We have released a new technical report “Assessing Co-Locality of IP Blocks”, CSU TR15-103, available at http://www.cs.colostate.edu/TechReports/Reports/2015/tr15-103.pdf.
From the abstract:
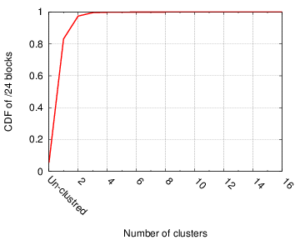
Many IP Geolocation services and applications assume that all IP addresses with the same /24 IPv4 prefix (a /24 block) are in the same location. For blocks that contain addresses in very different locations (such blocks identifying network backbones), this assumption can result in large geolocation error. This paper evaluates this assumption using a large dataset of 1.41M /24 blocks extracted from a delay measurements dataset for the entire
responsive IPv4 address space. We use hierarchal clustering to find clusters of IP addresses with similar observed delay measurements within /24 blocks. Blocks with multiple clusters often span different geographic locations. We evaluate this claim against two ground-truth datasets, confirming that 93% of identified multi-cluster blocks are true positives with multiple locations, while only 13% of blocks identified as single-cluster appear to be multi-location in ground truth. Applying the clustering process to the whole dataset suggests that about 17% (247K) of blocks are likely multi-location.
This work is by Manaf Gharaibeh, Han Zhang, Christos Papadopoulos (Colorado State University), and John Heidemann (USC/ISI). The datasets used in this work are new analysis of an existing geolocation dataset as collected by Hu et al. (http://www.isi.edu/~johnh/PAPERS/Hu12a.pdf). These source datasets are available upon request from http://www.predict.org and via our website, and we expect trial datasets in our new work to also be available there and through PREDICT by the end of 2015.
![Estimated impact on user QoE in four cable cut incidents (Figure 13 from [Cai13c])](http://ant.isi.edu/blog/wp-content/uploads/2013/12/qoe_play_time_350k_vod_3d_all.png)