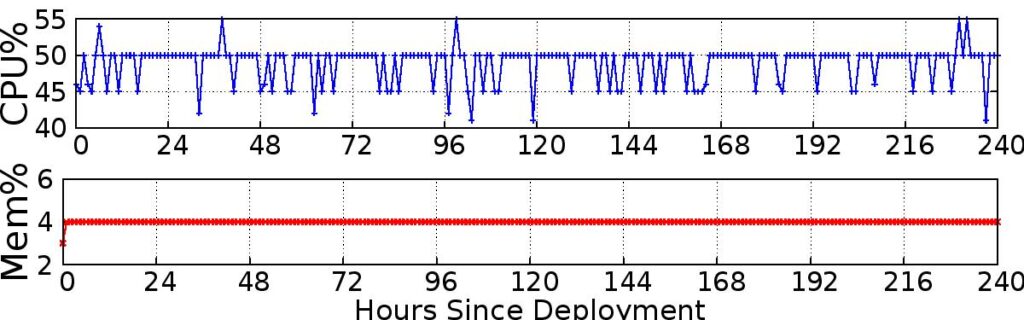
We show IoTSTEED runs well on a commodity router: memory usage is small (4% of 512MB) and the router forwards traffic at full uplink rates despite about 50% of CPU usage.
We propose IoTSTEED, a system running in edge routers to defend against Distributed Denial-of-Service (DDoS) attacks launched from compromised Internet-of-Things (IoT) devices. IoTSTEED watches traffic that leaves and enters the home network, detecting IoT devices at home, learning the benign servers they talk to, and filtering their traffic to other servers as a potential DDoS attack. We validate IoTSTEED’s accuracy and false positives (FPs) at detecting devices, learning servers and filtering traffic with replay of 10 days of benign traffic captured from an IoT access network. We show IoTSTEED correctly detects all 14 IoT and 6 non-IoT devices in this network (100% accuracy) and maintains low false-positive rates when learning the servers IoT devices talk to (flagging 2% benign servers as suspicious) and filtering IoT traffic (dropping only 0.45% benign packets). We validate IoTSTEED’s true positives (TPs) and false negatives (FNs) in filtering attack traffic with replay of real-world DDoS traffic. Our experiments show IoTSTEED mitigates all typical attacks, regardless of the attacks’ traffic types, attacking devices and victims; an intelligent adversary can design to avoid detection in a few cases, but at the cost of a weaker attack. Lastly, we deploy IoTSTEED in NAT router of an IoT access network for 10 days, showing reasonable resource usage and verifying our testbed experiments for accuracy and learning in practice.
We published a new paper “Bidirectional Anycast/Unicast Probing (BAUP): Optimizing CDN Anycast” by Lan Wei (University of Southern California/ ISI), Marcel Flores (Verizon Digital Media Services), Harkeerat Bedi (Verizon Digital Media Services), John Heidemann (University of Southern California/ ISI) at Network Traffic Measurement and Analysis Conference 2020.
