New network measurements are great–you can learn about the whole world! But new network measurements are horrible–are you sure you learn about the world, and not about bugs in your code or approach? New scientific approaches must be tested and ultimately calibrated against ground truth. Yet ground truth about the Internet can be quite difficult—often network operators themselves do not know all the details of their network. This talk will explore the role of ground truth in network measurement: getting it when you can, alternatives when it’s imperfect, and what we learn when none is available.
This talk builds on research over the last decade with many people, and the slides include some discussion from the TMA PhD school audience.
Emulating the DNS hierarchy both efficiently and correctly.
The DNS ecosystem today is revisiting basic design questions: should it encourage TCP? TLS? DTLS? Something completely new like QUIC or HTTP? While modeling and analysis help answer some of these questions, experimental evaluation is necessary for validation, and in some cases the only way to get accurate estimates of software memory use and performance. This talk will discuss our recent work in supporting experimental evaluation of DNS with components that support trace replay and evaluation. Trace replay is supported by a DNS data archive to prime replay with real data, and a query mutation system to support what-if evaluation using variations of that data.
The trace replay system is the work with Liang Zhu; this work is part of a larger system to support DNS experimentation, joint work with Wes Hardaker.
Unmeasurable blocks over time, a challenge in long-haul outage measurement, from [Alwabel15a]We have been collecting data about outages in the Internet since Oct. 2014. Our outage detection system, Trinocular, uses active probing from four sites to study about 4 million /24 IPv4 address blocks. Long-duration measurements bring challenges that don’t occur in short observations. Most importantly, our target (“the Internet”) changes as we measure it, as new blocks come on-line, old blocks are reused in different ways, and ISPs observe and sometimes block our traffic. Our measurement platform also sees occasional hardware failures. Visualization can assist detection of these problems, allowing human perception to detect changes in data collection that have not previously been anticipated. This talk will discuss the challenges of long-term outage measurement and describe our new algorithm that scales to support clustering of 4M blocks and 3 months of observations for visualization.
Our visualization is joint work with Yuri Pradkin, and analysis of our long-term outages includes work with Abdulla Alwabel.
John Heidemann gave the talk “DNS Privacy, Service Management, and Research: Friends or Foes” at the NDSS DNS Privacy Workshop in San Diego, California, USA on Feburary 26, 2017. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann17a.pdf.
The talk does not have a formal abstract, but to summarize:
A slide from the [Heidemann17a] talk, looking at what different DNS stakeholders may want.
This invited talk is part of a panel on the tension between DNS privacy and service management. In the talk I expand on that topic and discuss
the tension between DNS privacy, service management, and research.
I give suggestions about how service management and research can adapt to proceed while still providing basic privacy.
Distributed Denial-of-Service attacks are continuing threat to the Internet. Meeting this threat requires new approaches that will emerge from new research, but new research requires the support of dataset and experimental methods. This talk describes four different aspects of research on DDoS, privacy and security, and the datasets that have generated to support that research. Areas we consider are detecting low rate DDoS attacks, understanding the effects of DDoS on DNS infrastructure, evolving the DNS protocol to prevent DDoS and improve privacy, and ideas about experimental testbeds to evaluate new ideas in DDoS defense for DNS. Datasets described in this talk are available at no cost from the author and through the IMPACT Program.
This talk is based on the work with many prior collaborators: Terry Benzel, Wes Hardaker, Christian Hessleman, Zi Hu, Allison Mainkin, Urbashi Mitra, Giovane Moura, Moritz Müller, Ricardo de O. Schmidt, Nikita Somaiya, Gautam Thatte, Wouter de Vries, Lan Wei, Duane Wessels, Liang Zhu.
Possible outcomes of anycast under stress, a slide from a talk about the Nov. 30, 2015 Root DNS event.
From the abstract:
Distributed Denial-of-Service (DDoS) attacks continue to be a major threat in the Internet today. DDoS attacks overwhelm target services with requests or other “bogus” traffic, causing requests from legitimate users to be shut out. A common defense against DDoS is to replicate the service in multiple physical locations or sites. If all sites announce a common IP address, BGP will associate users around the Internet with a nearby site, defining the catchment of that site. Anycast adds resilience against DDoS both by increasing capacity to the aggregate of many sites, and allowing each catchment to contain attack traffic leaving other sites unaffected. IP anycast is widely used for commercial CDNs and essential infrastructure such as DNS, but there is little evaluation of anycast under stress.
