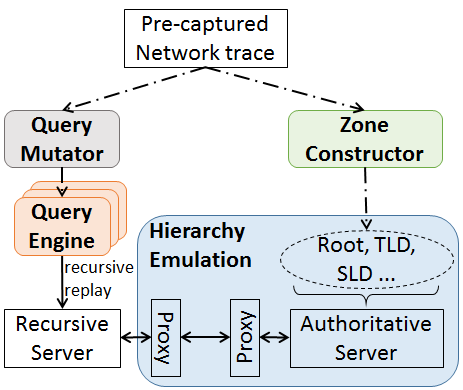
We have published a new paper “Leveraging Controlled Information Sharing for Botnet Activity Detection” in the Workshop on Traffic Measurements for Cybersecurity (WTMC 2018) in Budapest, Hungary, co-located with ACM SIGCOMM 2018.
From the abstract of our paper:
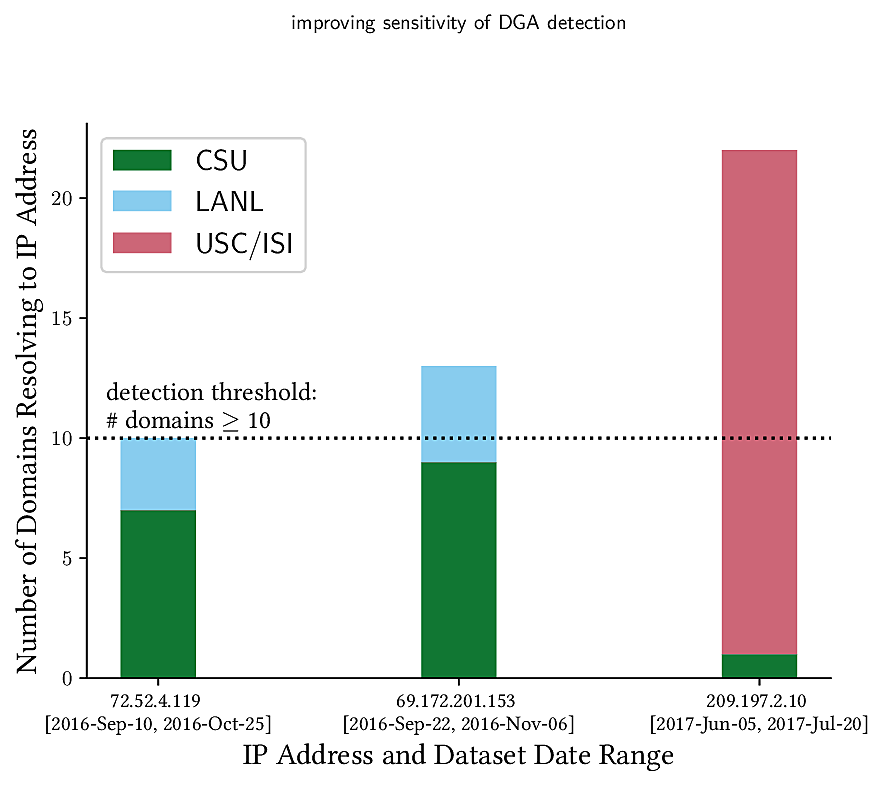
Today’s malware often relies on DNS to enable communication with command-and-control (C&C). As defenses that block traffic improve, malware use sophisticated techniques to hide this traffic, including “fast flux” names and Domain-Generation Algorithms (DGAs). Detecting this kind of activity requires analysis of DNS queries in network traffic, yet these signals are sparse. As bot countermeasures grow in sophistication, detecting these signals increasingly requires the synthesis of information from multiple sites. Yet *sharing security information across organizational boundaries* to date has been infrequent and ad hoc because of unknown risks and uncertain benefits. In this paper, we take steps towards formalizing cross-site information sharing and quantifying the benefits of data sharing. We use a case study on DGA-based botnet detection to evaluate how sharing cybersecurity data can improve detection sensitivity and allow the discovery of malicious activity with greater precision.
The relevant software is open-sourced and freely available at https://ant.isi.edu/retrofuture.
This paper is joint work between Calvin Ardi and John Heidemann from USC/ISI, with additional support from collaborators and Colorado State University and Los Alamos National Laboratory.