From the abstract:
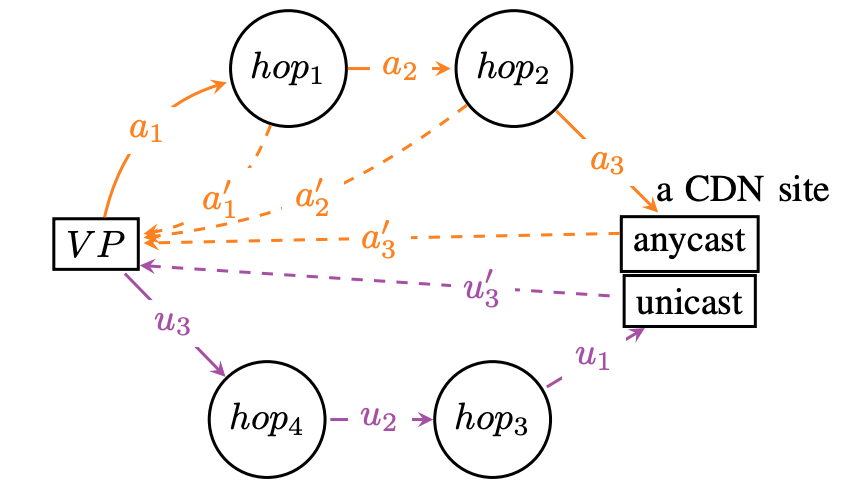
IP anycast is widely used today in Content Delivery Networks (CDNs) and for Domain Name System (DNS) to provide efficient service to clients from multiple physical points-of-presence (PoPs). Anycast depends on BGP routing to map users to PoPs, so anycast efficiency depends on both the CDN operator and the routing policies of other ISPs. Detecting and diagnosing inefficiency is challenging in this distributed environment. We propose Bidirectional Anycast/Unicast Probing (BAUP), a new approach that detects anycast routing problems by comparing anycast and unicast latencies. BAUP measures latency to help us identify problems experienced by clients, triggering traceroutes to localize the cause and suggest opportunities for improvement. Evaluating BAUP on a large, commercial CDN, we show that problems happens to 1.59% of observers, and we find multiple opportunities to improve service. Prompted by our work, the CDN changed peering policy and was able to significantly reduce latency, cutting median latency in half (40 ms to 16 ms) for regions with more than 100k users.
The data from this paper is publicly available from RIPE Atlas, please see paper reference for measurement IDs.
There is a growing interest in carefully observing the reliability of the Internet’s edge. Outage information can inform our understanding of Internet reliability and planning, and it can help guide operations. Active outage detection methods provide results for more than 3M blocks, and passive methods more than 2M, but both are challenged by sparse blocks where few addresses respond or send traffic. We propose a new Full Block Scanning (FBS) algorithm to improve coverage for active scanning by providing