This talk will provide a first evaluation of several anycast services under stress with public data. Our subject is the Internet’s Root Domain Name Service, made up of 13 independently designed services (“letters”, 11 with IP anycast) running at more than 500 sites. Many of these services were stressed by sustained traffic at 100x normal load on Nov. 30 and Dec. 1, 2015. We use public data for most of our analysis to examine how different services respond to the these events. In our analysis we identify two policies by operators: (1) sites may absorb attack traffic, containing the damage but reducing service to some users, or (2) they may withdraw routes to shift both legitimate and bogus traffic to other sites. We study how these deployment policies result in different levels of service to different users, during and immediately after the attacks.
We also show evidence of collateral damage on other services located near the attack targets. The work is based on analysis of DNS response from around 9000 RIPE Atlas vantage points (or “probes”), agumented by RSSAC-002 reports from 5 root letters and BGP data from BGPmon. We examine DNS performance for each Root Letter, for anycast sites inside specific letters, and for specific servers at one site.
Comparing actual (obtained) anycast latency against optimal possible anycast latency, for 4 different anycast deployments (each a Root Letter). From the talk [Heidemann16b], based on data from [Moura16b].From the abstract:
This talk will evaluate anycast latency. An anycast service uses multiple sites to provide high availability, capacity and redundancy, with BGP routing associating users to nearby anycast sites. Routing defines the catchment of the users that each site serves. Although prior work has studied how users associate with anycast services informally, in this paper we examine the key question how many anycast sites are needed to provide good latency, and the worst case latencies that specific deployments see. To answer this question, we must first define the optimal performance that is possible, then explore how routing, specific anycast policies, and site location affect performance. We develop a new method capable of determining optimal performance and use it to study four real-world anycast services operated by different organizations: C-, F-, K-, and L-Root, each part of the Root DNS service. We measure their performance from more than worldwide vantage points (VPs) in RIPE Atlas. (Given the VPs uneven geographic distribution, we evaluate and control for potential bias.) Key results of our study are to show that a few sites can provide performance nearly as good as many, and that geographic location and good connectivity have a far stronger effect on latency than having many nodes. We show how often users see the closest anycast site, and how strongly routing policy affects site selection.
John Heidemann gave the talk “New Opportunities for Research and Experiments in Internet Naming And Identification” at the AIMS 2016 workshop at CAIDA, La Jolla, California on February 11, 2016. Slides are available at http://www.isi.edu/~johnh/PAPERS/Heidemann16a.pdf.
Needs for new naming and identity research prompt new research infrastructure, enabling new research directions.
From the abstract:
DNS is central to Internet use today, yet research on DNS today is challenging: many researchers find it challenging to create realistic experiments at scale and representative of the large installed base, and datasets are often short (two days or less) or otherwise limited. Yes DNS evolution presses on: improvements to privacy are needed, and extensions like DANE provide an opportunity for DNS to improve security and support identity management. We exploring how to grow the research community and enable meaningful work on Internet naming. In this talk we will propose new research infrastructure to support to realistic DNS experiments and longitudinal data studies. We are looking for feedback on our proposed approaches and input about your pressing research problems in Internet naming and identification.
