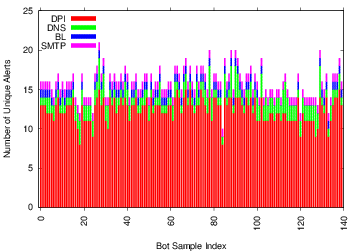
The paper “BotTalker: Generating Encrypted, Customizable C&C Traces” will appear at the 14th annual IEEE Symposium on Technologies for Homeland Security (HST ’15) in April 2015 (available at http://www.cs.colostate.edu/~zhang/papers/BotTalker.pdf)
From the abstract:
Encrypted botnets have seen an increasing
use in recent years. To enable research in detecting encrypted botnets researchers need samples of encrypted botnet traces with ground truth, which are very hard to get. Traces that are available are not customizable, which prevents testing under various controlled scenarios. To address this problem we introduce BotTalker, a tool that can be used to generate customized encrypted botnet communication traffic. BotTalker emulates the actions a bot would take to encrypt communication. It includes a highly configurable encrypted-traffic converter along with real, non- encrypted bot traces and background traffic. The converter is able to convert non-encrypted botnet traces into encrypted ones by providing customization along three dimensions: (a) selection of real encryption algorithm, (b) flow or packet level conversion, SSL emulation and (c) IP address substitution. To the best of our knowledge, BotTalk is the first work that provides users customized encrypted botnet traffic. In the paper we also apply BotTalker to evaluate the damage result from encrypted botnet traffic on a widely used botnet detection system – BotHunter and two IDS’ – Snort and Suricata. The results show that encrypted botnet traffic foils bot detection in these systems.
This work is advised by Christos Papadopoulos and supported by LACREND.