reliable results for sparse blocks by gathering more information before making a decision. FBS identifies sparse blocks and takes additional time before making decisions about their outages, thereby addressing previous concerns about false outages while preserving strict limits on probe rates. We show that FBS can improve coverage by correcting 1.2M blocks that would otherwise be too sparse to correctly report, and potentially adding 1.7M additional blocks. FBS can be applied retroactively to existing datasets to improve prior coverage and accuracy.
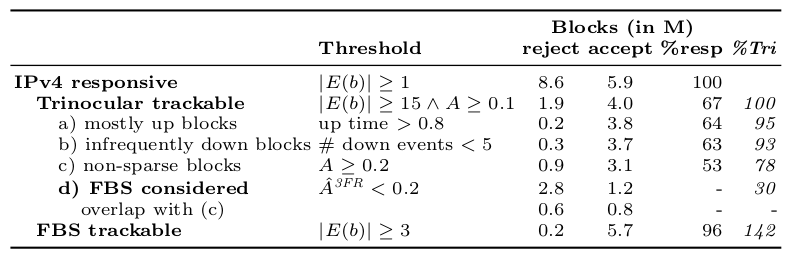
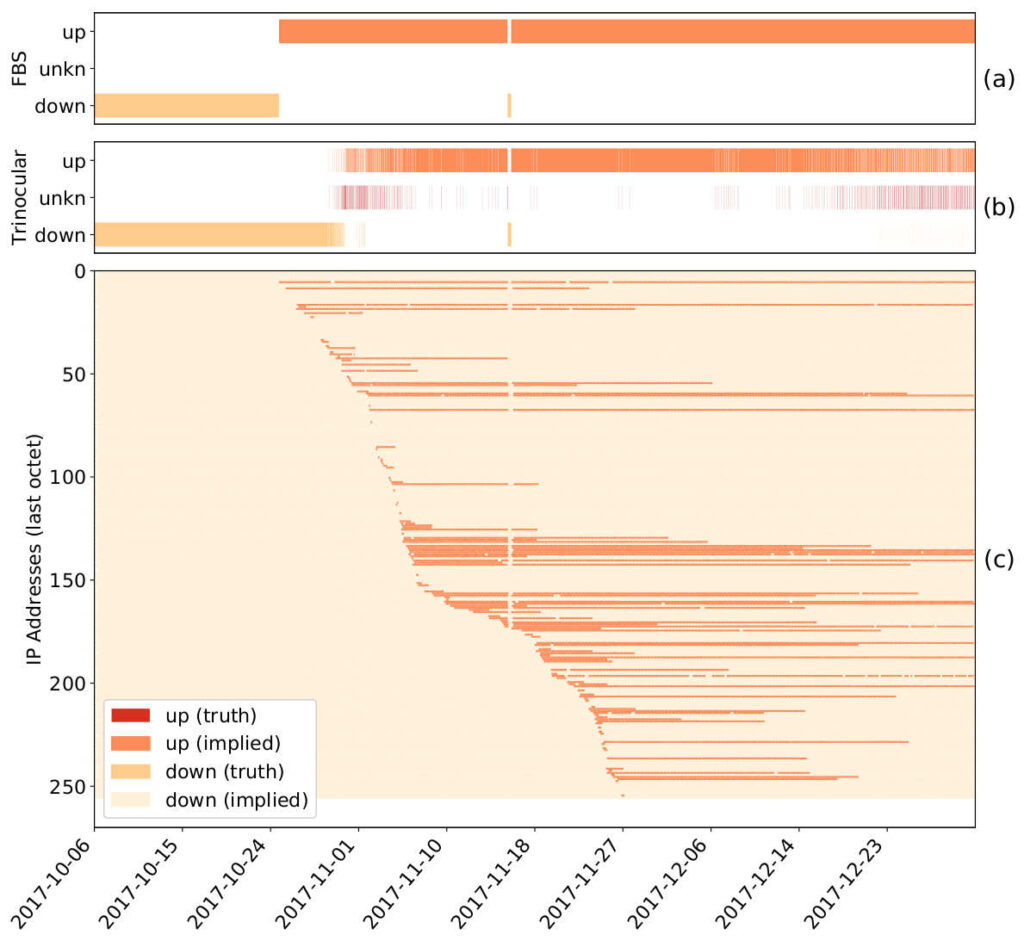
This paper defines two algorithms: Full Block Scanning (FBS), to address false outages seen in active measurements of sparse blocks, and Lone Address Block Recovery (LABR), to handle blocks with one or two responsive addresses. We show that these algorithms increase coverage, from a nominal 67% (and as low as 53% after filtering) of responsive blocks before to 5.7M blocks, 96% of responsive blocks.
We have released a new technical report “Peek Inside the Closed World: Evaluating Autoencoder-Based Detection of DDoS to Cloud” as an ArXiv technical report 1912.05590, also available from our website (updated 2025; prior link was: https://www.isi.edu/~hangguo/papers/Guo19a.pdf)
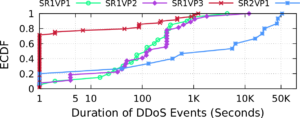
We study 4 cloud IPs (SR1VP1 to 3 and SR2VP1) that are under attack. SR1VP3 sees a large number of mostly short DDoS events (71% of its 49 events being 1 second or less). SR1VP1 and SR1VP2 see smaller numbers of longer DDoS events (median duration for their 20 and 27 events are 121 and 140 seconds). SR2VP1 sees DDoS events of broad range of durations (from 1 second to more than 14 hours).