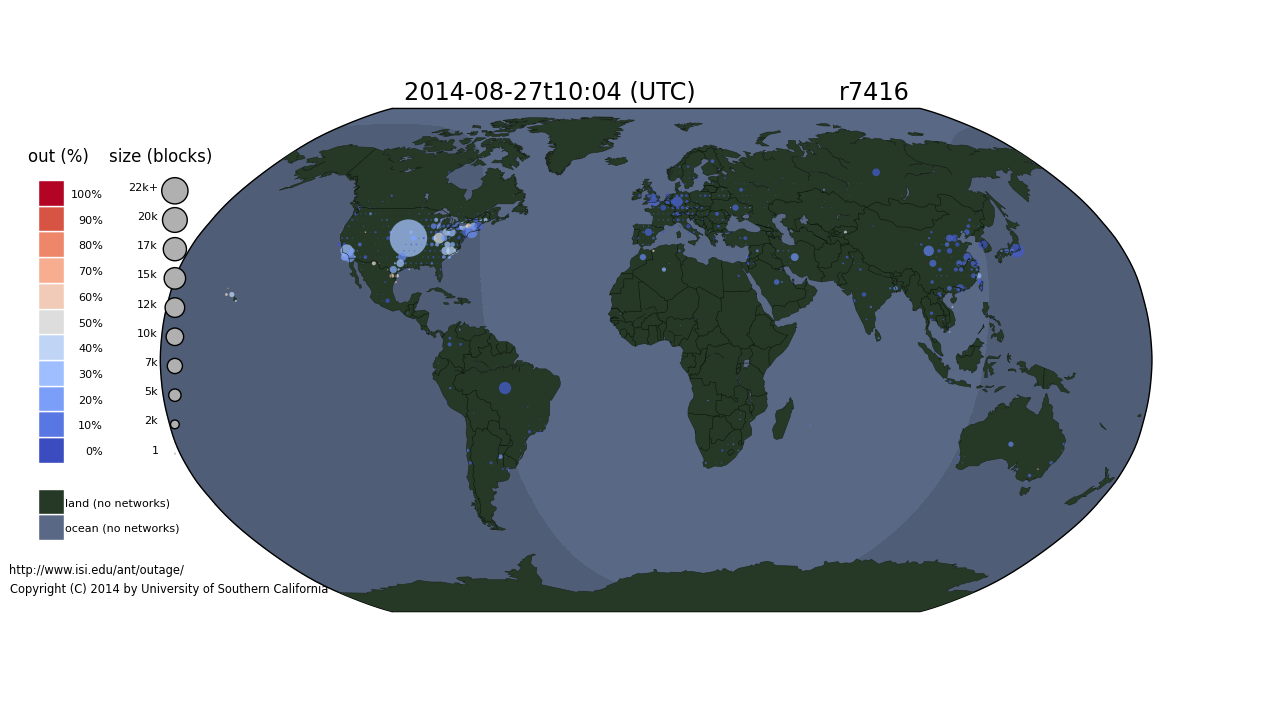
Global network outages on 2014-08-27 during the Time Warner event in the U.S.
On August 27, 2014, Time Warner suffered a network outage that affected about 11 million customers for more than two hours (makingnationalnews). We have observing global network outages since December 2013, including this outage.
We see that the Time Warner outage lasted about two hours and affected a good swath of the United States. We caution that all large network operators have occasional outages–this animation is not intended to complain about Time Warner, but to illustrate the need to have tools that can detect and visualize national-level outages. It also puts the outage into context: we can see a few other outages in Uruguay, Brazil, and Saudi Arabia.
This analysis uses dataset usc-lander /internet_outage_adaptive_a17all-20140701, available for research use from PREDICT, or by request from us if PREDICT access is not possible.
This animation was first shown at the Dec. 2014 DHS Cyber Security Division R&D Showcase and Technical Workshop as part of the talk “Towards Understanding Internet Reliability” given by John Heidemann. This work was supported by DHS, most recently through the LACREND project.
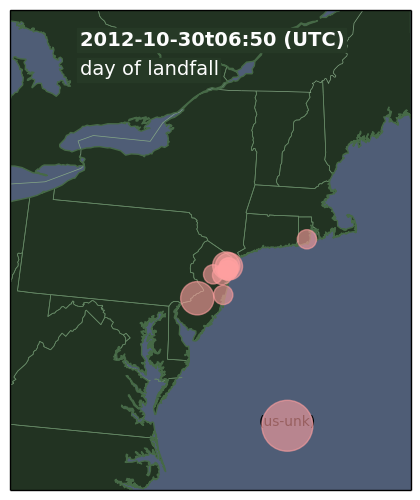
In October 2012, Hurricane Sandy made landfall on the U.S. East Coast causing widespread power outages. We were able to see the effects of Hurricane Sandy by analyzing active probing of the Internet. We first reported this work in a technical report and then with more refined analysis in a peer-reviewed paper.
Network outages for a sample of U.s. East Coast networks on the day after Hurricane Sandy made landfall.
These 4 days before landfall and 7 after show some intersting results: On the day of landfall we see about three-times the number of outages relative to “typical” U.S. networks. Finally, we see it takes about four days to recover back to typical conditions.
This analysis uses dataset usc-lander / internet_address_survey_reprobing_it50j, available for research use from PREDICT, or by request from us if PREDICT access is not possible.
This animation was first shown at the Dec. 2014 DHS Cyber Security Division R&D Showcase and Technical Workshop as part of the talk “Towards Understanding Internet Reliability” given by John Heidemann. This work was supported by DHS, most recently through the LACREND project.