We released a new technical report “Web-scale Content Reuse Detection (extended)”, ISI-TR-2014-692, available at http://www.isi.edu/publications/trpublic/files/tr-692.pdf.
From the abstract:
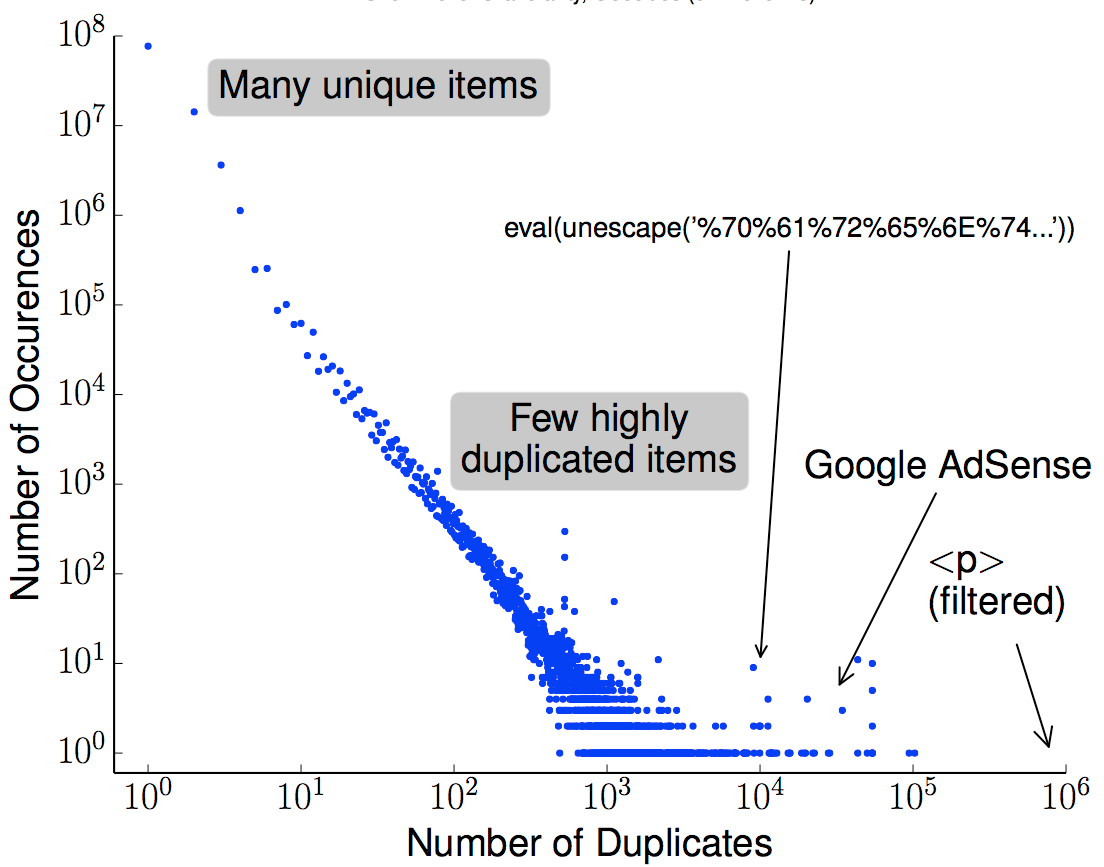
With the vast amount of accessible, online content, it is not surprising that unscrupulous entities “borrow” from the web to provide filler for advertisements, link farms, and spam and make a quick profit. Our insight is that cryptographic hashing and fingerprinting can efficiently identify content reuse for web-size corpora. We develop two related algorithms, one to automatically discover previously unknown duplicate content in the web, and the second to detect copies of discovered or manually identified content in the web. Our detection can also bad neighborhoods, clusters of pages where copied content is frequent. We verify our approach with controlled experiments with two large datasets: a Common Crawl subset the web, and a copy of Geocities, an older set of user-provided web content. We then demonstrate that we can discover otherwise unknown examples of duplication for spam, and detect both discovered and expert-identified content in these large datasets. Utilizing an original copy of Wikipedia as identified content, we find 40 sites that reuse this content, 86% for commercial benefit.