From the abstract of our technical report:
From the abstract:
Machine-learning-based anomaly detection (ML-based AD) has been successful at detecting DDoS events in the lab. However published evaluations of ML-based AD have only had limited data and have not provided insight into why it works. To address limited evaluation against real-world data, we apply autoencoder, an existing ML-AD model, to 57 DDoS attack events captured at 5 cloud IPs from a major cloud provider. To improve our understanding for why ML-based AD works or not works, we interpret this data with feature attribution and counterfactual explanation. We show that our version of autoencoders work well overall: our models capture nearly all malicious flows to 2 of the 4 cloud IPs under attacks (at least 99.99%) but generate a few false negatives (5% and 9%) for the remaining 2 IPs. We show that our models maintain near-zero false positives on benign flows to all 5 IPs. Our interpretation of results shows that our models identify almost all malicious flows with non-whitelisted (non-WL) destination ports (99.92%) by learning the full list of benign destination ports from training data (the normality). Interpretation shows that although our models learn incomplete normality for protocols and source ports, they still identify most malicious flows with non-WL protocols and blacklisted (BL) source ports (100.0% and 97.5%) but risk false positives. Interpretation also shows that our models only detect a few malicious flows with BL packet sizes (8.5%) by incorrectly inferring these BL sizes as normal based on incomplete normality learned. We find our models still detect a quarter of flows (24.7%) with abnormal payload contents even when they do not see payload by combining anomalies from multiple flow features. Lastly, we summarize the implications of what we learn on applying autoencoder-based AD in production.problme?Machine-learning-based anomaly detection (ML-based AD) has been successful at detecting DDoS events in the lab. However published evaluations of ML-based AD have only had limited data and have not provided insight into why it works. To address limited evaluation against real-world data, we apply autoencoder, an existing ML-AD model, to 57 DDoS attack events captured at 5 cloud IPs from a major cloud provider. To improve our understanding for why ML-based AD works or not works, we interpret this data with feature attribution and counterfactual explanation. We show that our version of autoencoders work well overall: our models capture nearly all malicious flows to 2 of the 4 cloud IPs under attacks (at least 99.99%) but generate a few false negatives (5% and 9%) for the remaining 2 IPs. We show that our models maintain near-zero false positives on benign flows to all 5 IPs. Our interpretation of results shows that our models identify almost all malicious flows with non-whitelisted (non-WL) destination ports (99.92%) by learning the full list of benign destination ports from training data (the normality). Interpretation shows that although our models learn incomplete normality for protocols and source ports, they still identify most malicious flows with non-WL protocols and blacklisted (BL) source ports (100.0% and 97.5%) but risk false positives. Interpretation also shows that our models only detect a few malicious flows with BL packet sizes (8.5%) by incorrectly inferring these BL sizes as normal based on incomplete normality learned. We find our models still detect a quarter of flows (24.7%) with abnormal payload contents even when they do not see payload by combining anomalies from multiple flow features. Lastly, we summarize the implications of what we learn on applying autoencoder-based AD in production.
This technical report is joint work of Hang Guo and John Heidemann from USC/ISI and Xun Fan, Anh Cao and Geoff Outhred from Microsoft
[Bogutz19a, figure 1]: Our sideboard showing important outages on 2019-03-08, including this outage in Venezuela.
Today, outage detection systems can track outages across the whole IPv4 Internet—millions of networks. However, it becomes difficult to find meaningful, interesting events in this huge dataset, since three months of data can easily include 660M observations and thousands of outage events. We propose an outage reporting system that sifts through this data to find the most interesting events. We explore multiple metrics to evaluate interesting”, reflecting the size and severity of outages. We show that defining interest as the product of size by severity works well, avoiding degenerate cases like complete outages affecting a few people, and apparently large outages that affect only a small fraction of people in an area. We have integrated outage reporting into our existing public website (https://outage.ant.isi.edu) with the goal of making near-real-time outage information accessible to the general public. Such data can help answer questions like “what are the most significant outages today?”, did Florida have major problems in an ongoing hurricane?”, and “are there power outages in Venezuela?”.
The data from this paper is available publicly and in our website. The technical report ISI-TR-735 includes some additional data.
We have released a new technical report “Improving the Optics of the Active Outage Detection (extended)”, by Guillermo Baltra and John Heidemann, as ISI-TR-733.
From the abstract:
A sample block showing changes in block usage (c), and outage detection results of Trinocular (b) and improved with the Full Block Scanning Algorithm (a).
