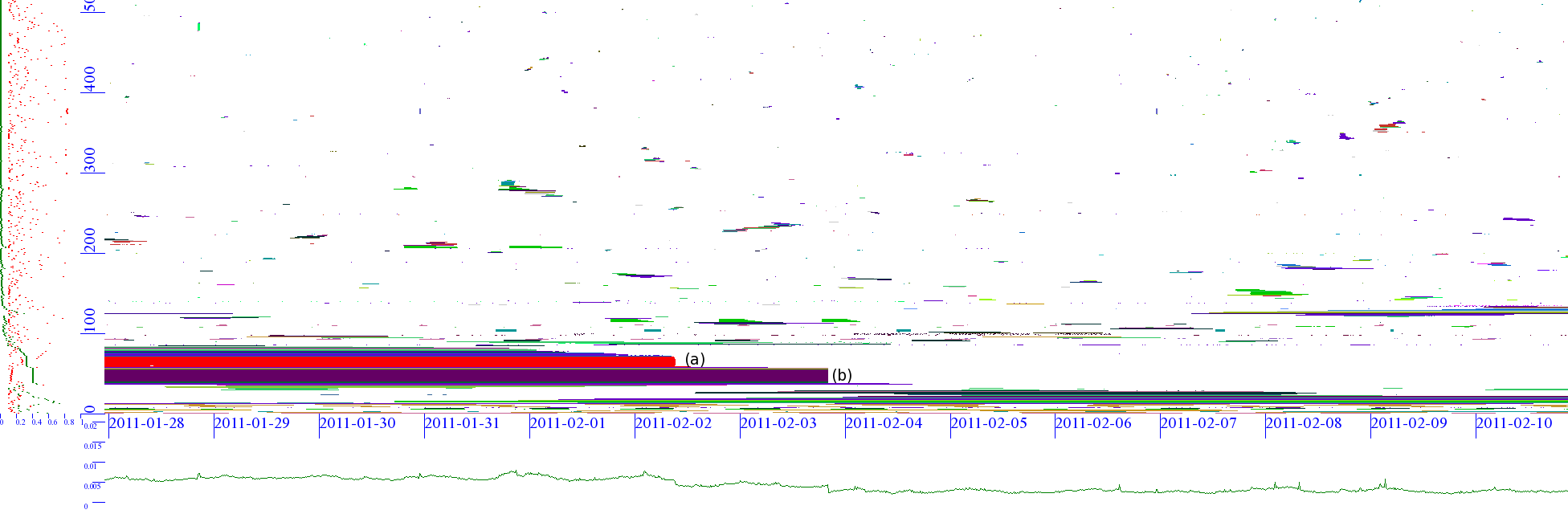
On 2012-02-23, hardware problems in an Australian ISP (Dodo) router caused it to announce many global routes to their ISP (Telstra), and from there to others.
The result: for 45 minutes, millions of Australians lost international Internet connectivity.
While this problem was detected and corrected in less than an hour, this kind of problem can reoccur.
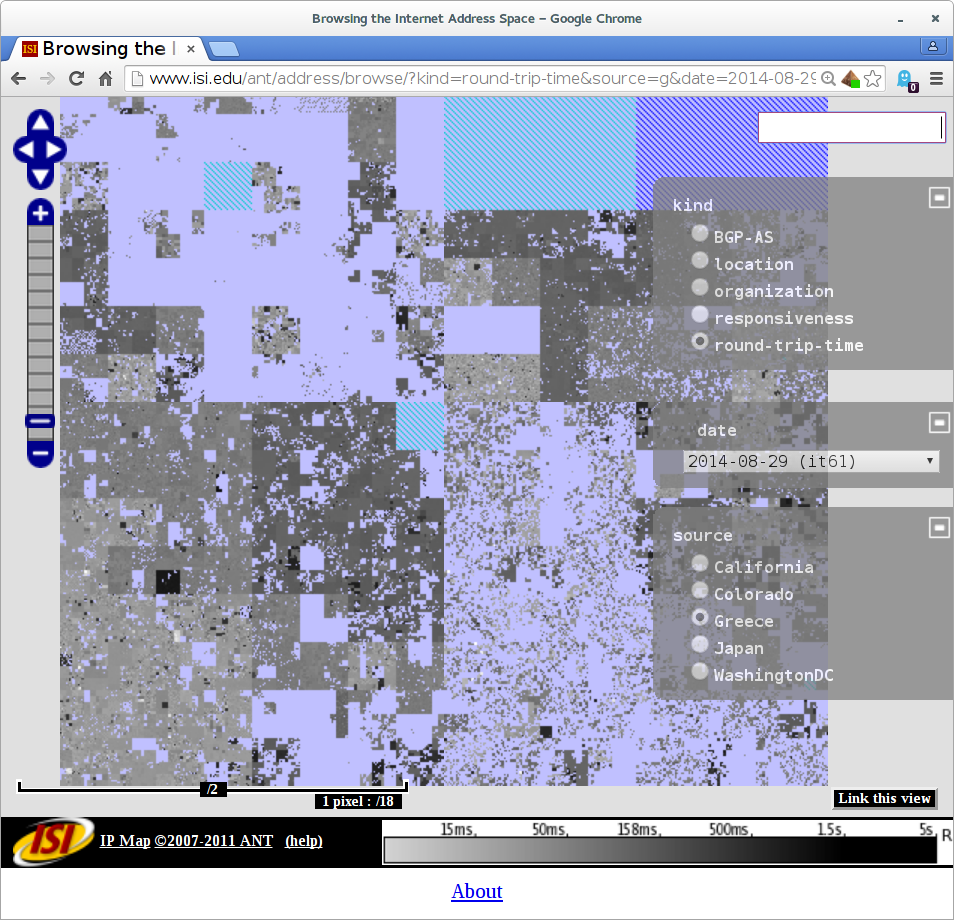
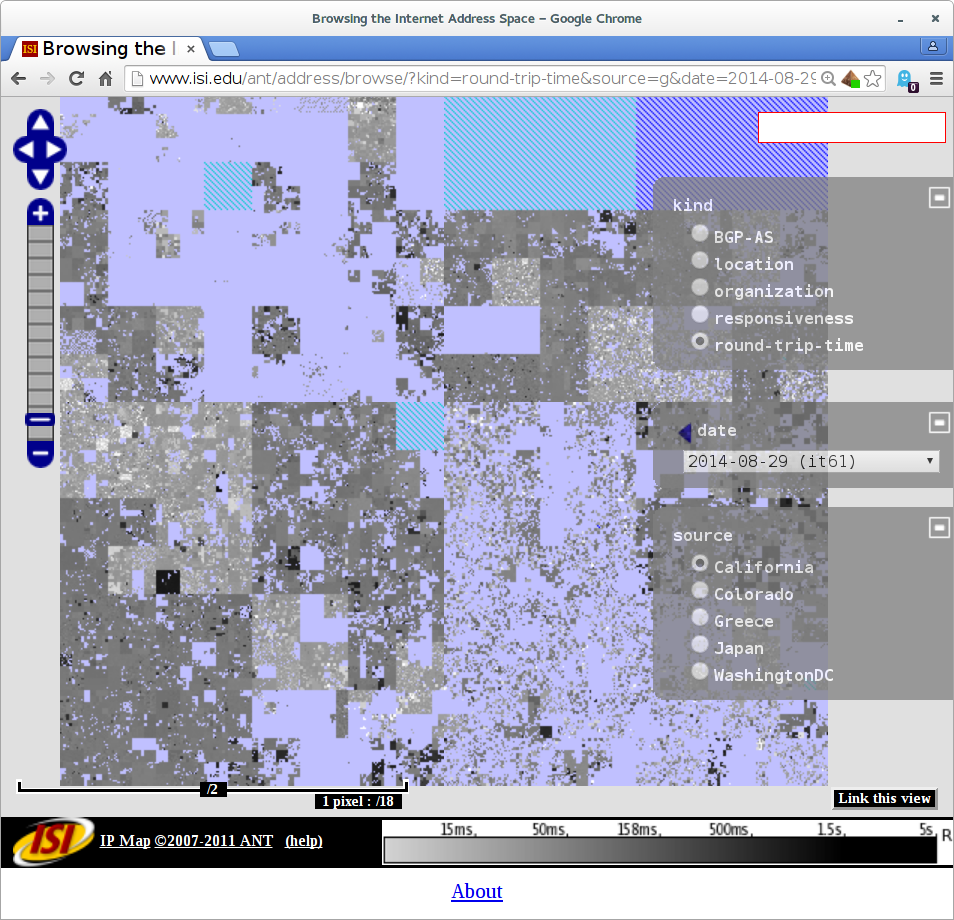
In this video we show the Internet address space (IPv4) from Sydney, Australia. Colors show estimated physical location (blue: North America, Red: Europe, Green: Asia). Addresses map to a Hilbert Curve, and nearby addresses form squares. White boxes show routing changes, with bursts after 02:40 UTC.
In the visualization we see there are many, many routing changes for much of Internet (the many white boxes)–evidence of routing instability in Sydney.
A copy of this video is also available at Vimeo (some system may have problems viewing the above embedded video, but Vimeo is a good alternative).
This video was made by Kaustubh Gadkari, John Heidemann, Cathie Olschanowsky, Christos Papadopoulos, Yuri Pradkin, and Lawrence Weikum at University of Southern California/Information Sciences Institute (USC/ISI) and Colorado State University/Computer Science (CSU).
This video uses software developed at USC/ISI and CSU: Retro-future Time Travel, the LANDER IPv4 Web Address Browser, and BGPMon, the BGP logging and monitor. Data from this video is available from BGPMon and PREDICT (or the authors).
This work was supported by DHS S&T (BGPMon, contract N66001-08-C-2028; LANDER, contract D08PC75599, admin. by SPAWAR; LACREND, contract FA8750-12-2-0344, admin. by AFRL; Retro-future, contract N66001-13-C-3001, admin. by SPAWAR), and NSF/CISE (BGPMon, grant CNS-1305404). Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of funding and administrative agencies.