There is a growing interest in carefully observing the reliability of the Internet’s edge. Outage information can inform our understanding of Internet reliability and planning, and it can help guide operations. Outage detection algorithms using active probing from third parties have been shown to be accurate for most of the Internet, but inaccurate for blocks that are sparsely occupied. Our contributions include a definition of outages, which we use to determine how many independent observers are required to determine global outages. We propose a new Full Block Scanning (FBS) algorithm that gathers more information for sparse blocks to reduce false outage reports. We also propose ISP Availability Sensing (IAS) to detect maintenance activity using only external information. We study a year of outage data and show that FBS has a True Positive Rate of 86%, and show that IAS detects maintenance events in a large U.S. ISP.
All data from this paper will be publicly available.
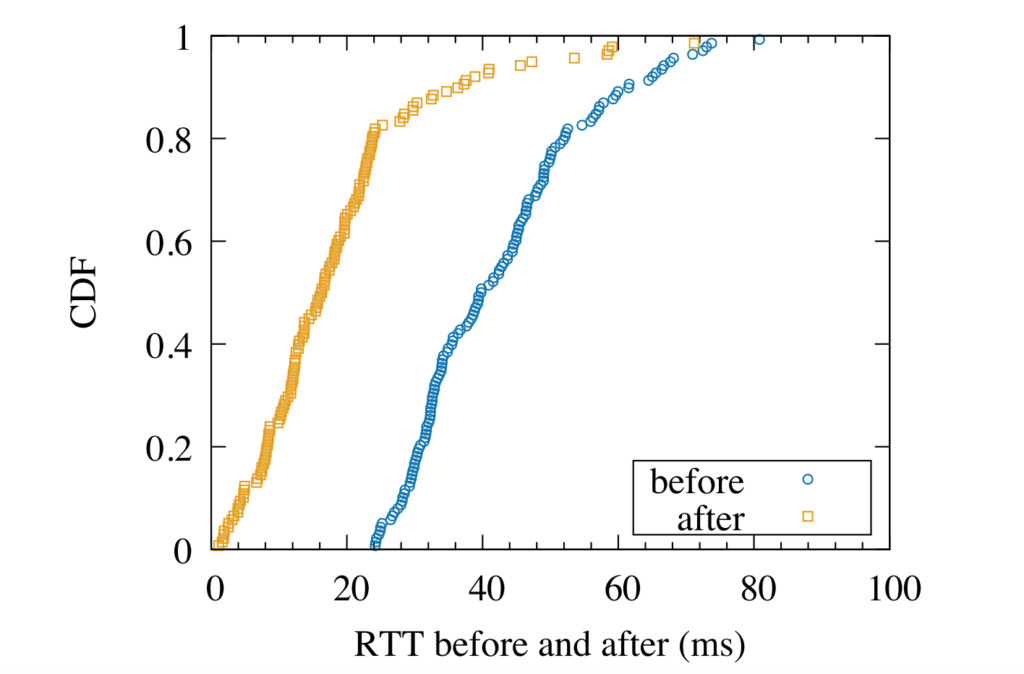
Figure 10a from [Moura19b], showing the distribution of latency with small TTLs before (right in blue) and with larger TTLs after (left in red) the .uy domain reviewed our work and lengthened their domain’s cache lifetimes to reduce latency to their customers.
DNS depends on extensive caching for good performance, and every DNS zone owner must set Time-to-Live (TTL) values to control their DNS caching. Today there is relatively little guidance backed by research about how to set TTLs, and operators must balance conflicting demands of caching against agility of configuration. Exactly how TTL value choices affect operational networks is quite challenging to understand due to interactions across the distributed DNS service, where resolvers receive TTLs in different ways (answers and hints), TTLs are specified in multiple places (zones and their parent’s glue), and while DNS resolution must be security-aware. This paper provides the first careful evaluation of how these multiple, interacting factors affect the effective cache lifetimes of DNS records, and provides recommendations for how to configure DNS TTLs based on our findings. We provide recommendations in TTL choice for different situations, and for where they must be configured. We show that longer TTLs have significant promise in reducing latency, reducing it from 183ms to 28.7ms for one country-code TLD.
We have also reported on this work at the RIPE and APNIC blogs.
We released a new technical report “Plumb: Efficient Processing of Multi-User Pipelines (Poster)”, by Abdul Qadeer and John Heidemann, as ISI-TR-731. This work was originally presented at ACM Symposium on Cloud Computing (the poster abstract is available at ACM). The poster abstract with a small version of the poster is available at https://www.isi.edu/publications/trpublic/pdfs/isi-tr-731.pdf
aqadeer at SoCC 2018 Carlsbad CA
From the abstract:
As the field of big data analytics matures, workflows are increasingly complex and often include components that are shared by different users. Individual workflows often include multiple stages, and when groups build on each other’s work it is easy to lose track of computation that may be shared across different groups.
The contribution of this poster is to provide an organization-wide processing substrate Plumb that can be used to solve commonly occurring problems and to achieve a common goal. Plumb makes multi-user sharing a first-class concern by providing pipeline-graph abstraction. This abstraction is simple and based on fundamental model of input-processing-output but is powerful to capture processing and data duplication. Plumb then employs best available solutions to tackle problems of large-block processing under structural and computational skew without user intervention.
We expect to release the Plumb software this fall; please contact us if you have questions or interest in using it.
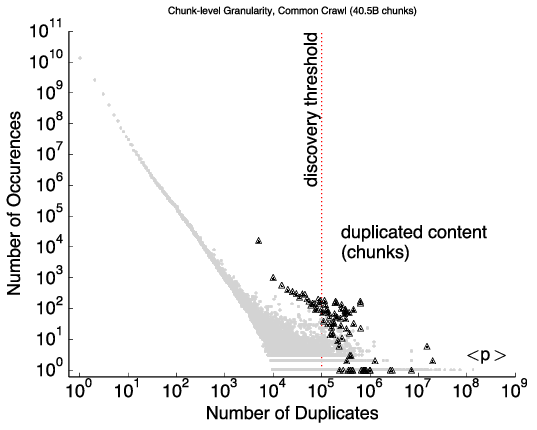
With vast amount of content online, it is not surprising that unscrupulous entities “borrow” from the web to provide content for advertisements, link farms, and spam. Our insight is that cryptographic hashing and fingerprinting can efficiently identify content reuse for web-size corpora. We develop two related algorithms, one to automatically discover previously unknown duplicate content in the web, and the second to precisely detect copies of discovered or manually identified content. We show that bad neighborhoods, clusters of pages where copied content is frequent, help identify copying in the web. We verify our algorithm and its choices with controlled experiments over three web datasets: Common Crawl (2009/10), GeoCities (1990s–2000s), and a phishing corpus (2014). We show that our use of cryptographic hashing is much more precise than alternatives such as locality-sensitive hashing, avoiding the thousands of false-positives that would otherwise occur. We apply our approach in three systems: discovering and detecting duplicated content in the web, searching explicitly for copies of Wikipedia in the web, and detecting phishing sites in a web browser. We show that general copying in the web is often benign (for example, templates), but 6–11% are commercial or possibly commercial. Most copies of Wikipedia (86%) are commercialized (link farming or advertisements). For phishing, we focus on PayPal, detecting 59% of PayPal-phish even without taking on intentional cloaking.
DNS backscatter from IPv4 and IPv6 ([Fukuda18a], figure 1).From the abstract:
DNS backscatter detects internet-wide activity by looking for common reverse DNS lookups at authoritative DNS servers that are high in the DNS hierarchy. Both DNS backscatter and monitoring unused address space (darknets or network telescopes) can detect scanning in IPv4, but with IPv6’s vastly larger address space, darknets become much less effective. This paper shows how to adapt DNS backscatter to IPv6. IPv6 requires new classification rules, but these reveal large network services, from cloud providers and CDNs to specific services such as NTP and mail. DNS backscatter also identifies router interfaces suggesting traceroute-based topology studies. We identify 16 scanners per week from DNS backscatter using observations from the B-root DNS server, with confirmation from backbone traffic observations or blacklists. After eliminating benign services, we classify another 95 originators in DNS backscatter as potential abuse. Our work also confirms that IPv6 appears to be less carefully monitored than IPv4.